







概述
论文地址:https://arxiv.org/pdf/1409.1556.pdf
这项研究探讨了卷积网络深度对图像识别准确性的影响。重要的是,对具有小型卷积滤波器的网络进行的评估表明,具有 16-19 个权重层的深度网络的性能优于传统配置。这些结果使得该模型在2014年ImageNet挑战赛中取得了成功,并在其他数据集上表现出色。研究人员的目标是向公众提供两个最有效的 ConvNet 模型,以促进深度视觉表示方面的研究。
导言
卷积网络(ConvNet)最近已成功用于大规模图像识别。这归功于大型图像数据集和高性能计算系统的进步。特别是,ImageNet 竞赛推动了视觉识别技术的进步。卷积网络正变得越来越普遍,人们也尝试了许多改进方法。本研究表明,卷积网络的深度非常重要,并提出了一种使用小型滤波器构建深度网络的方法。因此,构建的网络具有很高的准确性,其性能可应用于其他数据集。最后,我们向公众提供了一个最先进的模型,有望推动相关研究的发展。
建筑学
在 ConvNet 训练过程中,输入是固定大小的 224 x 224 RGB 图像,唯一的预处理是减去每个像素的平均 RGB 值。卷积层中使用了一个小型 3×3 过滤器,步距为 1 像素。空间池化由最大池化层执行。卷积层之后是三个全连接层,最后一个是用于 ILSVRC 分类的 softmax 层。所有隐藏层都具有 ReLU 非线性,网络不包括局部响应归一化。
配置
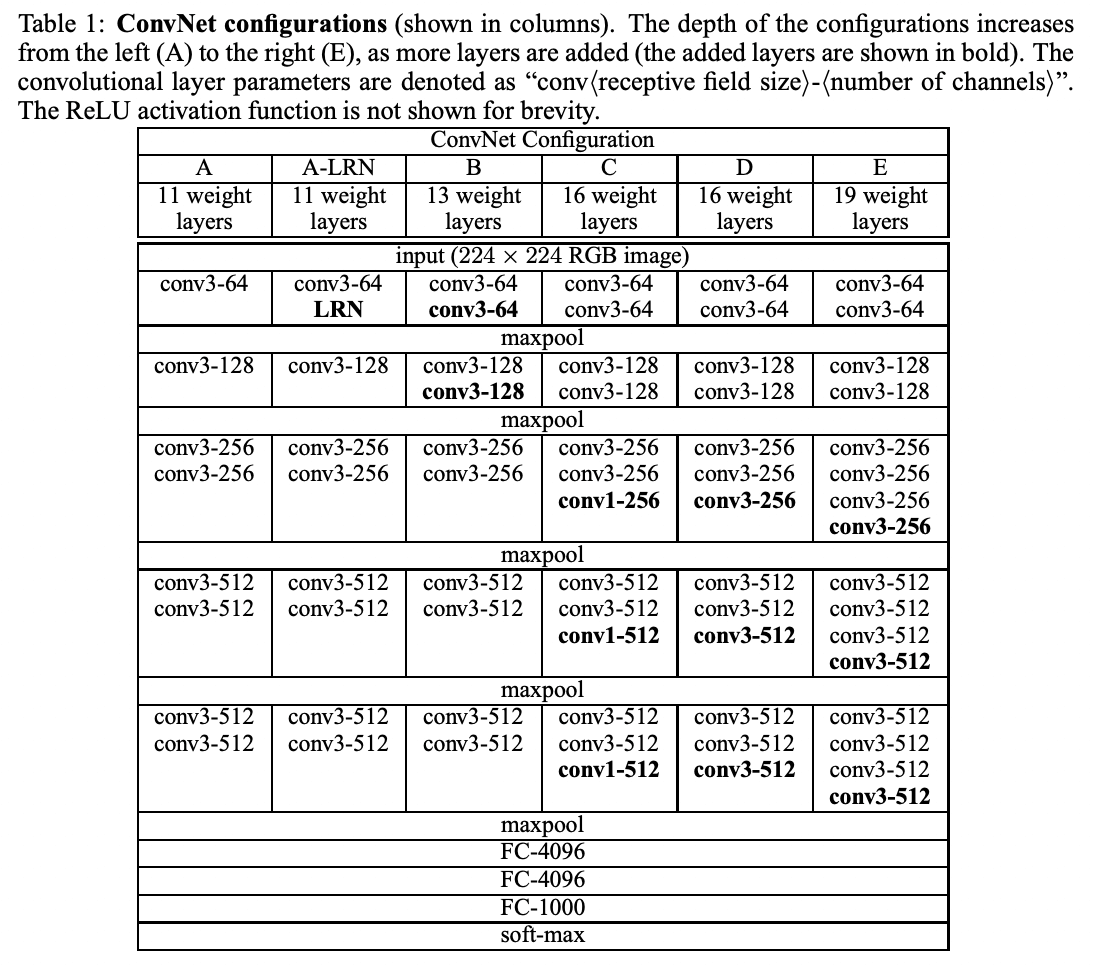
本文评估了五种卷积网络(ConvNet)配置模型(A 至 E)。这些模型基于一般设计,深度不同(A 为 11 层,E 为 19 层)。权重层数和层宽随网络深度而变化,第一层从 64 开始,每增加一个最大池化层,权重层数和层宽就增加 2 倍,最终达到 512。

表 2 列出了每种配置的参数数量。 尽管深度较大,但网络中的权重层数并不比变换较大的较浅网络中的权重层数多。
讨论
本研究对卷积网络(ConvNet)进行了重新配置,通过使用小型 3×3 过滤器而不是传统的大型感受野来提高性能。这样就能引入非线性整流层并减少参数。较小滤波器的引入提高了决策函数的可辨别性,1×1 卷积也改善了非线性。这比以前的方法更有效,在更深的网络中性能更高。
分类框架
训练
在本研究中,使用了带动量的迷你批次梯度下降法来训练 ConvNet,批次大小为 256,动量设置为 0.9。权重衰减和丢弃用于规范化,学习率逐步降低。初始权重从浅层模型开始设置,在训练深层结构时对某些层进行初始化。对图像进行随机裁剪,并添加水平翻转和 RGB 颜色偏移以增强训练集。
图像大小
本研究尝试了两种方法,一种是将 S 设置为代表 ConvNet 训练图像最小边缘的比例,另一种是将 S 设置为固定比例或随机比例。首先,模型在两个固定比例(S=256 和 S=384)下进行训练。其次,在多尺度训练中,每幅图像都被随机重新缩放,以便识别各种尺度的物体。最后,在 S=384 下训练的模型基础上建立多尺度模型,并通过随机缩放进行微调。
测试
在测试过程中,训练好的 ConvNet 对输入图像进行各向同性重缩放,然后将网络密集地应用到重缩放的测试图像上。这样,整个图像上就会出现一个类得分图,最终得出类得分。测试集被水平翻转,原始图像和翻转图像的结果取平均值。全卷积网络适用于整个图像,无需对每种作物进行重新计算,从而提高了测试效率。我们也考虑过使用多作物,但认为增加的计算时间并不能证明准确率的提高是合理的。
实施细节
该实现源自 C++ Caffe 工具箱,可在多个 GPU 上进行训练和评估。多 GPU 训练使用数据并行性,在每个 GPU 上处理批处理,计算梯度,最后求平均值。这样得出的结果与在单个 GPU 上进行的训练结果相当。在我们的实验中,我们使用了一个配备四个英伟达™(NVIDIA®)Titan Black GPU的系统,训练耗时两到三周,比现成的4GPU系统快3.75倍。
分类实验
数据集
本节展示了 ConvNet 架构在 ILSVRC-2012 数据集上取得的图像分类结果。该数据集包含 1000 类图像,分为三个集:训练集、验证集和测试集。分类性能通过两个指标进行评估:前 1 名错误和前 5 名错误,前者表示错误分类图像的百分比,后者表示在前 5 名预测中不包含正确答案的图像的百分比。
单一量表评估
首先,使用上一节所述的层配置,在单一尺度上评估各个 ConvNet 模型的性能。对于固定 S,Q = S;对于抖动 S∈[Smin,Smax],Q = 0.5(Smin+Smax)。 结果如表 3 所示。
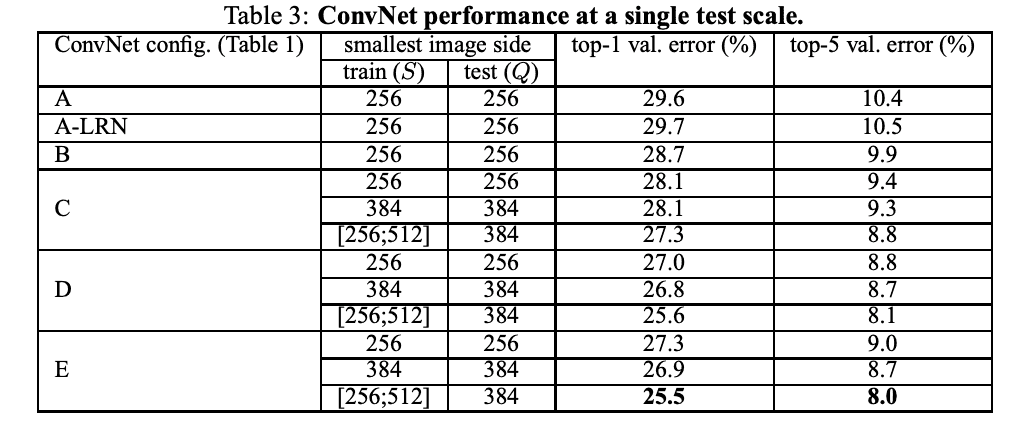
比较卷积神经网络(ConvNet)各种配置的实验结果表明,有无归一化层和深度的增加都会影响分类误差。误差随着深度的增加而减小,非线性变换和空间上下文捕捉也很重要。研究还表明,深度模型对大型数据集也有好处,具有小滤波器的深度网络表现更好。训练过程中的尺度抖动也很有效,有助于获得多尺度图像统计数据。
多阶段评估
在对 ConvNet 模型进行评估时,研究了测试过程中尺度抖动的影响。该技术包括将测试图像重新缩放为不同尺度,然后运行模型计算类的后验均值。为了考虑到训练和测试尺度不匹配对性能的潜在影响,在训练过程中由于尺度抖动,以固定尺度训练的模型在接近的尺寸下进行评估,并同时在大范围的尺度下进行测试。
结果表明,测试时的尺度抖动比在单一尺度下评估同一模型更能提高性能。最深的配置(D 和 E)显示出最好的性能,表明比例抖动比使用固定的最小边 S 进行训练更有益。
评估多种作物
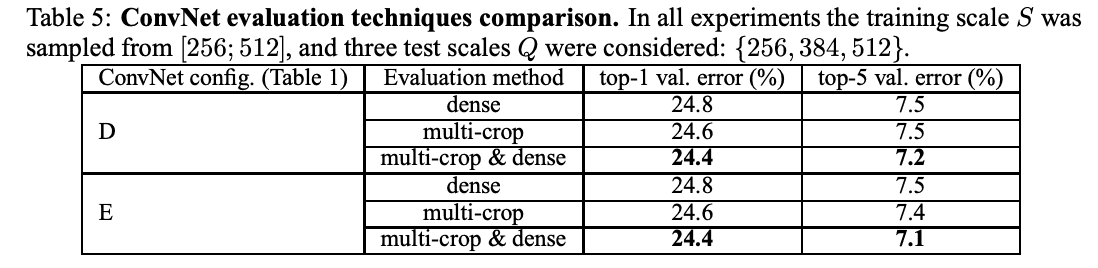
表 5 比较了高密度 ConvNet 评估和多作物评估,并通过平均 softmax 输出检验了两种方法的互补性。当使用多作物时,性能略好,而两者的组合则优于对方。这被认为是由于处理了不同的卷积边界条件。
COMBNET 融合

在本实验中,不同 ConvNet 模型的输出被组合在一起,通过互补来提高性能。结合不同模型后,ILSVRC 测试误差为 7.3%。仅将两个最佳多尺度模型组合起来,误差就降低到了 6.8%,而最佳单一模型的误差为 7.1%。
与最新技术的比较
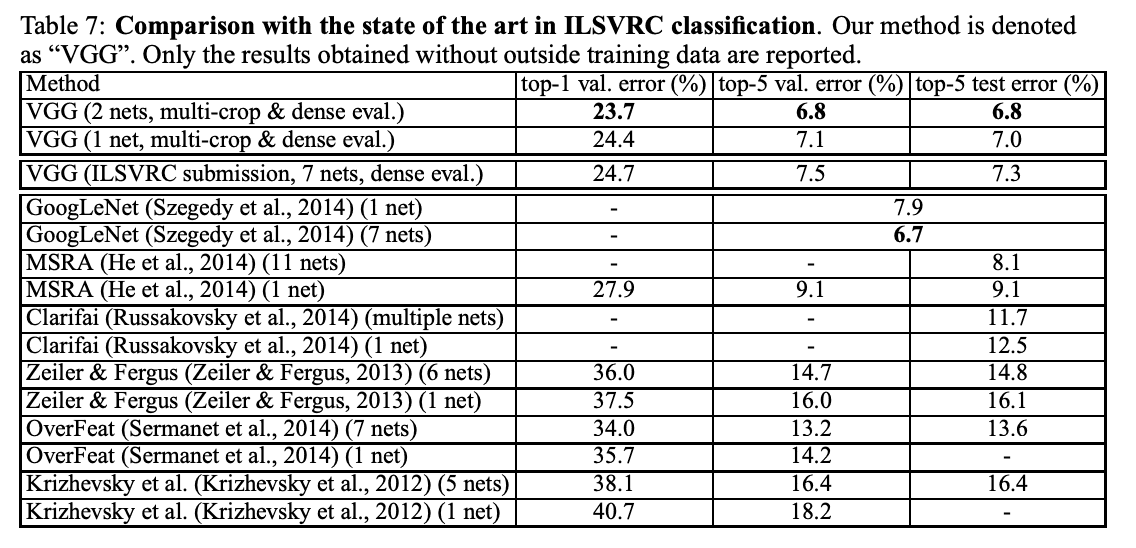
在 ILSVRC-2014 的分类任务中,作者的深度 ConvNet 明显优于上一代模型,使用七个模型的集合将错误率降低到 6.8%。这使得深度 ConvNet 在 ILSVRC-2012 和 ILSVRC-2013 比赛中取得了最佳成绩,大大超过了竞争对手的参赛作品。特别是,两个模型的组合取得了最佳成绩,与许多其他模型相比,它以更少的资源实现了更高的性能。
结论
该研究评估了大规模图像分类中的深度卷积网络(最多 19 层)。 使用传统的 ConvNet 架构,在 ImageNet Challenge 数据集上取得了最先进的性能,表明随着深度的增加,表示深度有助于提高分类准确性。该模型还适用于广泛的任务和数据集,其性能不亚于或优于基于浅层图像表征的复杂识别管道。这再次证明了深度在视觉表示中的重要性。
















 3172
3172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











