







研究背景
本研究旨在建立一种基于眼底图像的深度学习的青光眼自动诊断算法。
青光眼是一种眼压升高导致负责向大脑传递信息的神经纤维收缩的疾病,造成视神经的损伤–这些症状可导致永久性失明和极度的视野缺损。在这种疾病中,周围的视野缺损会发生,而疾病早期的主观症状却很少。
此外,由于目前的医疗手段难以恢复视神经,一旦病情严重,事后要改善就非常困难–因此,鉴于改善预后,早期发现和预防非常重要。另一方面,这些诊断需要专业的知识–高度专业化的培训和知识–并被认为是没有经验的人–即病人和居民难以评估的。
此外,青光眼的评估方法依赖于临床专业知识,很大一部分手工工作是由眼科医生使用裂隙灯生物显微镜完成的–这可能导致检查者之间的高度差异、误诊和临床信息的浪费。
因此,需要一种早期诊断青光眼的新方法–一种不太依赖专业技术的方法。在此背景下,本研究旨在利用CNN建立一个青光眼自动诊断算法。在构建过程中,该模型在四个不同的数据集上进行训练,以提高模型的通用性。
什么是青光眼?
首先,对本研究的分析对象–青光眼进行了概述。
青光眼是一种眼内压升高导致视神经受损的疾病,导致视野变窄,最终丧失视力。发生的频率往往随着年龄的增长而增加,40岁以上的人有5%,60岁以上的人有10%以上,发生的原因目前还不清楚。
据报道,由于眼内压升高,视神经一旦坏死就很难恢复;另一方面,早期发现和早期干预很重要,因为通过早期发现和适当的治疗,有可能保持视野和视力。
此外,眼压在大幅升高之前不会引起明显的症状,此外,在许多情况下,双眼的视野缩小并不被注意,所以病情的发展往往没有任何主观症状。
技术
本节描述了本研究中的拟议模型–见下图。
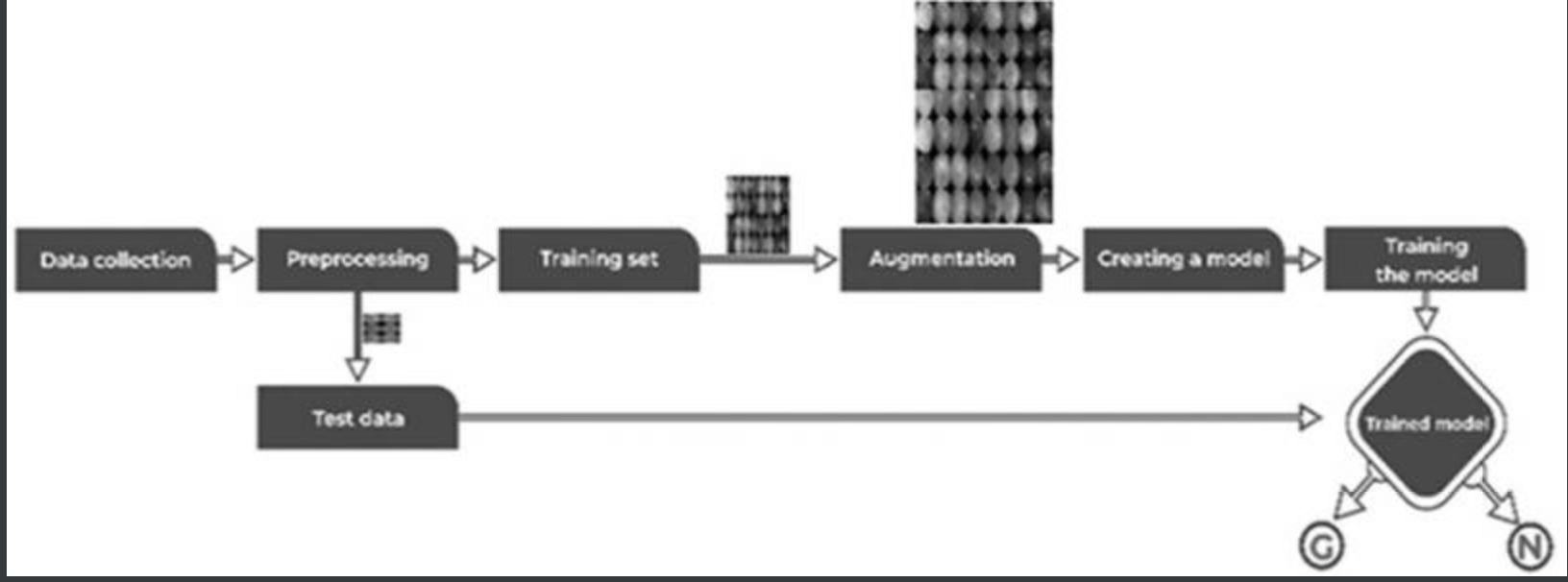

训练数据集包括1113张不同种族、年龄组和光照度的眼底图像:为了训练,图像被预处理成通用的格式和尺寸:所有图像被调整为3000 x 2000像素,并使用OpenCV对颜色和亮度进行归一化处理;图像被缩小为512 x512像素。数据集也被随机分为三部分:70%–462张正常图像和317张青光眼图像–用于训练,20%–132张正常图像和88张青光眼图像–用于验证,其余10%–66张正常图像和48张青光眼图像。%–66张正常和48张青光眼–用于测试。
在CNN模型的结构中–见下文–它是基于10个卷积层和3个完全耦合的密集层构建的,以归一化图像作为输入。除最后一层外,它对所有耦合层和卷积层都使用了RELU,并利用SoftMax作为激活函数。数据平衡和增强等正则化也被用于开发一个高效和成功的DL模型–特别是对于医疗数据,因为由于注释成本的原因,很难准备一个大型的标记数据集、这样的策略也被考虑在内。
在所提出的模型中,应用了一种数据平衡方法–合成少数人过度采样技术–来生成一个合成样本,并进行平衡以匹配正常和青光眼图像:结果,生成并训练了12012张眼底图像。亚当优化器被用作优化功能,默认的学习率为0.001,批次大小为32。分类交叉熵被应用于损失函数以计算误差。
结果
本节介绍了评估情况。
以特异性、敏感性、准确性和ROC曲线下的面积–AUC–为目标,评估模型的性能:敏感性是指青光眼阳性诊断的概率;特异性是指非青光眼患者阳性诊断的概率;准确性是指从诊断中得出的分类结果总体概率。超参数是以8、16、32、64和128以及50个epochs的批量大小进行训练的–见下图:这些曲线表明,所提出的模型没有过度学习–它在新的测试数据上保持相同的预测性能。这些曲线显示,建议的模型没有过度学习–它在新的测试数据上保持相同的预测性能。当批量大小设置为32时,准确率为99.26%。
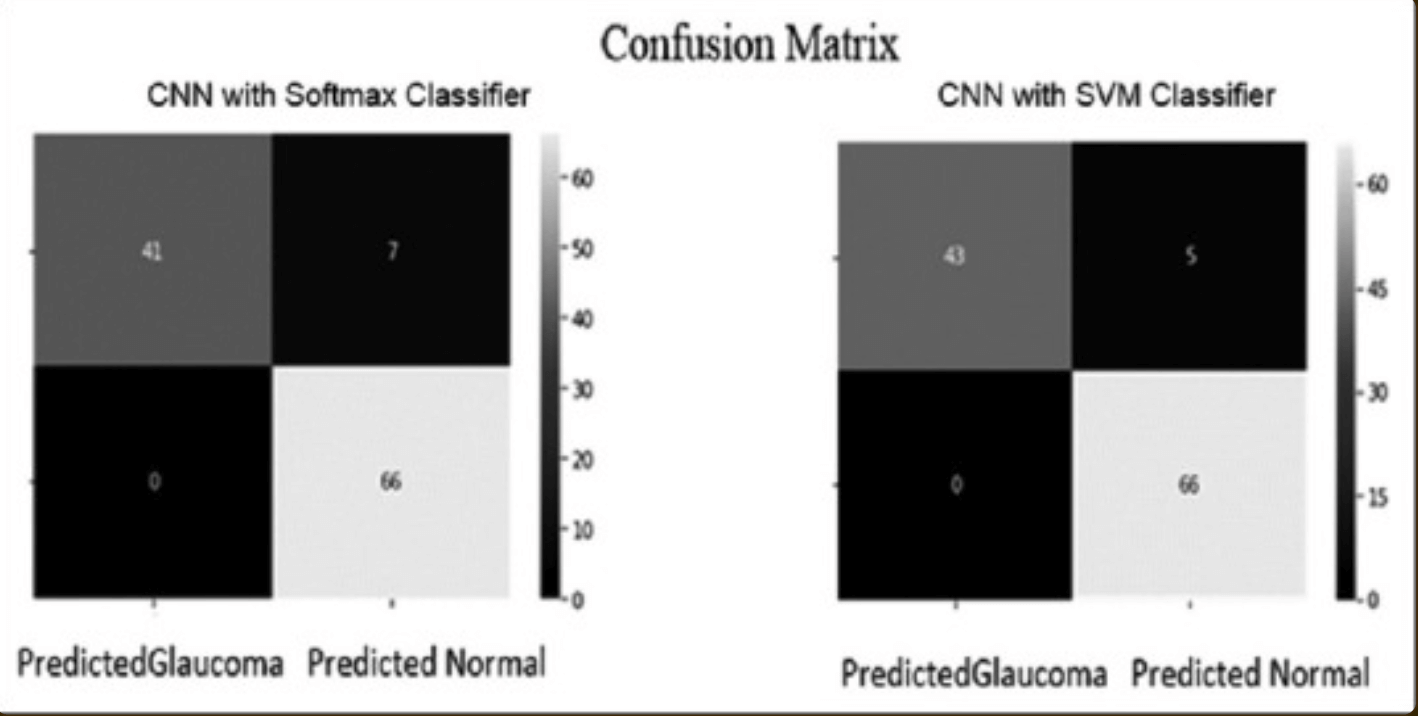
从分类模型中的混淆矩阵–一个总结了由于真阳性、假阳性、真阴性和假阴性导致的预测的正确性或不正确性的表格–比较了使用SoftMax和SVM分类器的性能:结果表明,使用SVM分类器的CNNs胜过使用SoftMax分类器的CNN–见下表。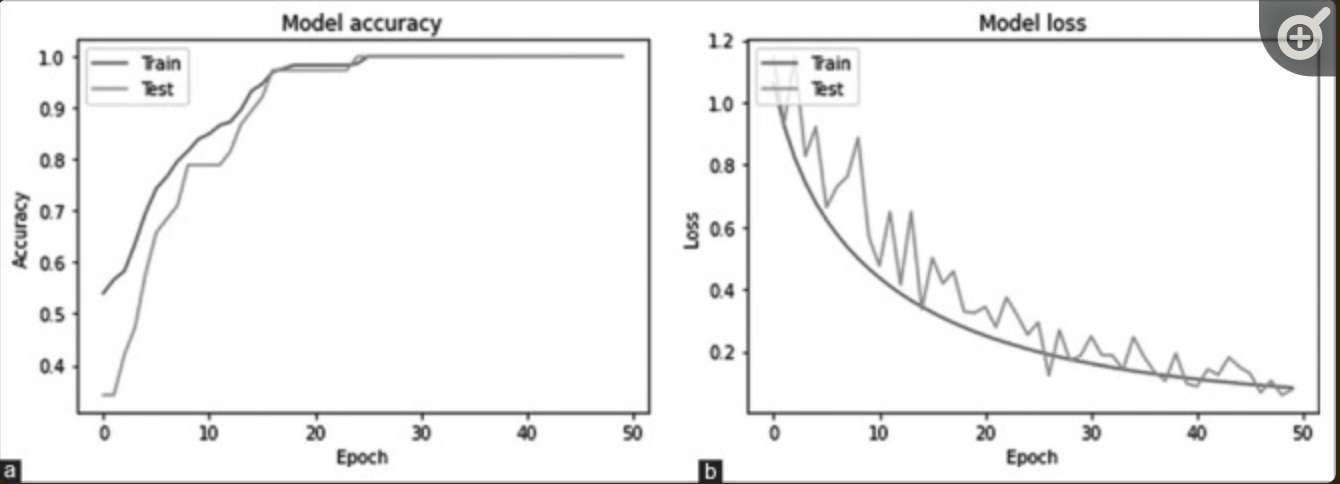
总结
这项研究旨在建立一个基于眼底图像的青光眼自动诊断模型。在建立该模型时,使用了由1113张视网膜图像组成的多个数据集,其中约70%的数据集用于训练,20%用于验证,10%用于测试:114张测试图像–48张青光眼图像和66张正常图像。- 数据被使用。利用深度学习的模型的评估性能如下:对于SoftMax分类器,93.86%的准确性,100%的特异性,85.42%的敏感性,AUC 0.927;对于SVM分类器,95.61%的准确性,89.58%的敏感性,100%的特异性,AUC 0.948。从这些结果来看、表明有可能生成一个青光眼的分类模型,其准确度等于或优于专家的分类。
这项研究的一个可能的优势是,虽然它由一个CNN组成的简单算法,但它能够以较高的准确性检测出正常的病例:SoftMax和SVM分类器实现了较高的特异性。此外,89.58%的阳性病例得到了分类。这表明,青光眼和正常受试者–尤其是健康受试者–都能以高准确率进行分类。
另一方面,挑战包括:注释的成本;深度学习的黑箱性质。在建立具有高估计精度的模型时,需要准备大量的注释–标记的–视网膜图像的数据集–这些注释目前需要专家诊断、从图像的标记来看,训练成本往往很高。
可能的解决方案包括使用预学习模型,如过渡学习,或引入适合少数标签的算法,如弱监督学习;后者的挑战在于深度学习的黑箱性质–模型使用什么标准来做决定- 是很容易不清楚的。一个可能的解决方案是利用热图,如Grad-CAM,并利用在图像中总是澄清模型的诊断标准并赋予它们临床意义。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











