






目录
1. 引言
在机器翻译领域,Transformer 模型凭借其卓越的性能和并行计算能力,迅速成为了主流。与传统的 RNN 和 LSTM 模型相比,Transformer 模型具有更高的训练效率和更好的翻译效果。本文将详细介绍基于 Transformer 实现机器翻译的过程,包括数据准备、模型构建、训练与评估等内容。
2. Transformer 模型概述
2.1 模型架构
Transformer 模型由编码器(Encoder)和解码器(Decoder)组成。编码器负责将输入序列映射为隐藏表示,解码器则将隐藏表示转化为输出序列。
2.2 核心组件
- 多头自注意力机制(Multi-Head Self-Attention):通过多个注意力头并行计算,提高模型捕捉长距离依赖关系的能力。
- 位置编码(Positional Encoding):向输入添加位置信息,使模型能够识别序列中的位置信息。
- 前馈神经网络(Feedforward Neural Network):在每个编码器和解码器层中加入,用于进一步处理信息。
3. 实现流程
3.1 数据准备
选择合适的双语数据集(如 WMT、IWSLT),进行预处理,包括分词、去重和生成词汇表等步骤。
3.2 模型构建
使用 PyTorch 框架实现 Transformer 模型,设置合理的超参数(如层数、注意力头数、隐藏层维度等)。
3.3 模型训练与评估
采用 Adam 优化器进行训练,使用交叉熵损失函数评估模型性能,训练过程中记录损失和准确率。
4. 代码实现
4.1 数据预处理
使用 torchtext 或其他数据处理库加载并预处理数据。
import torch
import torchtext
from torchtext.data.utils import get_tokenizer
tokenizer = get_tokenizer("spacy", language="en_core_web_sm")
def tokenize(text):
return tokenizer(text)
# 示例代码:加载和预处理数据
train_data, valid_data, test_data = torchtext.datasets.Multi30k.splits(
exts=('.en', '.de'), fields=(tokenize, tokenize))
4.2 模型定义
定义 Transformer 模型,包括编码器、解码器和多头自注意力机制。
import torch.nn as nn
import torch.nn.functional as F
class TransformerModel(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, dropout=0.1):
super(TransformerModel, self).__init__()
self.transformer = nn.Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, dropout)
self.src_embedding = nn.Embedding(src_vocab_size, d_model)
self.tgt_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
def forward(self, src, tgt, src_mask=None, tgt_mask=None, memory_mask=None):
src_emb = self.src_embedding(src)
tgt_emb = self.tgt_embedding(tgt)
output = self.transformer(src_emb, tgt_emb, src_mask, tgt_mask, memory_mask)
output = self.fc_out(output)
return output
4.3 训练循环
编写训练循环,进行模型训练和评估。
import torch.optim as optim
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
tgt = batch.trg
optimizer.zero_grad()
output = model(src, tgt[:-1, :])
output_dim = output.shape[-1]
output = output.contiguous().view(-1, output_dim)
tgt = tgt[1:].contiguous().view(-1)
loss = criterion(output, tgt)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
4.4 评估与测试
定义评估函数,计算模型在验证集和测试集上的表现。
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
tgt = batch.trg
output = model(src, tgt[:-1, :])
output_dim = output.shape[-1]
output = output.contiguous().view(-1, output_dim)
tgt = tgt[1:].contiguous().view(-1)
loss = criterion(output, tgt)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
5.结果展示
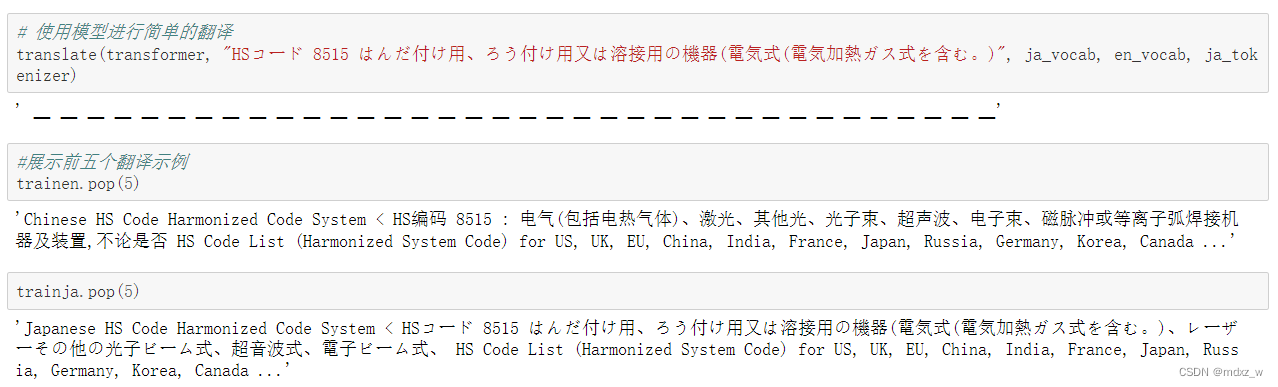
6. 总结
本文介绍了基于 Transformer 模型实现机器翻译的完整流程,包括数据准备、模型构建、训练与评估等内容。Transformer 模型凭借其强大的并行计算能力和长距离依赖处理能力,在机器翻译领域取得了显著的效果。通过本文的介绍,希望读者能够对 Transformer 模型有更深入的理解,并能够应用于实际的机器翻译任务中。















 1028
1028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









