







概述
论文地址:https://arxiv.org/abs/2404.03653
在文本到图像生成领域,扩散模型近年来取得了巨大成功。然而,提高生成图像与文本提示之间的一致性仍然是一个挑战。
论文指出,扩散模型中文本条件利用不足是对齐的根本原因。论文随后提出了一种新方法 CoMat,通过利用图像捕捉模型来优化生成图像与文本提示之间的对齐。它还引入了一种改进属性和实体之间绑定的方法,以及一个保真模块,以保持生成能力。
实验结果表明,与现有的基线模型相比,所提出的 CoMat 方法能生成与文本条件更加对齐的图像。本文提出了改进文本到图像配准的新见解和有效方法,是对该领域的重要贡献。
相关研究
近年来,人们提出了三种主要方法来改进文本和图像的对齐。
1. 基于注意力机制的方法:这些方法试图通过根据文本条件调整注意力值来改善对齐情况;Attend-and-Excite [6] 和 SynGen [40] 就是这方面的例子。
基于计划的方法:这些方法首先使用语言模型生成布局,然后使用扩散模型生成图像,例如 GLIGEN [28] 和 RP G [59]。
3. 利用图像理解模型进行奖励优化:将 VQA 或图像捕捉模型的输出用于奖励,以优化扩散模型;本文提出的 DreamSync [46] 和 CoMat 就属于这一类。
建议的方法
CoMat 是一种扩散模型微调方法,利用图像-文本概念匹配机制。
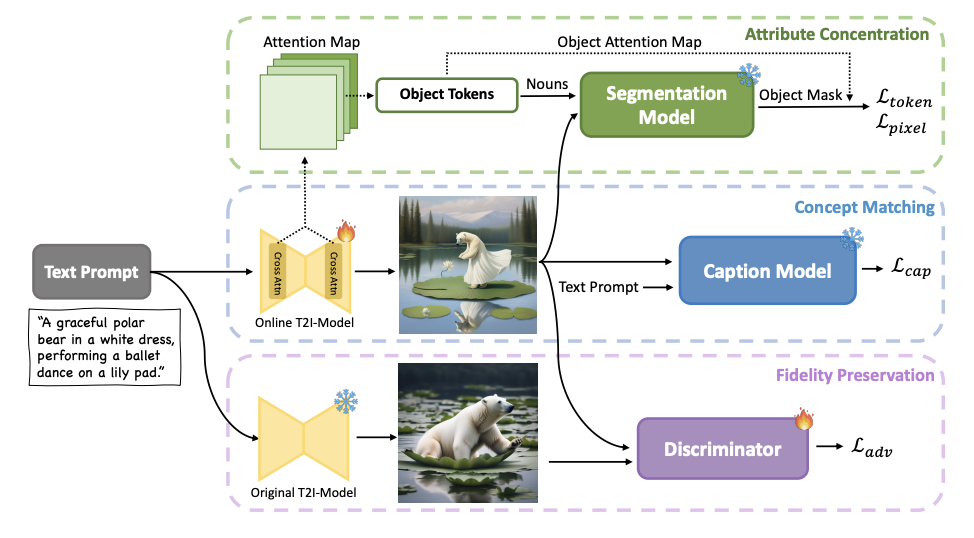
具体流程如下(见上图)。
1. 利用扩散模型根据文本提示生成图像。
2. 将生成的图像输入预先训练好的图像捕捉模型。
3. 在概念匹配模块中,字幕模型输出的文本与原始提示之间的一致性得分是扩散模型的优化目标。
这意味着,如果生成的图像中缺少一个提示概念,字幕模型的输出就会降低,扩散模型就会被诱导生成包含该概念的图像。
更多
4. 属性集中模块还考虑实体及其属性的空间排列。
5. 保真度保持模块引入对抗性损失,并保持原有的生成能力。
这三个模块的组合是 CoMat 的一大特色,可确保生成与文本条件一致的高质量图像。
试验
主要实验设置如下
- 在基础模型方面,我们主要使用了 SDXL [36] - 在图像捕捉模型方面,我们使用了 BLIP [25] - 在训练数据方面,我们使用了 T2I-CompBench [21]、HRS-Bench [3] 和 ABC-6K [15] 中总共约 20 000 条文本提示。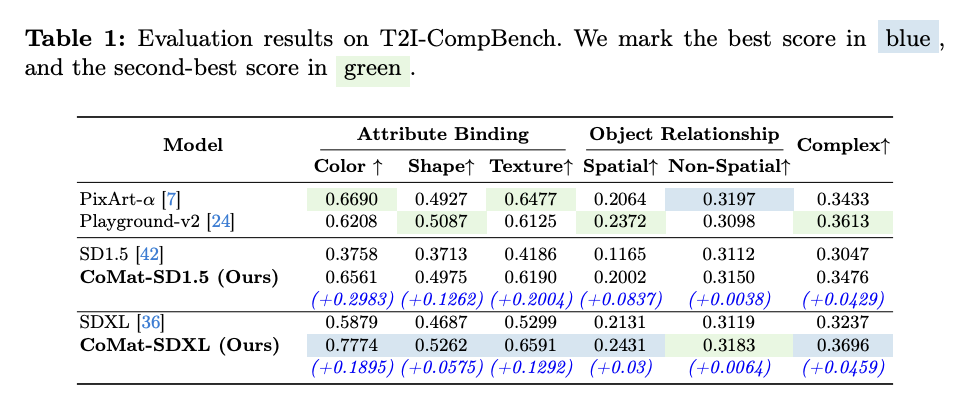 首先,表 1 列出了使用 T2I-CompBench 的定量评估结果。
首先,表 1 列出了使用 T2I-CompBench 的定量评估结果。
- CoMat-SDXL 在属性绑定、对象关系和复杂组合方面都明显优于基线。
- 属性绑定方面的改进尤为明显,显著提高了 0.1895 个百分点。
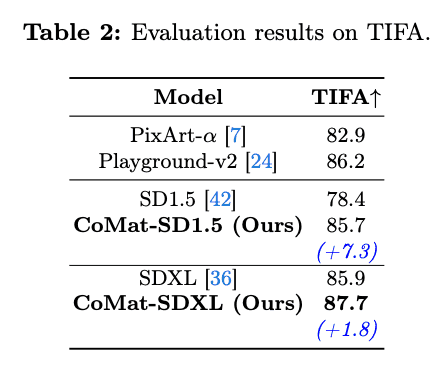 表 2 列出了 TIFA 基准评估结果。
表 2 列出了 TIFA 基准评估结果。
- CoMat-SDXL 也获得了最高的 TIFA 评估分数,提高了 1.8 分。
 此外,图 6 直观展示了实验结果,证明了保真模块的重要性。
此外,图 6 直观展示了实验结果,证明了保真模块的重要性。
- 可以看出,如果没有该模块,生成的图像质量会明显下降。
这些结果证实,所提出的 CoMat 方法可以显著提高文本和图像的对齐度,同时还能保持其生成能力。
结论
论文指出,扩散模型中文本条件利用不足是造成文本与生成图像之间对齐问题的根本原因。随后,论文提出了利用图像捕捉模型的 CoMat 方法,并引入了改进属性与实体之间的绑定和保持生成能力的机制。实验结果表明,与基线模型相比,CoMat 生成的图像能更好地与文本条件对齐。这项研究为文本-图像对齐问题提供了新的见解,并提出了有效的解决方案。
所提出的 CoMat 方法具有端到端微调方法的优势,可与其他方法结合使用。未来,CoMat 的性能可能会通过利用大规模多模态 LLM 得到进一步提高。它还有望开发出更广泛的应用,包括应用于三维领域。文本和图像的对齐是一个重要的问题,希望本文的结果将有助于扩大扩散模型的应用范围。



















 2799
2799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











