






一、Transformer的模型结构
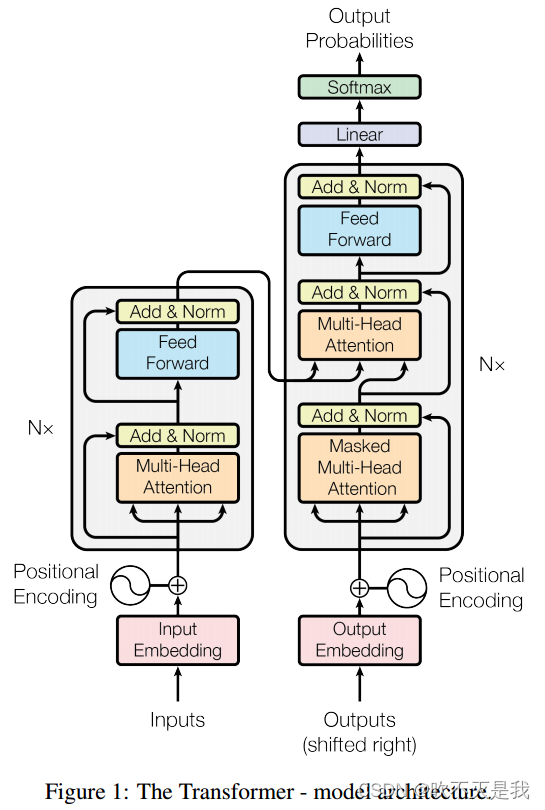
上图是《Attention Is All You Need》一文中transformer网络模型结构图,先总览一下。接下来会详细说明我对于这个网络的理解。
二、网络模型详解
首先声明,楼主也是初学阶段,所掌握的知识也不全面,所以有些问题描述不清楚甚至是错误的,希望各位批评指正。
transformer模型是按照编码-解码结构来构造的,它引入了自注意力机制(self-attention mechanism),允许模型在处理序列数据时同时关注序列中不同位置的信息,而不是依赖于顺序处理或递归处理。网络的主要成分为输入嵌入(input embedding)、自注意力机制(Self-Attention Mechanism)、多头注意力(Multi-Head Attention)、位置编码(Positional Encoding)和前馈神经网络(Feedforward Neural Network)。
1.输入嵌入(input embedding)
transformer模型被广泛用于NLP也就是自然语言处理的任务,而语言是人的发明。我们在交谈的时候信息传递的媒介是人,所以使用文字没有什么问题,但是如果信息传递的媒介变为电磁波等,我们就需要把人类语言变为自然语言,比如发电报的时候我们将每个单词或者每个汉字转换为摩斯密码,不同的间隔表示不同的单词。以便在这台机器发出后,另一台机器能够理解。在深度学习的任务中,我们需要把文字转换为机器(神经网络能够理解的东西),输入嵌入就是这个作用,他把每个词转化为一个向量,也就是另一个空间中。例如:I am Tom 总共三个单词,单词I就可以是[1, 0, 0],am就是[0, 1, 0], Tom就是[0, 0, 1]类似于one-hot编码。
2.位置编码(positional encod)
需要对输入的句子进行编码的同时也需要对词在句子中的位置进行编码。如果处理的对象是2D或3D的图像,我们就需要对输入的patches的位置进行编码。《Attention Is All You Need》一文中使用了如下公式进行计算:
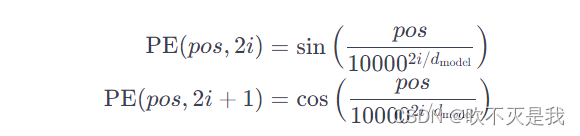
其中,pos是位置,i是维度的索引,d_model是嵌入向量的维度。这个公式使用了正弦和余弦函数,通过调整不同维度的值,使得不同位置的位置编码是唯一的。这样,将这个位置编码加到词嵌入中,就能够在嵌入表示中加入位置信息。最后将得到的位置编码矩阵与输入进行相加或拼接。
3.多头注意力(Multi-Head Attention)

多头注意力机制基于自注意力机制(Self-Attention Mechanism),下面来讲解一下什么是自注意力机制。
首先我们输入网络的是一段文字,矩阵[I, am, Tom]经过embedding后变成一个矩阵X=[x_1, x_2, x_3],X经过查询矩阵W_q,键值矩阵W_k和值矩阵W_v变换成三个矩阵分别是Q= {q+1, q+2, q_3},K= {k_1, k_2, k_3 },V = {v_1,v_2,v_3}。
注意力分数就经过a_ij = (q_i 点乘k_j)/(d_k)^0.5,d_k是键的长度也就是k_j的长度。a_ij度量的是位置j对于位置i的重要性。
总结为矩阵运算就是Attention(Q,K,V)=softmax(Q·K^T)·V,注意这里的Q的形状是3×1,K的形状是3×1,V的形状也是3×1,虽然书写是横着的,但其实Q,K,V均是三行一列的数据,softmax操作是对所有位置对于某位置的注意力权重(也就是i不变,j变化)进行一个归一化,使他们加起来等于一。最后得到的Attention(Q,K,V)也就是Z矩阵就是注意力矩阵,包含了句子各个词之间的重要性,他会和输入的X矩阵相加后进行laternorm。
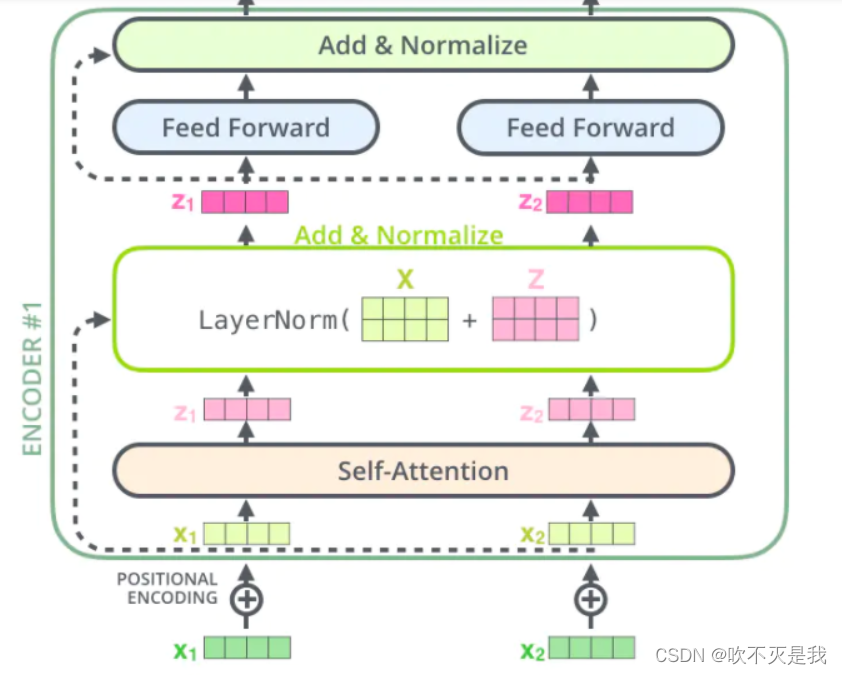
那么什么是多头注意力机制呢,多头注意力(Multi-Head Attention)就是使用了多组查询矩阵W_q,键值矩阵W_k和值矩阵W_v得到多组Z的方法。
3.前馈神经网络(Feedforward Neural Network)
前反馈神经网络总结为一个公式就是:
FFN(x)=max(0,xW_1 +b_1)W_2+b_2.
就是将输入进行一个线性变化,然后进行Relu操作,然后再进行一次线性变化。
4.add
add操作就是在网络中添加一个残差块,残差块的结构如图所示。

块的输入是X,块的中间处理操作时F(),X被操作之后再与X相加。最终块的输出是F(X)+X,当这一层再神经网络的训练中是多余的话,F(X)+X就会趋向于变为X,也就是说F()操作会趋向于把输入变为0.
最后声明,这并不是说add操作是添加了如图所示的块,而是add操作时图示的加号那一步操作。并不是add部分又写了新的卷积方法。之后的normalize就是对输入进行Layer Normalization,保留句子中各词之间的相关性,因为Layer Normalization是对输入的每句话进行归一化。Batch Normalization,则是对同一批输入的多句话的第i个位置的词拿出来进行归一化,这样没有意义。
5.掩码多头注意力(Masked Multi-HeadAttention
)
这一部分存在与解码器部分,它计算过程与Multi-HeadAttention是一样的只是多加了一个掩码,掩盖住一部分输入,使其在参数更新时不产生影响。transformer中共有两种掩码。
padding mask
本掩码为了保证输入的序列长度一致,短的补上一个负无穷的数,保证经过softmax函数之后不产生影响,长的序列就对尾巴进行掩盖。
sequence mask
保证解码器只对当前的输入作出反应,不能使其看见未来的信息,所以要把当前时刻之后要输入的数据掩盖起来。类似于一个字一个字的输入。准备一个三角矩阵即可。
参考
1.Stink1995.史上最小白之Transformer详解.https://blog.csdn.net/Tink1995/article/details/105080033?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170243756916800184193777%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=170243756916800184193777&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-105080033-null-null.142v96pc_search_result_base4&utm_term=transformer&spm=1018.2226.3001.4187
2.空杯的境界.Transformer 模型详解.https://blog.csdn.net/benzhujie1245com/article/details/117173090?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170243756916800184193777%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=170243756916800184193777&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-2-117173090-null-null.142v96pc_search_result_base4&utm_term=transformer&spm=1018.2226.3001.4187















 2346
2346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









