







概述
论文地址:https://arxiv.org/pdf/2312.15320
项目地址:https://github.com/WGLab/GestaltMML
据估计,全球约有 6% 的人口受到某种罕见遗传病的影响。根据 Orphanet 和 OMIM 数据库,目前至少有 7000 种不同的罕见遗传疾病。
由于罕见性和广泛的表型多样性,基因诊断具有挑战性,通常需要一个漫长的诊断过程,也被称为 “诊断奥德赛”。被怀疑患有遗传综合征的患者除了需要进行大量的临床评估、影像学检查和实验室检查外,还需要进行基因检测,如核型分析(染色体分型)、染色体微阵列、基因面板、外显子组测序和基因组测序。临床医生需要对许多不同的疾病进行详细的鉴别诊断,这给他们带来了巨大的挑战,因为他们很难确定应该使用哪些诊断测试。
许多遗传性疾病都有面部特征,这可以为诊断提供线索,有助于及时转诊给专科医生或选择适当的基因检测。然而,通过面部特征识别综合症在很大程度上取决于临床医生的面部识别经验。有数以百计的罕见遗传疾病会表现出面部特征,而通过面部特征进行识别并非易事。
最近,计算机视觉技术的进步推动了下一代表型技术(NGP)的发展,该技术可根据患者的二维额面部图像分析和预测罕见遗传疾病。其中一个例子是由 FDNA 公司开发的 DeepGestalt,它使用 CASIA 数据集对深度卷积神经网络(DCNN)进行了预训练,随后使用 17,106 张患者正面面部图像和 216 种疾病数据对其进行了微调。DeepGestalt 已使用多年。然而,DeepGestalt 只涵盖了有限的几种综合症,要涵盖更多的综合症,就需要收集新的图像并重新训练模型。为了解决这个问题,我们推出了 GestaltMatcher。它利用 DeepGestalt 特征层形成一个新的表示空间(临床面部表型空间 - CFPS),以找到患者之间最接近的匹配,包括未知疾病。这样就可以在不改变模型结构的情况下整合新发现的综合症。
然而,仅靠面部成像往往难以提供足够的信息来做出准确诊断。例如,努南综合征(NS)、普拉德-威利综合征(PWS)、西尔弗-鲁塞尔综合征(SRS)和阿尔斯科格-斯科特综合征(ASS)等综合征的共同特征是身材矮小,仅靠面部正面照片是无法捕捉到这些特征的。睡眠障碍、平衡障碍和智力障碍也无法通过面部或其他身体部位的照片有效反映出来。要了解这些特征,还需要更多的数据。
此外,一些研究还探讨了年龄、性别、种族和民族差异如何影响不同疾病和综合征的表现形式和发生频率。由于数据提供、收集和分析过程中的系统性偏见,某些少数群体被误诊或诊断不准确。基于这些事实,我们开发了新的模型来整合面部图像和临床 HPO 术语。
其中一个例子是 “通过图像分析确定外显子组数据的优先次序”(PEDIA),它将序列变异的解释与 DeepGestalt 先进的表型工具的见解相结合。这种方法将专家评估与人工智能分析相结合,通过使用正面图像提供更全面的评估。最近,一个名为 PhenoScore 的人工智能框架被引入。该框架包括两个模块–从二维图像中提取面部特征和基于 HPO 的表型相似性计算–并使用支持向量机(SVM)根据提取的面部特征和 HPO 相似性对综合征进行分类。然而,现有模型分别处理图像和文本,然后将结果合并,这可能会导致信息丢失,因为在训练过程中无法完全捕捉到不同模态之间的交互作用。
为了应对这些挑战,最近专门为罕见遗传疾病的诊断开发了一个基于纯文本 GPT 的模型,称为 DxGPT。该模型建立在闭源GPT-4 基础上,旨在利用多模态机器学习(MML)方法以一致的方式处理面部图像和临床文本。该方法旨在有效地将包括年龄、性别和种族在内的人口统计信息以及包括临床笔记在内的文本信息与患者面部图像整合在一起,以保持数据的完整性和丰富性。
因此,GPT 和基于变压器的多模态机器学习模型的其他进展,正在彻底改变罕见遗传疾病的预测和诊断。变压器源于革命性论文 “Attention is all you need”,它使数据序列能够利用自我注意机制进行并行处理。这样,模型就能得到有效的训练和扩展,并能处理大型数据集。
该技术已广泛应用于自然语言处理(NLP)和计算机视觉(CV)领域,并在从机器翻译、文本生成和情感分析到图像分类、物体检测和视觉问题解答等任务中显示出其有效性。此外,最近的研究还开发出了几种利用转换器的创新多模态模型,如 ViLT、CLIP、VisualBERT、ALBEF 和 Google Gemini。
本文开发了一种新方法 GestaltMML,旨在利用这些最先进的技术进一步提高罕见遗传病诊断的准确性和效率,并改善患者的治疗过程。
安装部署
conda create -n gestaltmml python=3.11
conda activate gestaltmml
conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=11.8 -c pytorch -c nvidia
pip install transformers dataset
pip install pandas
conda install -c anaconda ipykernel
python -m ipykernel install --user --name=gestaltmml
实验概述
下图(a)说明了整个工作流程:GestaltMML 使用经过适当预处理的面部图像、人口统计信息和每种疾病的临床表型描述,这些信息来自 GMDB(GestaltMatcher 数据库)和 OMIM(OMIM:在线人类孟德尔遗传数据库)中关于每种疾病的临床表型描述。
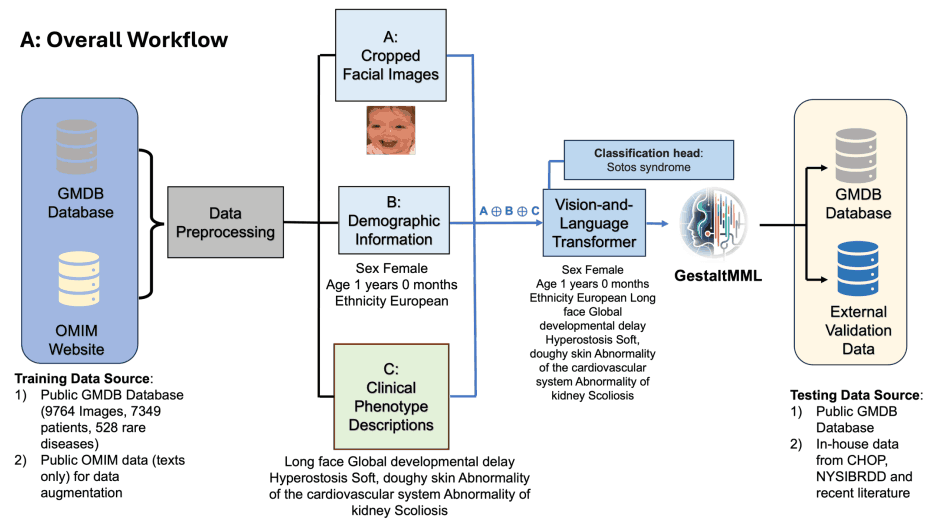
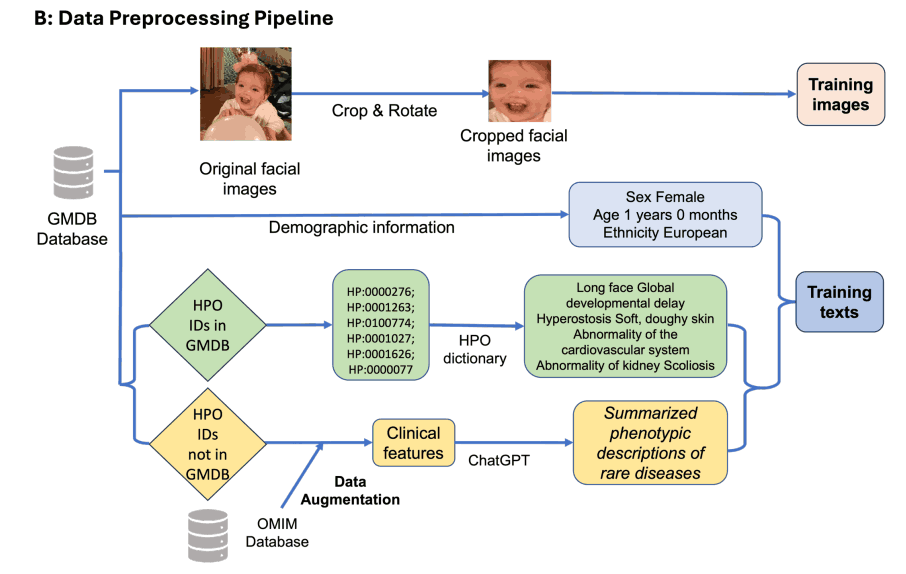
下图(b)显示了以索托斯综合症为例的 GestaltMML 数据预处理流程:用 "FaceCropper "裁剪 GMDB 人脸图像,裁剪成 112*112 大小并旋转。训练文本也分为两类:(1) 人口统计学信息 + HPO 文本数据;(2) 人口统计学信息 + 由 ChatGPT 总结的 OMIM 数据库中的临床特征。
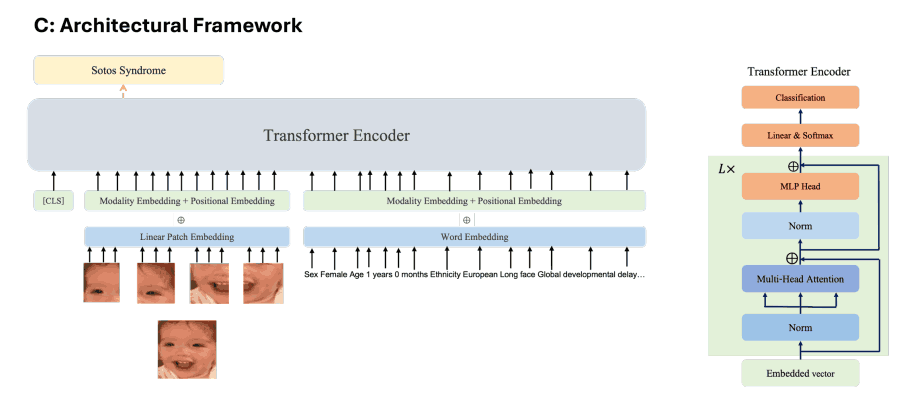
下图(c)显示了 GestaltMML 的架构,它以 ViLT 为基础,使用可处理文本和图像输入的转换器编码器。该架构与 ViT 相似,但不同之处在于 ViT 只接受图像输入。
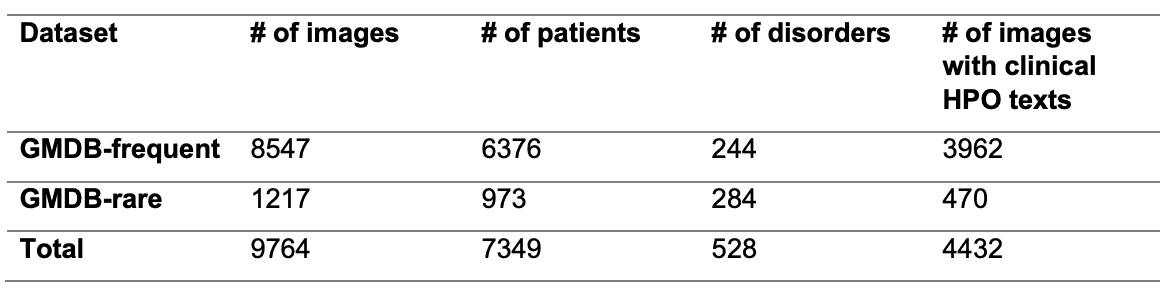
GestaltMML 是一个多模态机器学习模型,结合了面部照片、人口统计信息和临床文本数据。所使用的数据库(GMDB v1.0.9)包含 9,764 张正面面部照片,这些照片来自 7,349 名受 528 种罕见遗传疾病影响的患者。数据库中的患者背景各异,包括中东/西亚人、美洲原住民、东南亚人和北非人。然而,大多数患者都是欧洲后裔(59.48%),而罕见病的性质决定了很难准备一个完全平衡的数据集,这是一个挑战。此外,男女比例大致相当,五岁以下患者占 64.90%。
此外,按照以往研究的惯例,该模型的性能分别针对 GMDB 中常见疾病(>6 名患者,GMDB-常见)和罕见疾病(<6 名患者,GMDB-罕见)进行了评估。然后探讨了文本和图像数据特征的重要性,并与当前基于图像的模型进行了比较。
最后,该方法在多个外部验证数据集上进行了评估,包括费城儿童医院(CHOP)、纽约州发育障碍基础研究所(NYSIBRDD)以及已发表文献中的数据,结果显示该方法具有很高的性能。这些结果证明了所提出方法的稳健性。
GMDB 中罕见遗传疾病的分类
为了解决大量文本数据缺失的问题,GestaltMML尝试将训练与测试数据的分割比例从 1:1 变为 9:1,并使用三种不同的随机种子计算了准确率的平均值和标准偏差。最有效的学习与测试比例是3:1,在这一比例下,模型显示出最高的准确率。前 1 名的准确率为 72.54%,前 10 名的准确率为 83.59%,前 50 名的准确率为 88.96%,前 100 名的准确率为 91.64%。
然而,面临的挑战是,虽然 GMDB 包含 528 种疾病,但研究的罕见疾病数量较少,因为罕见疾病数以千计;GMDB 等数据库只记录了具有特征性形态特征的疾病,因此对于没有明显面部特征的疾病来说该模型的有效性可能有限。不过,在这些情况下,人口统计学和临床表型信息的结合有望帮助确定疾病的优先次序。
功能重要性分析以及与 GMDB 数据集中现有图像模型的比较
以往的许多研究仅将面部图像用于罕见遗传病的预测,而本文通过比较最新的集合图像模型和改进的 GestaltMML,详细分析了特征的重要性。比较采用了以往研究中使用的研究-测试分区方法,并通过将 GMDB 划分为常见疾病组(GMDB-常见)和罕见疾病组(GMDB-罕见)来分析 GMDB。
尤其是,GestaltMML 的独特之处在于它只使用转换器架构,不包括任何卷积处理。相比之下,其他纯图像模型并不使用变换器架构。分析结果如下表所示,这证实了 GestaltMML 在图像-文本组合方面达到了更高的准确度。
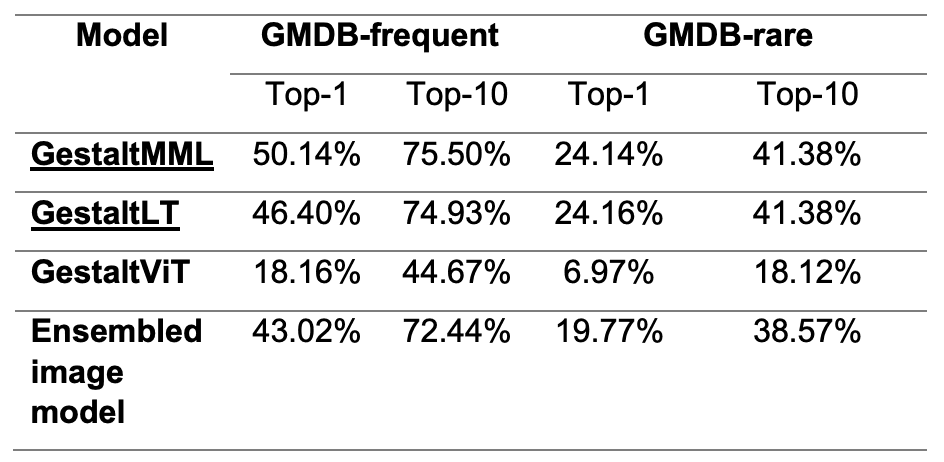
具体来说,7755 幅图像用于训练,792 幅图像用于 GMDB-frequent 测试,360 幅图像用于 GMDB-rare 测试。结果表明,GestaltMML 在 GMDB-frequent 和 GMDB-rare 评估中的预测准确率非常高。
另一方面,一种名为 "模态屏蔽 "的评估方法被用来测试图像和文本的预测能力。在此过程中,文字部分被 ViLT 上的 "*"所取代,并仅使用面部图像进行微调。这样,我们就可以比较仅使用图像还是结合使用图像和文本的预测准确性。分析表明,与集合图像模型相比,GestaltViT 在仅使用图像时表现较差。然而,我们发现添加文字信息后,预测准确率有了显著提高,GestaltLT 的表现优于其他模型,尽管略逊于 GestaltMML。
该实验强调了图像和文本数据的结合在罕见遗传病诊断中的重要性,并展示了 GestaltMML 如何通过多模态方法发挥作用。
提高少数群体诊断的公平性
GestaltMML 使用 GMDB(1.0.9 版)进行训练,GMDB 数据库包含来自不同种族背景的患者数据,如 “中东/西亚”、“美国土著”、“东南亚”、“北非”、“未知”、“非裔美国人”、“美国-拉丁裔/西班牙裔”、“东亚”、“其他亚洲”、"南亚 “和 “非洲”。亚洲”、“南亚”、"撒哈拉以南 "和 “非洲”,并包括不同种族背景患者的数据。
通过整合面部图像、人口统计信息和临床文本,该模型显著提高了预测准确率,尤其是对非西方少数民族患者的预测准确率。下图显示了使用不同推理模式时的平均准确率,其中临床文本对性能提高的影响最大。人口统计学信息也被证明对少数民族患者群体有益。

在下图中,我们还展示了 GestaltMML 如何将面部图像、人口统计数据和临床文本整合在一起,从而在少数种族群体中提高准确性,而以前的学习主要局限于欧洲人后裔。不过,也有极少数例外情况。
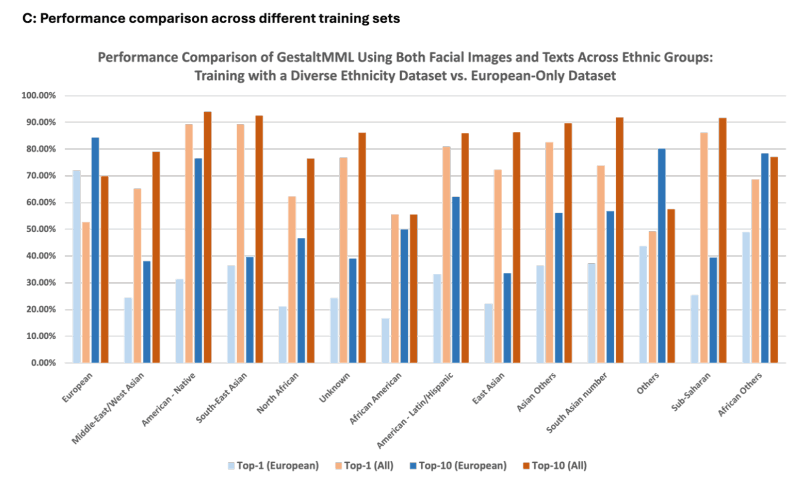
这项实验为 GestaltMML 如何提高诊断公平性提供了宝贵的见解。
在对具有临床相似性的疾病进行聚类方面表现出色
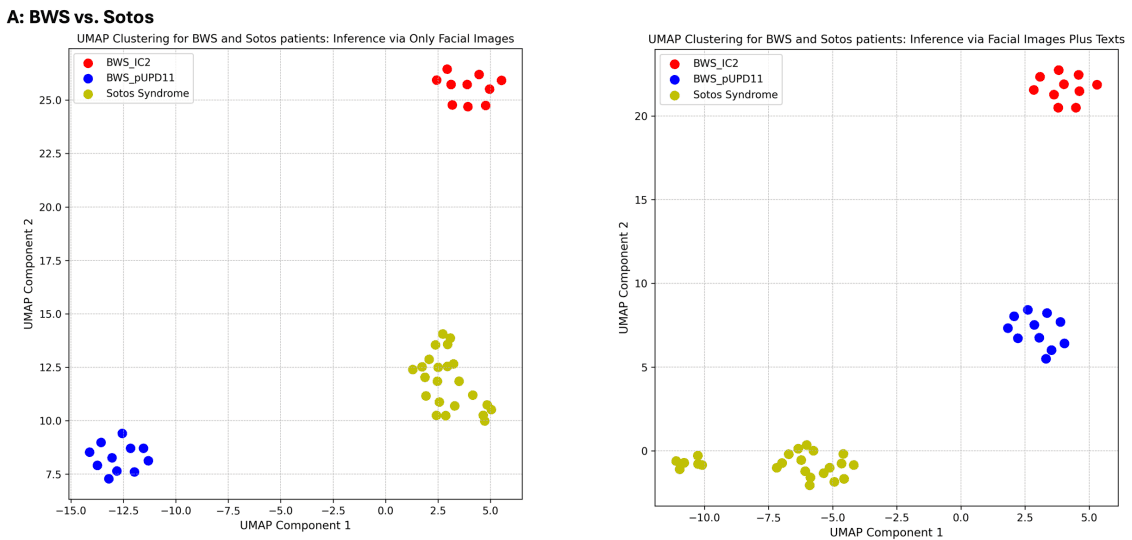
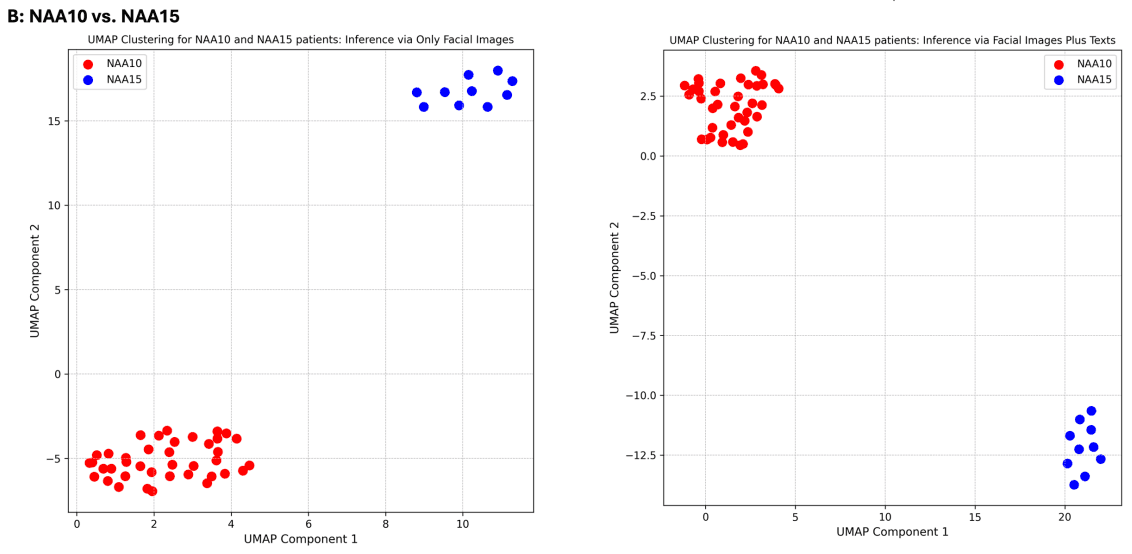
GestaltMML 模型根据最后一层之前那一层的对数值进行了 UMAP 聚类分析,证明了它能够有效地对临床上相似的疾病组进行分类。该分析特别针对贝克维-维德曼综合征(BWS)和索托斯综合征、NAA10 相关综合征和 NAA15 相关综合征以及 KBG 综合征和科尼莉亚-德-朗格综合征(CdLS)之间的比较。
首先,对两种遗传亚型的 BWS 患者和一名索托斯综合征患者进行了分析,证实该模型能够明确区分这些过度生长综合征。
随后,在GMDB(v1.0.9)数据集中评估了与NAA10和NAA15相关的神经发育综合征,结果表明,尽管临床表型相似,该模型仍能有效区分这两种综合征。
在最后的分析中,一组 KBG 综合征和 CdLS 患者被用来证实该模型能够区分这些综合征,但对于 CdLS 患者,使用面部图像推断发现了基于不同背景颜色的两个聚类。这种现象取决于图像的背景颜色,表明背景颜色归一化可提高图像表征的准确性。
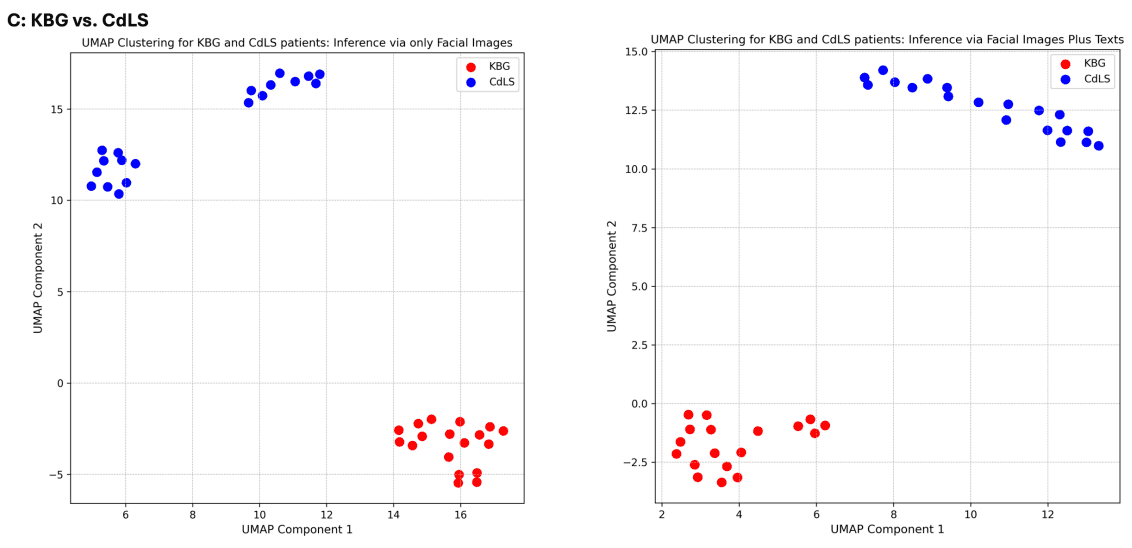
这些结果表明,GestaltMML 在识别具有临床相似性的疾病群方面表现出色,并有望通过进一步改进提高诊断准确性。
总结
GestaltMML 是本文介绍的一种新型多模态模型,它能通过整合面部正面照片、临床特征和人口统计学信息,有效缩小罕见遗传疾病的鉴别诊断范围。这种方法至关重要,因为仅仅依靠患者的面部图像并不能涵盖准确诊断这些疾病所需的全部信息。多模态机器学习可以显著提高遗传诊断的预测准确性,是利用 UMAP 聚类分析区分临床上相似的罕见疾病的有用工具。
这种聚类方法能够在不改变模型分类层的情况下自动识别新发现的罕见病,结合基因组/外显子组序列数据,有望促进对数据的解释和定期重新解释,解决所谓 "诊断奥德赛 "的挑战。它有望解决 "诊断奥德赛 "问题。
与传统的基于 CNN 的图像模型相比,这种方法同时使用面部图像和文本作为输入,从而在预测罕见遗传疾病方面取得了重大进展。特别是,通过将患者人口统计学数据整合到文本输入中,该模型可识别独特的疾病特定模式,减少数据收集和分析偏差,确保诊断无偏见;还引入了使用 OMIM 数据库的数据增强技术,以强化模型训练过程。此外,还使用了模态屏蔽技术来验证多模态学习过程中文本和视觉元素的重要性,为今后的研究提供了启示。
这些成果对医疗专业人员和研究人员具有重要意义,因为它们可能会在未来彻底改变罕见病的诊断,而且有望取得进一步进展。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











