







1. 概述
面部识别系统的开发极大地推动了计算机视觉领域的发展。如今,人们正在积极开发多模态系统,将多种生物识别特征高效、有效地结合起来。
本文介绍了一种名为 IdentiFace 的多模态人脸识别系统。该系统利用基于 VGG-16 架构的模型,将人脸识别与性别、脸型和情绪等重要生物特征信息结合起来,但不同子系统之间略有改动。
在从 FERET 数据库收集的数据上,性别识别准确率达到 99.2%,在作者的数据集上达到 99.4%,在公共数据集上达到 95.15%。在脸形识别方面,作者使用名人脸形数据集取得了 88.03% 的测试准确率;在情绪识别方面,作者使用 FER2013 数据集取得了 66.13% 的测试准确率。这表明性别识别任务相对容易,而面部形状和情感识别任务则容易在相似类别之间产生混淆。
IdentiFace "多模态面部识别系统可应用于安全、监控和个人身份识别领域。通过利用面部特征,可以实现更高效、更准确的生物识别。
论文地址:https://arxiv.org/ftp/arxiv/papers/2401/2401.01227.pdf
源码地址:https://github.com/MahmoudRabea13/IdentiFace
2. 数据集
本节将介绍每项任务所使用的数据集。首先,在人脸识别方面,使用了 NIST 的 "Colour FERET"数据集。该数据集包含 994 人的 11,338 张人脸图像。该数据集包含 13 种不同的人脸方向,每种方向都有指定的面部旋转度。此外,一些受试者有戴眼镜和不戴眼镜的图像,另一些受试者则有不同发型的图像。本文使用的是这些图像的压缩版本,图像大小为 256 x 484 像素。之所以选择这个数据集,是因为它的差异很大,有助于模型学习到较高的泛化性能。此外,四位作者本人也作为新对象被添加到数据库中,并在不同场景下进行了测试。
接下来,为了进行性别分类,我们从作者的教师中收集了一个数据集。起初,该数据集由 15 名男性和 8 名女性组成,每张图像都包含多种变化,以增加数据量。然而,后来受试者的数量不断增加,最终将数据量增加到总图像数(133 张男性图像/66 张女性图像),其中男性 31 张,女性 27 张。训练/验证数据没有在收集过程中进行拆分,而是在预处理阶段进行了拆分。为了便于比较,我们还使用了 Kaggle 的 “性别分类数据集”。该数据集的训练数据每类约分为 23,000 张图片,验证数据每类约分为 5,500 张图片。
由于任务的复杂性,需要人工标注,作者无法收集自己的脸型预测数据集,因此使用了脸型数据集,其中包含最受欢迎的脸型数据集–名人脸型。该数据集于 2019 年发布,只包含女性受试者,五个类别(圆形/椭圆形/方形/矩形/心形)各包含 100 张图片。
最后,在情绪识别方面,作者军团最初为这项任务收集了自己的数据集。其中包括 38 名受试者,分为 22 名男性和 16 名女性。每个受试者的每种特定情绪有 7 幅图像,每类有 38 幅图像,共计 266 幅图像。每个类别中的图像都是人工标注的。有些受试者在多个类别中都有相似的面部表情,这使得图像标注和分类过程相对具有挑战性。因此,为了收集一个合适的情感数据集。我们使用了 "FER-2013"数据集。该数据集是公开的,包含 30,000 多张图片,包含七个类别(愤怒/厌恶/恐惧/快乐/悲伤/惊讶/中立)。所有图像均转换为 48x48 灰度图像,所有类别几乎均匀分布。
4 .算法架构
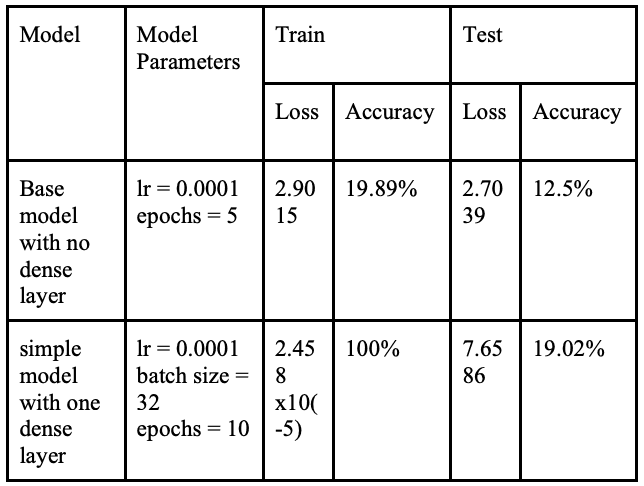
本文构建了一个单一网络,通过在每个任务之间对网络进行微调,该网络可适应多个与人脸相关的任务。VGGNet 架构被用作多模态系统的主网络。本文对基本的 VGG-16 进行了试验,最终将其简化为只有三个主要区块,去掉了最后两个卷积区块。这样做主要是为了减少参数数量和模型的整体复杂性,因为该模型在各种任务中的表现已经很好。下表列出了该模型在层数、输出几何图形和参数数量方面的信息。

在最终编译模型时,采用了以稀疏分类交叉熵为损失函数的亚当优化器。此外,还引入了早期停止功能,以防止模型的过度训练。
此外,人脸识别任务的预处理如下
- 使用 Dlib 基于 CNN 的人脸检测。
- 对识别出的人脸进行裁剪并转换成灰度图像。
- 调整为 128x128 像素。
- 班级数改为 5 个(Hanya、Mahmoud、Nourhan、Sohaila 和其他人)。
除人脸识别外,所有任务都要进行以下预处理
- 使用 Dlib 中的 68 个面部地标进行人脸检测
- 所有检测到的人脸都会被裁剪,没有人脸的图像会被过滤。
- 脸部尺寸调整为 128 x128,并转换为灰度
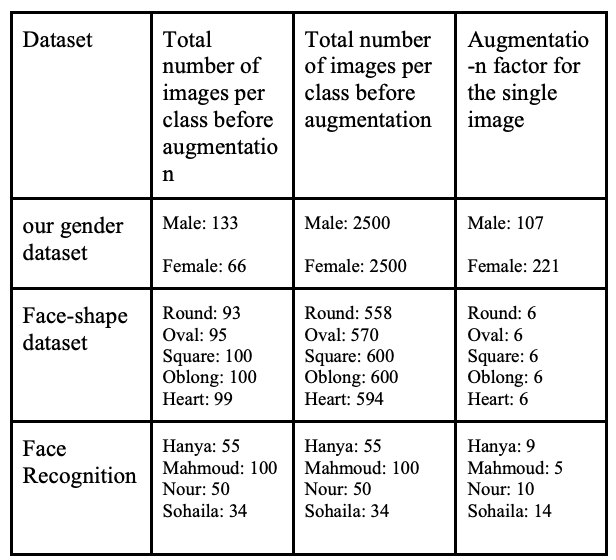
在调整大小后,每个数据集都会按以下方式进行扩展,以确保所有任务的平衡。为确保所有类别的公平分布,仅对不平衡和较小的数据集进行了扩展。
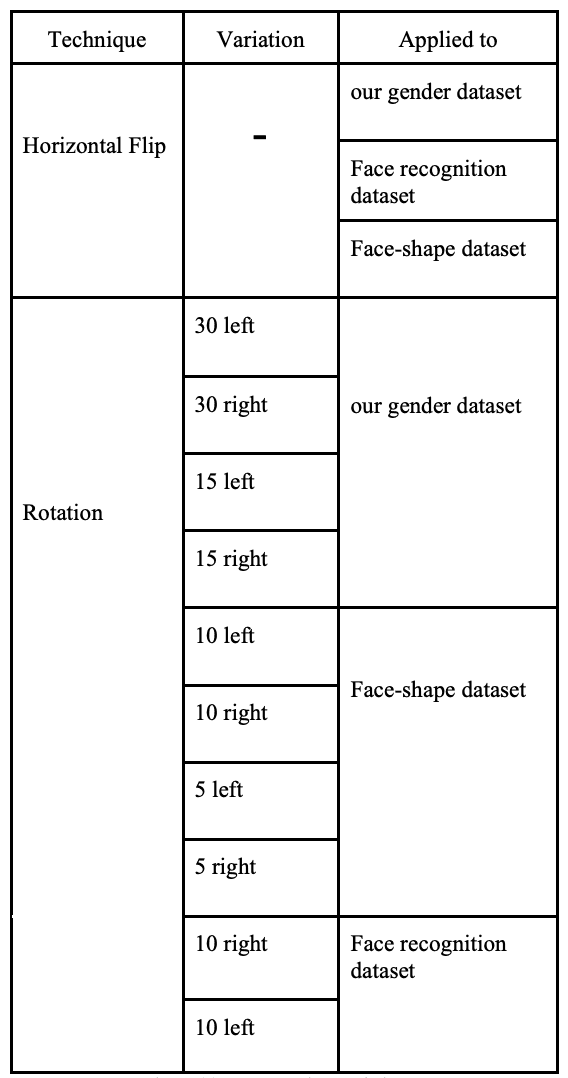
数据扩展后的数据集如下所示。在人脸识别方面,数据集最初包含了来自彩色 FERET 数据集的 11,338 张 "其他 "类图像,但为了避免过度训练,数据集减少到了 500 张。有些数据集,如情感识别和性别识别数据集,不需要进行数据扩展,因为每个类别都有很多图像,而且分布均衡。
5. 试验
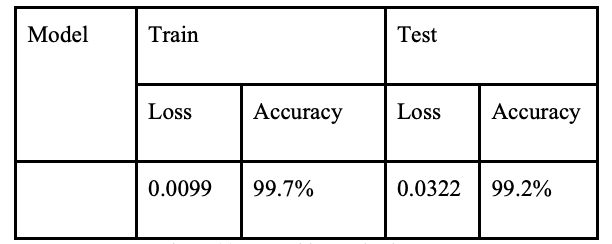
对于人脸识别,数据集的训练与测试比例为 80:20,并使用以下参数训练模型
- 学习率 (lr) = 0.0001
- 批量大小 = 32
- 测试规模 = 0.2
- 历时次数 = 100
结果如下
在性别分类中,任务被视为多类分类,将女性受试者标记为 0,男性受试者标记为 1。以下参数用于训练作者数据集的模型和公共数据集的模型。
- 学习率 (lr) = 0.0001
- 批次大小 = 128
- 测试规模 = 0.2
结果如下
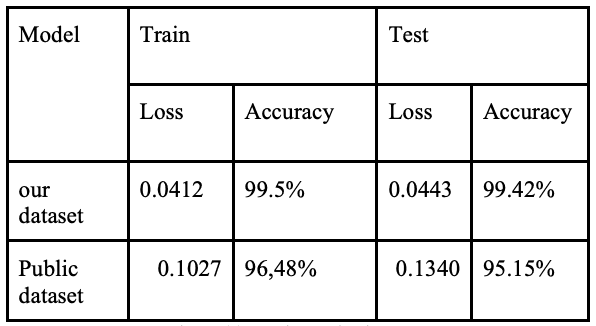
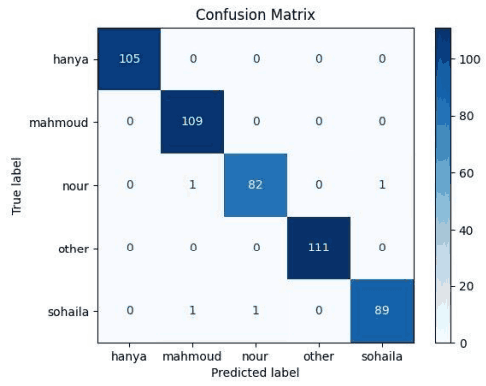
下图是作者绘制的数据集混淆矩阵图。
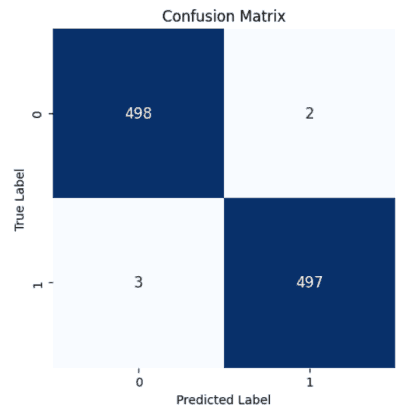
下图显示了数据集与公共数据集的混淆矩阵。
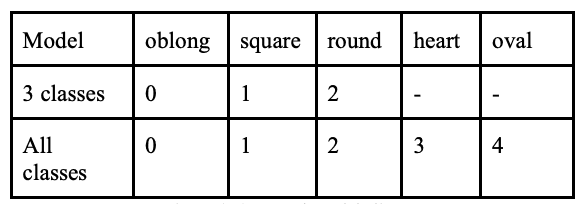
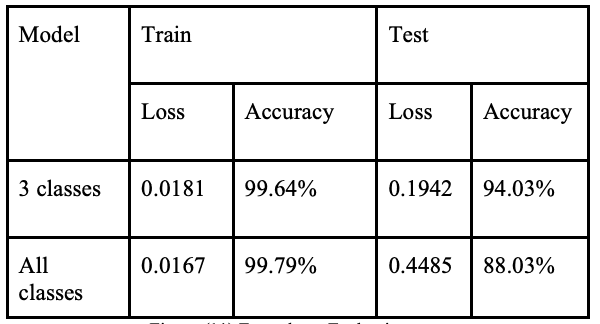
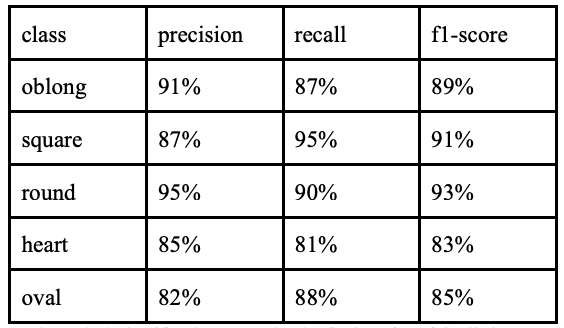
在脸型预测中,我们尝试了两种不同的模型来完成这项任务:一种是针对所有类别的模型,另一种是只针对三个类别(长方形/正方形/圆形)的模型。这样做的目的是为了观察模型在类别重叠最少的情况下是如何工作的,并与其他包含所有类别的模型进行比较。
- 学习率 (lr) = 0.0001
- 批次大小 = 128
- 测试规模 = 0.2
标签如下
结果如下
支持向量机(SVM)和卷积神经网络(CNN)已被用于情绪识别。支持向量机(SVM)的结果如下。
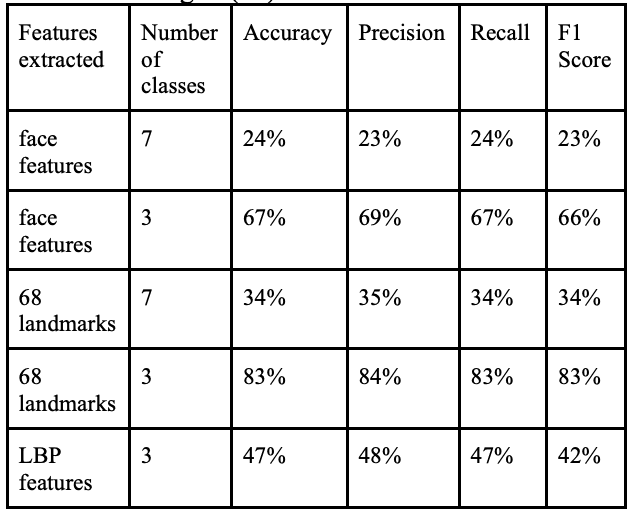
卷积神经网络(CNN)的结果如下。
为了实现结果的可视化,正在开发一种名为 "IdentiFace "的多模式面部生物识别系统,作为基于 Pyside 的桌面应用程序。它可以同时在线和离线进行面部生物识别。

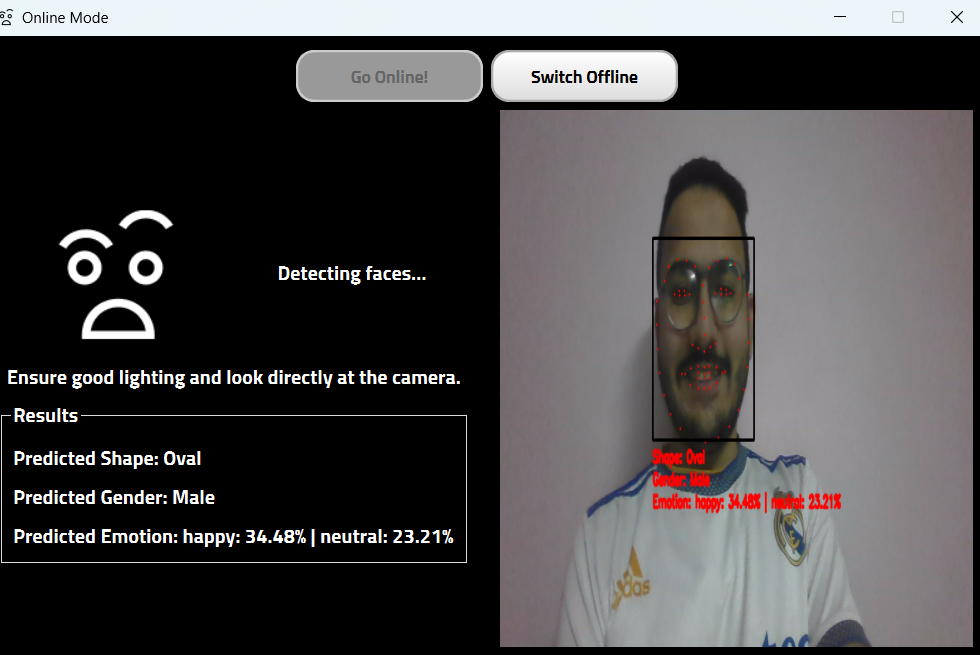
6.总结
我们尝试了不同的方法,并在每项任务中使用了我们自己的数据集以及其他公开可用的数据集,包括人脸识别、性别分类、人脸形状确定和情感识别。我们还选择了 VGGNet 模型,因为它在使用这些数据集的所有任务中表现最佳。此外,我们还将所有表现最佳的模型结合起来,开发了一个名为 IdentiFace 的多模态面部生物识别系统。该系统集成了人脸识别、性别分类、面部形状确定和情感识别于一体。



















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











