









目录
前言
需要在环境变量里设置HADOOP_CONF_DIR或YARN_CONF_DIR,告诉Spark如何连接Hadoop
一、Client模式
spark-submit \
--class com.wsd.sparkcore.scala.SparkWCListenerV2 \
--master yarn \
--deploy-mode client \
/opt/lib/bg-spark-core-1.0.jar \
/data/wc/wc.txt /data/wc/spark-wc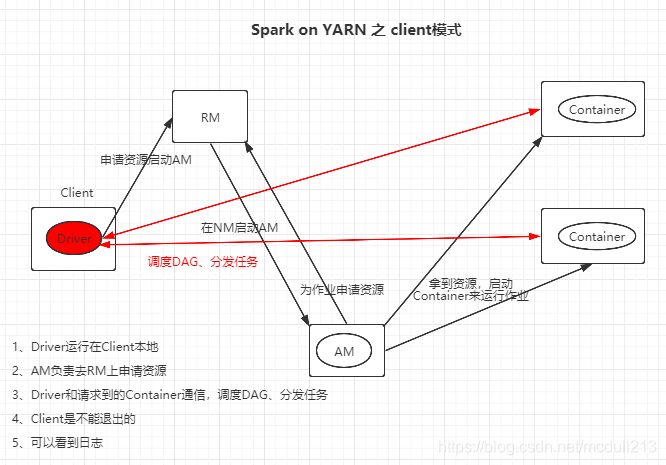
二、Cluster模式
spark-submit \
--class com.wsd.sparkcore.scala.SparkWCListenerV2 \
--master yarn \
--deploy-mode cluster \
/opt/lib/bg-spark-core-1.0.jar \
/data/wc/wc.txt /data/wc/spark-wc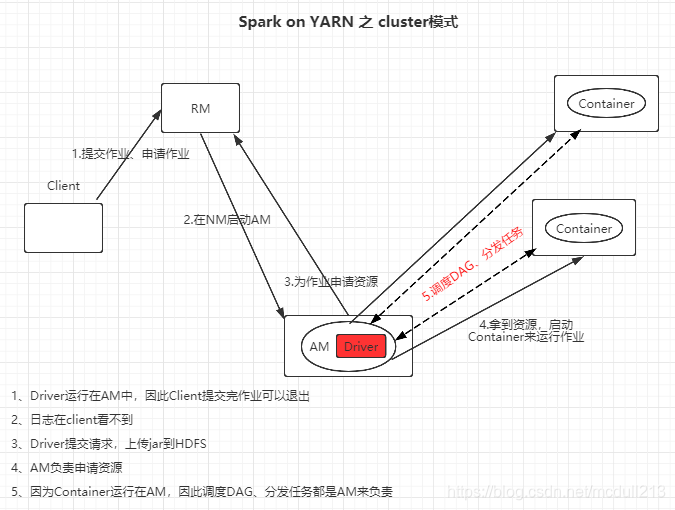
三、两种模式对比
可以看到两种模式,最大的区别就是
client模式Driver运行在本地,而cluster模式Driver运行在AM中。
因此
client模式:client是不能退出的,能看到日志,AM仅负责申请资源,Driver负责调度DAG、分发任务
cluster模式:client是可以退出的,client端看不到日志,AM出负责申请资源,还负责调度DAG、分发任务
如何选择?
我们业务的client机器本身就是在集群中,两种模式流量并不会差太多,为了方便观察实时运行日志,选择的是client模式

















 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









