







介绍
论文地址:https://github.com/microsoft/bitblas
源码地址:https://github.com/microsoft/bitblas
与大型语言模型(LLMs)相比,小型语言模型(SLMs)正逐渐成为人们关注的焦点。
大规模语言模型在大量模型参数和大型数据集的基础上进行训练,其回答问题的能力将公众对人工智能的期望提升到了一个新的高度。然而,要对大规模语言模型进行训练和推理,需要超高规格的计算机。因此,大多数人通过云服务器将 LLM 作为一项服务使用,而不是在内部(在自己的建筑物中计算)或在边缘(在智能手机和其他设备中计算)使用。
对于企业来说,通过云服务器使用服务需要采取措施应对安全风险,如账户管理、预算应用和使用此类服务的信息泄露。这是一大绊脚石,尤其是对于希望利用自身大规模数据的公司而言。
小规模语言模型在消除这些桎梏,使每个人都能更容易地受益于人工智能方面备受关注。与大规模语言模型相比,小规模语言模型可以在计算、内存使用和功耗方面降低硬件要求标准。
因此,小规模语言模型可以降低对硬件的要求,从而从人工智能中获益,并有望促进其在内部和边缘的使用。这是加速人工智能民主化的一个趋势。
本文介绍的 1 位 LLM(准确地说,是 1.58 位 LLM;1.58 位 LLM 是作为 1 位 LLM 的后续提出的)是更具挑战性的小规模语言模型之一。
在大规模语言建模中,提高硬件要求的是模型参数的数量。更具体地说,问题在于模型参数数量 x 模型参数精度。
模型参数精度是指一个数字所表示的级数。例如,三位数的圆周率是 3.14,但一位数的圆周率是 3。三位数的圆周率是从 9.99 到 0.00,分 1000 步;一位数的圆周率是从 0 到 9,分 10 步,这意味着圆周率的精度约为其精度的 1/100。这可视为数值精度的约 1/100。
在这里,你如何比较一位数和三位数的计算量、内存使用量和耗电量?位数较少的情况,即把圆周率看作 3,更容易计算和记忆。你还可以感觉到,计算时消耗的热量更少。
在计算机世界中,模型参数的精确度是用比特来表示的,比特是二进制的位数,因为用二进制数来思考问题是最基本的,在二进制数中,位数达到 2 就向前推进,而不是用十进制数来思考问题,在十进制数中,位数达到 10 就向前推进。
本文使用-1、0 和 1 三个数值来表示模型参数。这仅为 1.58 位,而迄今为止一般模型参数精度为 16 位(例如,十进制中的 1000 是 10 的三次幂,该值越大,可考虑的位数就越多。同样,3 到 2 的幂是多少?可以换算成 3 的值相当于二进制的几位数,答案是 1.58)。
在这样的模型参数精度下,人们担心 LLM 的响应精度会不会受到影响,但出乎意料的是,结果表明其响应精度与 LLM 相当,而且根据模型参数的数量,三个参数值的响应精度反而更好。
在尽可能保持 LLM 响应精度的同时降低模型参数精度的技术被称为量化技术,并已得到研究。
接下来,我们将详细介绍本文提出的方法 BitNet b1.58,以及评估结果。
BitNet b1.58 的优势
图 1 显示了拟议的 BitNet b1.58 与传统 LLM 的性价比对比。
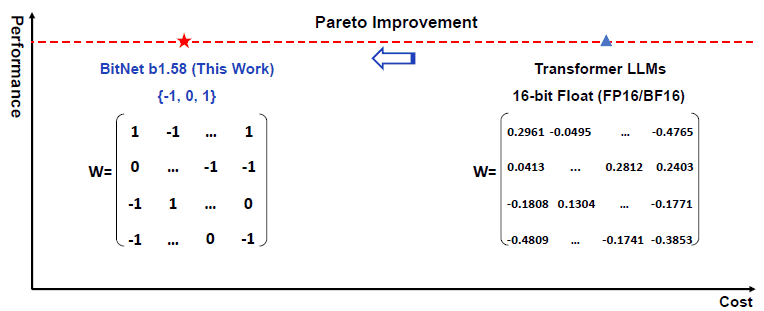
图 1:BitNet b1.58 的成本性能比较
BitNet b1.58 的特点是,模型参数(即所谓的神经网络权重)可以是三种值之一:-1、0 或 1,如图 1 左侧 W 所示。
传统的 LLM 权重以 16 位浮点数表示。浮点数以(尾数部分)x(指数部分)幂的形式表示数值,如 2.961 x 10-1。它为尾数部分、指数部分和符号各分配 16 位,可以表示小数,如图 1 右侧变压器 LLM 中的 W 所示。
基本上,计算机配备的算术单元是逐位计算的,每个位都要计算,因此位数越多,计算成本就越高,存储位值的内存成本也会增加。如果准备了大量算术单元以实现并行计算,计算时间就会缩短,但能耗却会增加。
如果模型参数数量较多,在使用模型参数值进行推理时,从内存中传输大量模型参数值信息所需的时间本身就是推理时间(LLM 响应输入所需的时间)增加的一个因素。
因此,图 1 的横轴表明,通过将模型参数精度降低到三个值,BitNet b1.58可以比Transformer LLM降低成本。
在性能方面,BitNet b1.58 声称与前一版本相当。
因此,如果在性能和成本这两个轴上与传统 LLM 进行比较,可以认为它们在任何一个轴上都不比传统 LLM 差,但至少在一个轴上优于传统 LLM,这里指的是成本(帕累托改进)。
BitNet b1.58 所需的操作如图 2 所示。
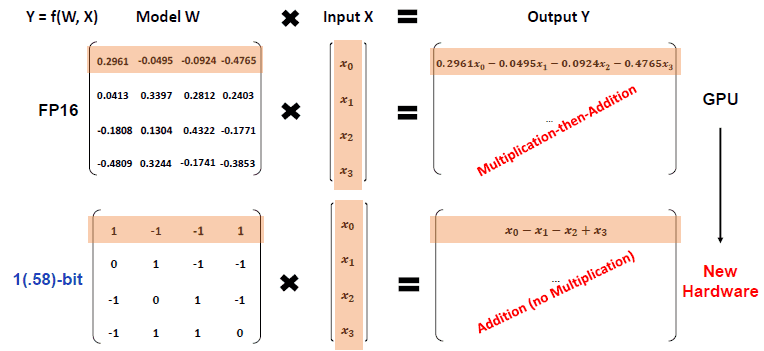
图 2:BitNet b1.58 所需的操作
传统上,需要对模型参数和输入进行乘法(Multiplication)和加法(Addition)运算。
相比之下,BitNet b1.58 只需要加法。这意味着需要更简单的计算。
传统的 GPU 可以加速产生大量乘法和加法或所谓乘积之和的矩阵运算,而新的 BitNet b1.58 应该可以加速加法运算(以及在输入为 0 时设置为 0、在输入为 -1 时设置为负号、在输入为 1 时设置为正号的运算)。
BitNet b1.58 技术点
BitNet b1.58 基于 BitNet。
量化方案有两种:一种是在学习后降低模型参数的精确度,另一种是在学习时意识到要降低模型参数的精确度。
前者将降低模型参数的精度作为一个后处理步骤,其方便之处在于易于应用于现有的模型,但缺点是可能会降低模型的性能。
据说后者可以减少模型的性能下降,但其缺点是增加了训练的计算成本,从而降低了模型参数的准确性。
BitNet 是以后者量化为目的的学习图像。
如果在学习过程中中断了量化过程,例如将连续值舍入为离散值,通常会导致不连续变换,而这种变换是不可分的。
在 BitNet 中,使用的是现有的直通法,即通过传播无微分函数,传播结果的经验法,并在可以计算导数的地方计算导数。使用的是误差反向传播的经验方法。
这些流程在 BitNet b1.58 中也得到了延续。
BitNet 和 BitNet b1.58(这次)的区别在于模型参数值是用 -1,1 的二进制值表示,还是用 -1,0,1 的三进制值表示。
BitNet b1.58保留了 BitNet 的优势,但提供了 BitNet 的额外优势。
-添加 0 以及 1 和 1 是理所当然的,但这样做可以提高模型参数值的表征精度。
加入 0 的另一个意义在于可以进行特征筛选。
在机器学习中,加入一般不必要的特征会对模型的预测性能产生显著的负面影响;加入 0 会直接减少不必要特征的数量。
传统的 BitNet 量化方法
BitNet 采用传统的二进制值 -1 和 1,如果模型参数值大于或等于 0,则转换为 1;如果小于 0,则转换为-1。然而,当前模型参数值的中心可以说是模型参数值的平均值,因此如果中心偏离 0,转换就会出现偏差,误差也会很大。
因此,在减去模型参数值的平均值(经过零点调整后)后,如果大于 0 则转换为1,如果小于 0 则转换为-1。
对于激活函数的量化,[-Q, Q]是通过除以输入矩阵元素的最大绝对值,将数值范围设置为 [-1,1] 并乘以 Q(2 的 n-1 次方,取决于量化到多少位)得到的。如果激活函数是非对称的,例如假设是 Relu 函数,那么 0 就是阈值,因此通过减去最小值,然后应用相同的过程,范围就是 [0,Q]。
在神经网络中,输入与模型参数的乘积之和被计算出来,然后将激活函数应用于输出。在极端情况下,激活函数决定网络中的某个神经元是否会启动,是 0 还是 1,超过阈值的神经元被判定为 1,而未超过阈值的神经元被判定为 0。
因此,我们认为应通过注意阈值来调整范围,因为如果阈值处理不当,可能会出现只输出 0 的极端输出等问题。
拟议的 BitNet 量化方法
建议将模型参数值除以模型参数值的绝对平均值(缩放过程),将该值四舍五入为整数(舍入过程),如果小于-1,则转换为-1,如果大于 1,则转换为 1(剪切过程)。
举例来说,可以按照激活函数的传统量化方法,用最大的绝对值除以最大的绝对值,但如果只有一个值的绝对值非常大,而刻度又是基于这个值,那么只有一个值的绝对值会很大,其他值将被较大的值除以,结果是(虽然有三个值-1、0 和 1可以想象,(三个值中的)一个值会停留在 0 左右。
据设想,BitNet b1.58 采用的方法是,如果数值高于平均值,则按平均值缩放,使其为 +1或 -1,如果低于平均值,则为 0,而超过 -1和 1 的数值则转换为 -1或 1,以较接近者为准。
激活函数的量化与之前相同。不过,过去对于 ReLu 来说,最小值被减去,值的范围被转换为 [0,Q],但为了简化过程,最小值减去过程不包括在内,值的范围始终转换为 [-Q,Q]。目前还不清楚,为什么这次为了简单起见,可以省略零点调整过程,如减去最小值。也许在尝试时并没有出现这样的问题。
评估结果
内存使用量、响应时间和预测精度
图 3 显示了 LLaMA LLM 和 Meta 开发的 BitNet b1.58 LLM 的内存使用量、响应速度和预测精度。
图中显示了模型参数(Size)为 7 亿(7 亿)、13亿(13亿)、30 亿(30 亿)和 39 亿(39 亿)时的 GPU 内存大小(Memory)、响应速度(Latency)和预测误差(PPL)。如表中箭头所示,任何指标都是越小越好。
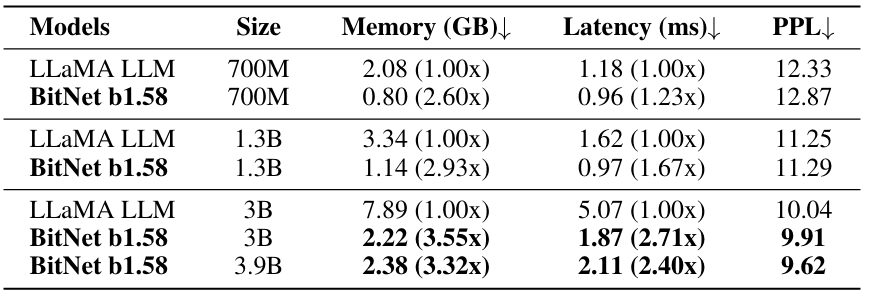
图 3.按模型参数数量计算的内存(GPU 内存大小)、延迟(响应时间)和 PPL(预测误差)。
与 LLaMA LLM 相比,BitNet 的 GPU 内存大小减少了 2.6~3.6 倍,响应时间缩短了 1.23~2.7 倍,预测误差几乎相同。
模型参数数越多,内存使用量、响应时间和预测误差往往越小,当模型参数数为 3B 和 3.9B 时,GPU 内存使用量、响应时间和预测误差均优于 LLaMA LLM。
能耗
图 4 显示了使用 512 个令牌输入的 LLaMA 和 BitNet b1.58 的能源成本比较。
BitNet b1.58 的能源成本比 LLaMA 低 19-41 倍,模型参数数量(模型大小)更多,能耗(能源)更低。
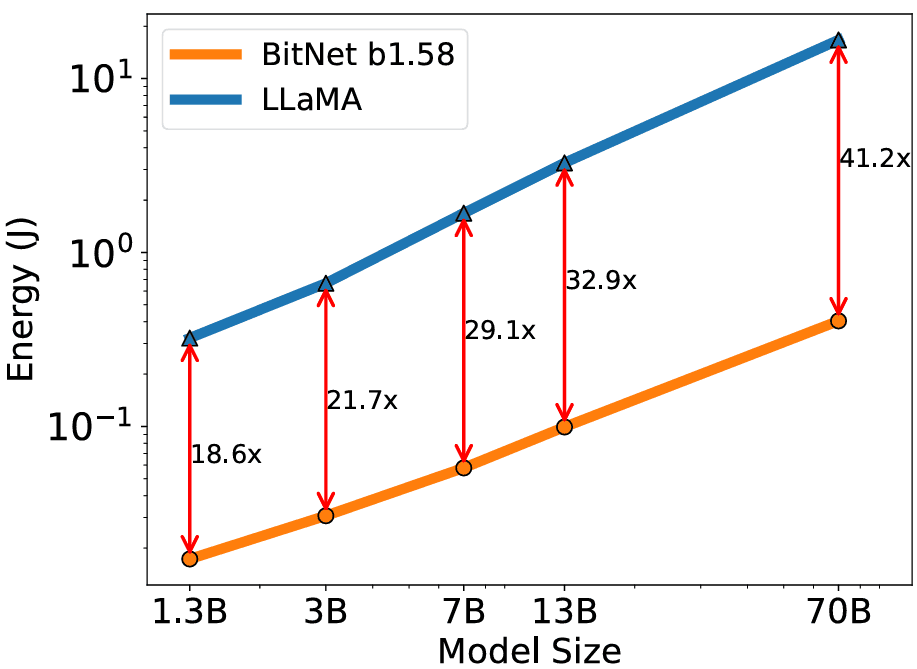
图 4.模型大小(模型参数数量)和能量(能耗)
总结
这篇文章介绍了 BitNet b1.58。
随着模型参数数量的增加,传统的 LLM 可以提高预测性能,但内存使用量、响应时间和能耗也会显著增加。
传统的 LLM 将单个模型参数值表示为 16 位浮点数,因此需要存储模型参数个数 x 16 位信息,模型参数越多,使用的内存就越多,传输这些信息所需的时间就越长,响应时间也就越长,需要进行的计算也就越多,因此能耗也会增加。
为了缓解这一问题,我们引入了一种技术(量化),在尽可能保持 LLM 响应精度的前提下,将模型参数值的精度从 16 位浮点数降低到 1.58 位(-1,0,1 三个值)。BitNet 减少到-1,1 这两个值的方案早已提出,但通过在-1,1 的基础上增加 0,可以获得过滤效果,缩小特征范围,同时保持大多数计算只需加法即可完成的优势,并可实现内存使用量、响应时间和能耗的小幅降低。可以提高 LLM 的预测精度,而只需牺牲少量内存使用、响应时间和能耗。根据模型参数的数量,结果不仅显示出预测精度的小幅下降,而且还显示出相反方向的提高。
与 LLaMA 的比较表明,预测性能可以比以前更好,同时还能减少内存使用量、响应时间和能耗。
论文指出,所提出的方法只能将大部分计算加起来,这意味着可以通过创建不同于 GPU 的新硬晶圆来实现进一步的高速处理和降低能耗。
英伟达的股票目前正吸引着不同寻常的关注,但如果硬件能够有别于 GPU,就有可能颠覆英伟达的垄断地位。也就是说,论文中使用 GPU 对 BitNet b1.58 进行了评估,激活函数是 8 位的,如下所述,因此在所有处理过程中不一定都是 3 值。如果所有处理过程都只有加法,就有可能从根本上改变硬件,但如果仍是乘法,就不太可能有大的改变。
此外,制造商可能乐于被告知有更适合英伟达™(NVIDIA®)的新硬件,因为这给了他们利用英伟达™(NVIDIA®)优势的机会,但我认为普通用户更愿意被告知他们可以使用通用 CPU 或更便宜的硬件进行更快速的计算,而不是被迫购买新硬件。我认为,如果告诉他们可以用通用 CPU 或更便宜的硬件进行高速计算,他们会更高兴,而不是被迫购买新硬件。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











