







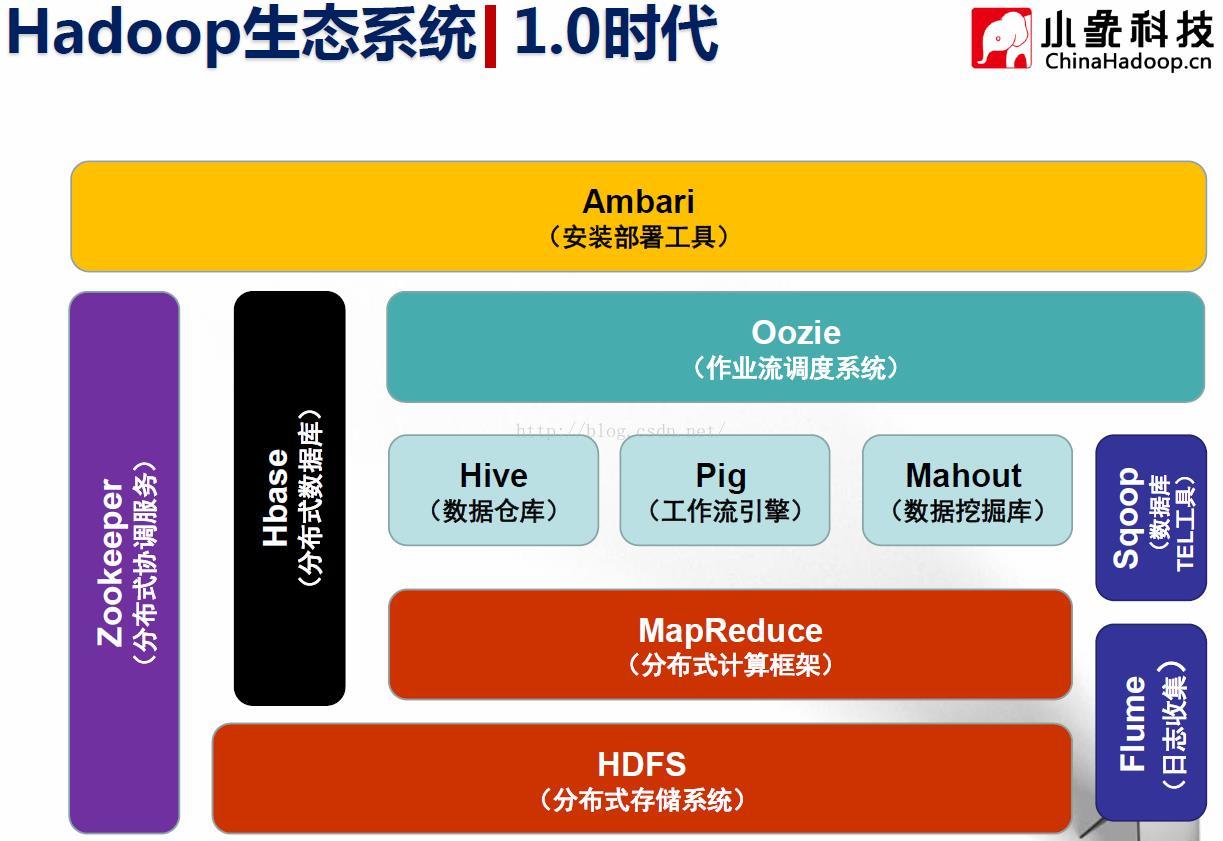
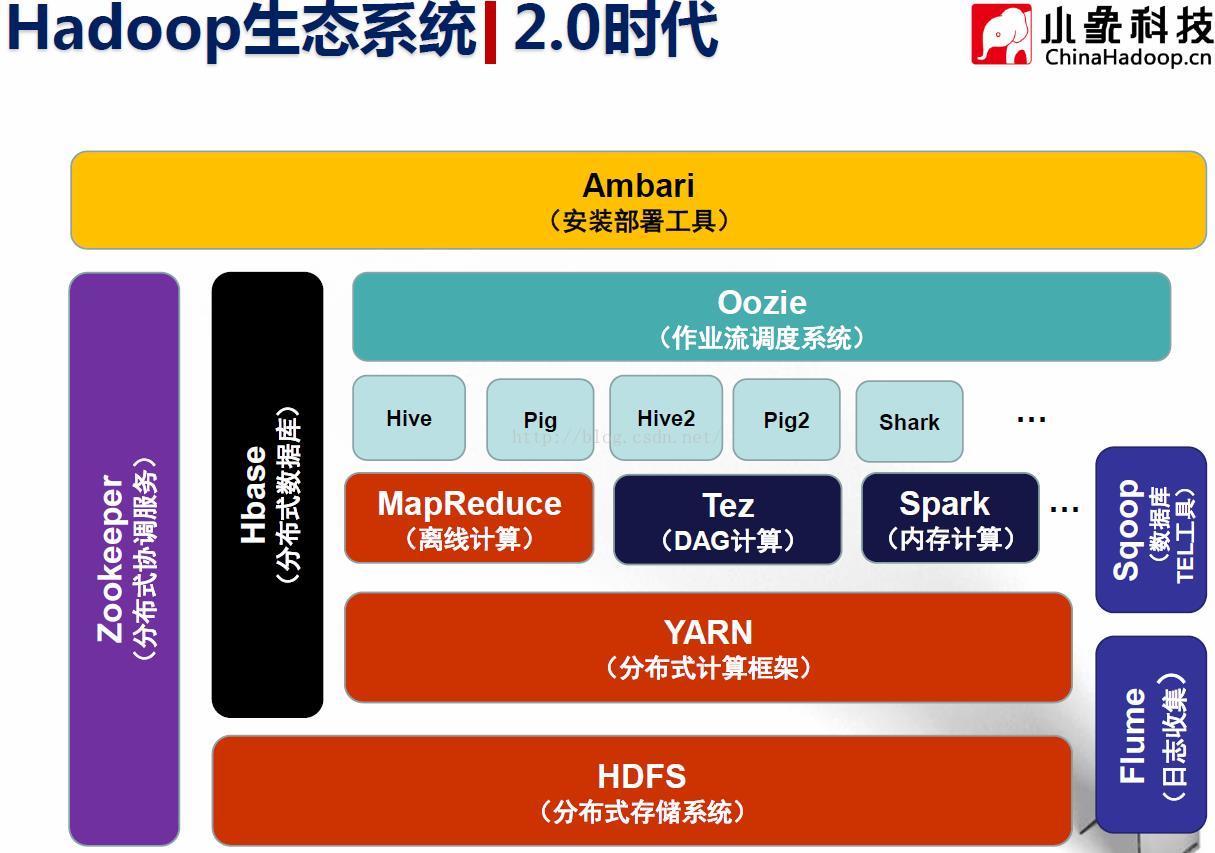
HDFS:分布式存储系统(Hadoop Distributed File System):提供了高可靠性、高扩展性和高吞吐率的数据存储服务
HDFS源自于Google的GFS论文 (发表于2003年10月 ),是GFS克隆版
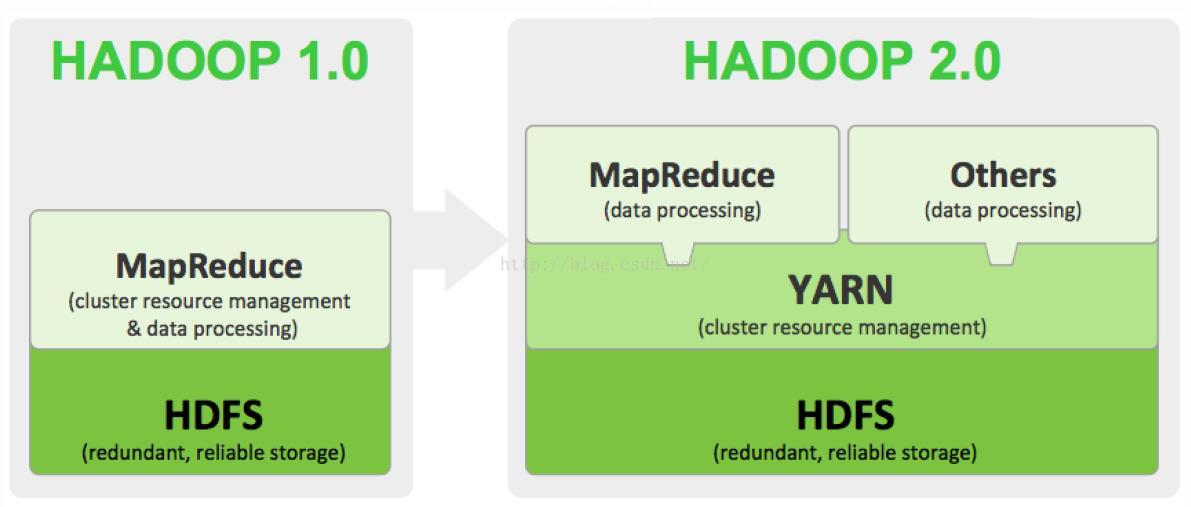
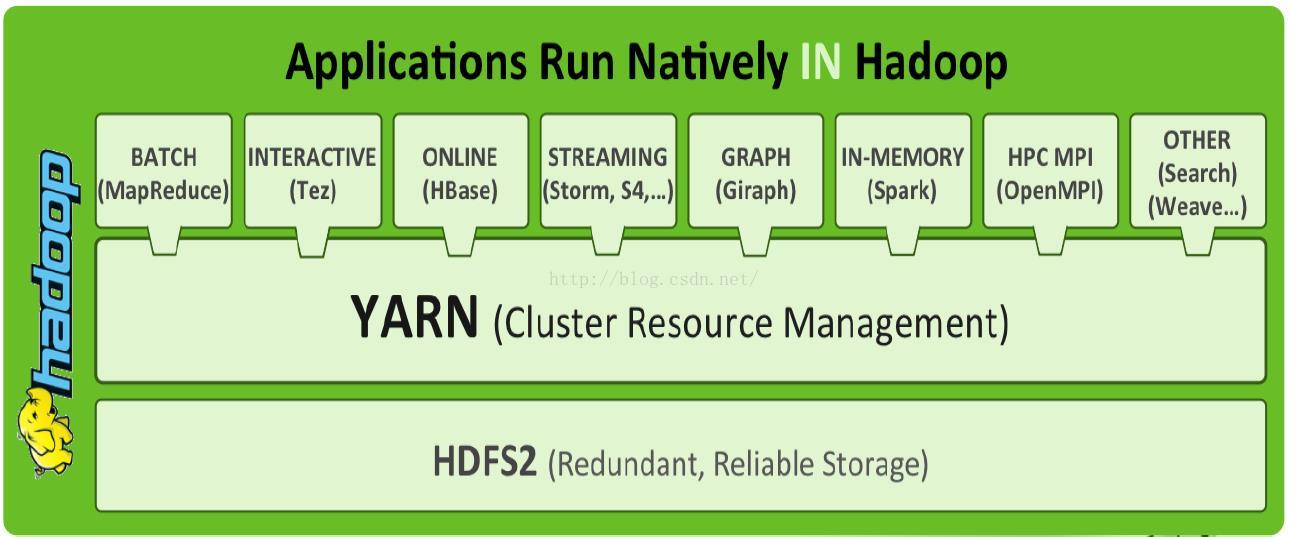
YARN:资源管理系统(Yet Another Resource Negotiator):负责集群资源的统一管理和调度,Hadoop 2.0新增系统,使得
多种计算框架可以运行在一个集群中
MapReduce:分布式计算框架:具有易于编程、高容错性和高扩展性等优点
MapReduce源自于Google的MapReduce论文 (发表于2004年12月),是Google
MapReduce克隆版
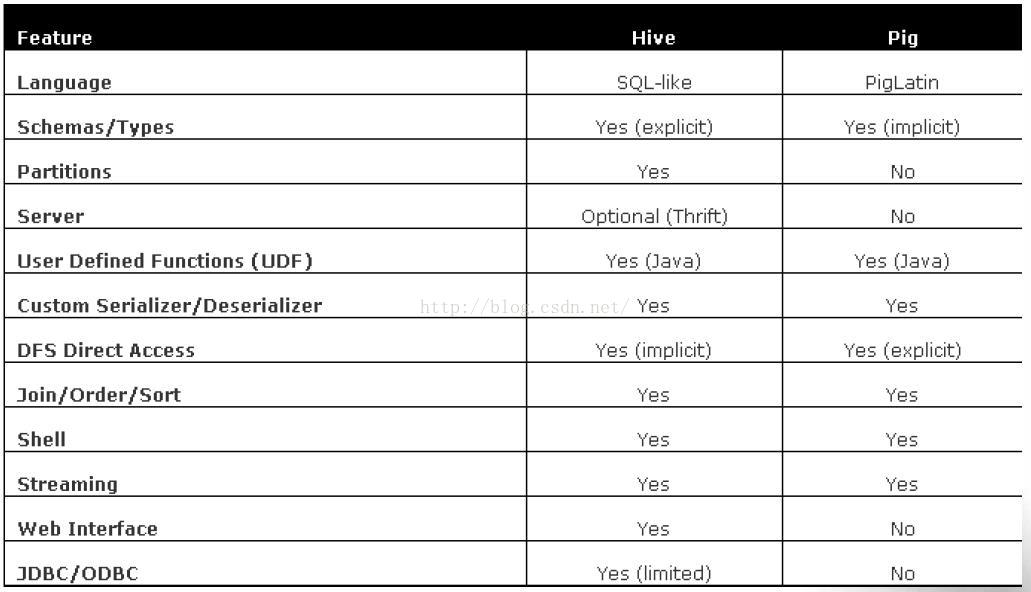
Hive:由facebook开源,基于MR的数据仓库,数据计算使用MR,数据存储使用HDFS,Hive 定义了一种类 SQL 查询语言——HQL:
类似SQL,但不完全相同
日志分析:统计网站一个时间段内的pv、uv
Pig:由yahoo!开源,构建在Hadoop之上的
数据仓库
Mahout:数据挖掘库,基于Hadoop的机器学习和数据挖掘的分布式计算框架,实现了三大类算法 :
推荐(Recommendation) 、
聚类(Clustering) 、
分类(Classification)
Zookeeper:分布式协作服务,源自Google的Chubby论文 ,
发表于2006年11月 ,
是Chubby克隆版
解决分布式环境下数据管理问题 :
统一命名 、
状态同步 、
集群管理 、
配置同步
Sqoop:数据同步工具,连接Hadoop与传统数据库之间的桥梁 ,
支持多种数据库,包括MySQL、DB2等 ,
插拔式,用户可根据需要支持新的数据库 ;本质上是一个MapReduce程序
Flume:日志收集工具,
Cloudera开源的日志收集系统
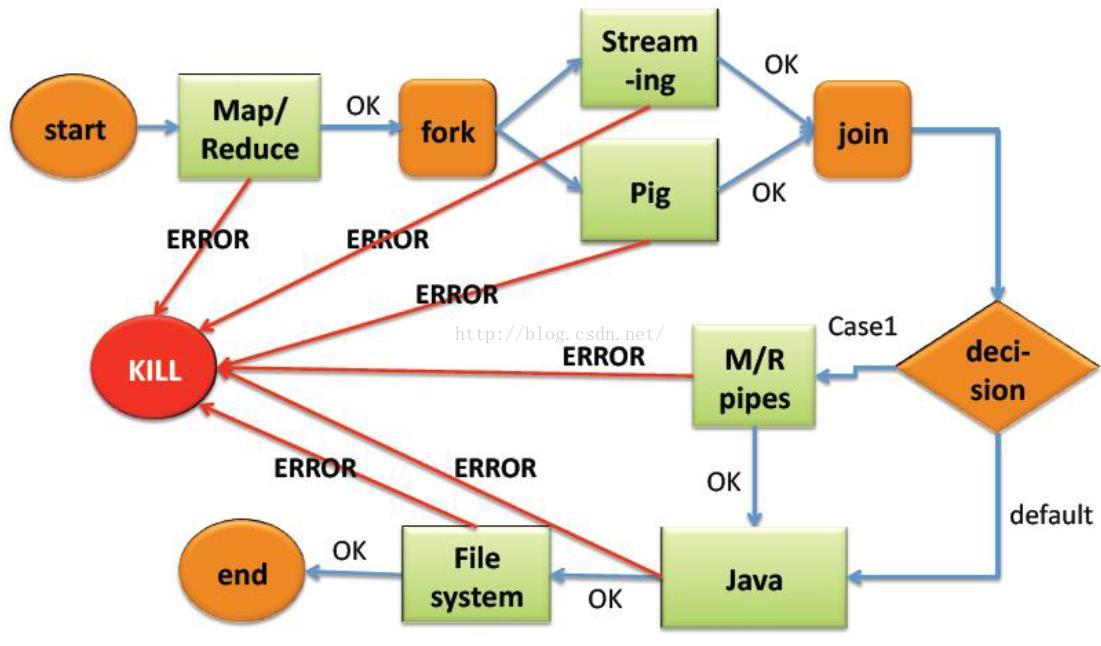
Oozie:作业流调度系统
目前计算框架和作业类型繁多:
MapReduce Java、Streaming、HQL、Pig等
如何对这些框架和作业进行统一管理和调度:
不同作业之间存在依赖关系(DAG);
周期性作业
定时执行的作业
作业执行状态监控与报警(发邮件、短信等)
Hadoop发行版本
apache hadoop版本
CDH:Cloudera Distributed
Hadoop
HDP:Hortonworks Data Platform
建议选择公司发行版(不必面临版本某一个框架的选择问题),比如CDH或HDP ,
推荐使用CDH(国内主流版本)
更易维护和升级
经过集成测试,不会面临版本兼容问题
--------------------------
微信公众号:IT人成长关注
大数据技术QQ群:485681776
--------------------------
微信公众号:IT人成长关注
大数据技术QQ群:485681776














 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









