







原来的值函数就是一个表格型函数,现在状态空间是高维的,不能再用表格表示,用一个函数来逼近值函数,比如用线性、或者非线性,当函数的类型确定了之后,确定这个逼近函数的过层 其实就是确定参数的过程,
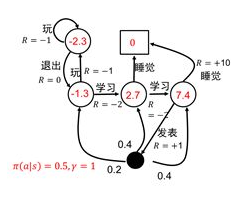
对于三种表格型值函数更新方法都是统一格式
(目标值函数-当前值函数)*学习率=更新后的值函数
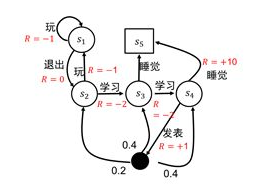
立即回报是状态做了动作之后得到的值? 比如s1状态做退出的动作,回报是0,
那决策π其实是当前状态执行这个动作的概率 ,决策其实是随机的不确定的,没有执行确定的动作,所以下一状态也是不确定的,所以状态序列其实是不确定的,所以累积回报也是一个不确定的值,但是可以对其求期望
累积回报 当然不是是做了所有的决策之后
状态值函数定义:
当智能体采用策略π时,累积回报服从一个分布,累积回报在状态s处的期望值定义为状态-值函数:
公式(1.1)的含义是:策略π在每个状态s指定一个动作概率。如果给出的策略π是确定性的,那么策略π在每个状态s指定一个确定的动作。
策略是一个概率不是一个确定的动作,是做这个动作的可能性
所以说策略是对每个状态都给出了动作概率,最后找到的最优策略,就相当于每一步执行的动作是最优的,执行最优动作的概率为1,其他动作概率是0.
对于累积回报,是对于一个状态的累积回报,立即回报+折扣*后期回报
当给定一个策略π时就相当于知道每种状态接下来可以做哪几种动作,做每种动作的概率是多少。
给定策略后得到的状态序列是不确定的,不同序列就会得到不同的累积回报,也是不确定的,计算累积回报
后面的状态采取动作都会有一个回报,把后面的这些回报以折扣的方式累加。
累积回报是针对单个状态,就想当于一个f(x),对于不同的状态,同时可以求出不同的累积回报
现在累积回报是服从分布,就求出期望就可以,把期望叫做状态-值函数
给定策略了之后,每个状态就可以求出对应的值啦
状态值函数定义:
当智能体采用策略π时,累积回报服从一个分布,累积回报在状态s处的期望值定义为状态-值函数:
计算状态值函数的目的是为了构建学习算法从数据中得到最优策略。每个策略对应着一个状态值函数,最优策略自然对应着最优状态值函数。
二、值函数逼近
在表格型强化学习中,值函数对应着一张表。在值函数逼近方法中,值函数对应着一个逼近函数[公式] 。从数学角度来看,函数逼近方法可以分为参数逼近和非参数逼近,因此强化学习值函数估计可以分为参数化逼近和非参数化逼近。其中参数化逼近又分为线性参数化逼近和非线性化参数逼近。
我觉得可以这样理解,原来比如状态值函数,单个状态对应一个值,状态值函数图像就可以看成一些离散的点
现在状态多了,(实际状态是连续的,看成很密集的离散的点),我们用一条曲线来拟合这些密集的点
原来利用状态-值函数,把每一个状态对应的值都求出来写在表格中,值函数就可以对应一张表格,现在状态连续,没有办法一一对应的求解写成表格,只能找到状态和值之间的关系,也就是之间的函数关系,只能把函数关系表示出来,这个函数关系我们称为逼近函数。
状态是机器感知到的环境描述
模型已知,即机器已对环境进行了建模,能在机器内部模拟出于环境相同或近似的状况















 565
565











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









