






复习:简单的word2vec模型
cost fuction( 求导结果参照视频教程):
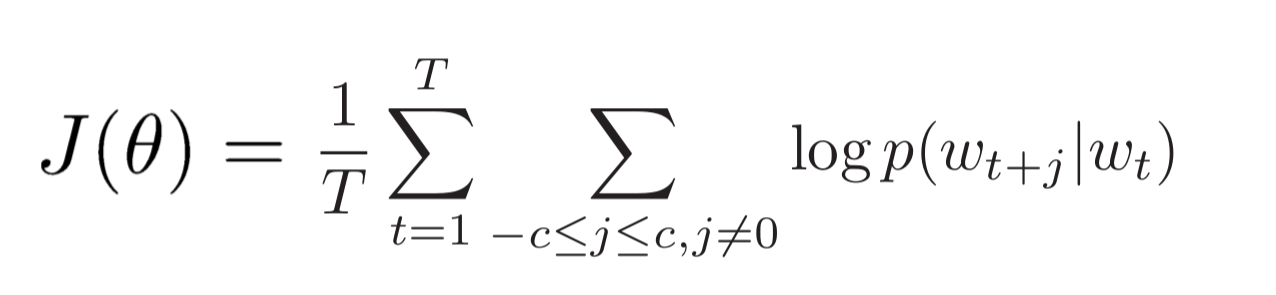
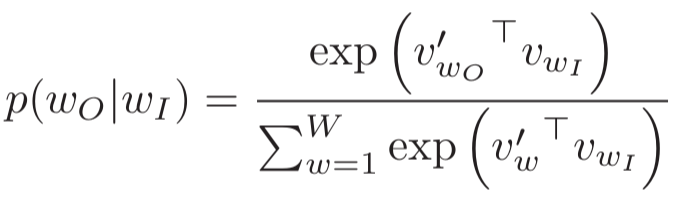
梯度下降
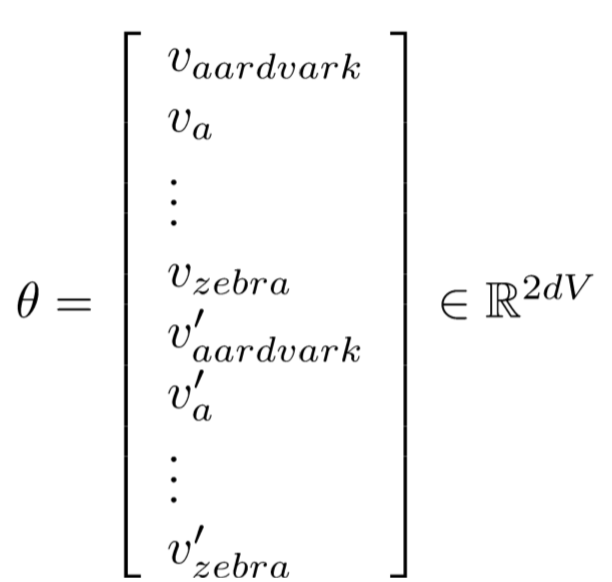
将所有参数转换成一个列向量 Θ (V为词汇数,v是中心词的word vector,v’是external word vector):
使用full batch最小化cost将要求计算cost对所有window的导数
更新 Θ 的每个元素:
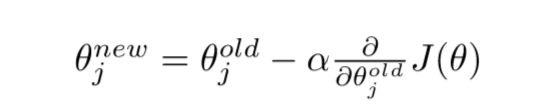
向量化表示(对 Θ 中的所有元素):
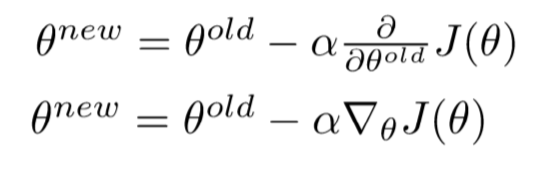
代码示例:

SGD
数据集可能含有40B的数据,这样的话,用full batch的方法就算迭代一次也会花费很长时间,所以采用SGD的方法:

但是还有一个问题,在每一个window中最多含有(2c-1)个单词(即vector,一个单词对应一个vector),所以得到的cost对每个window的导数是非常稀疏的 :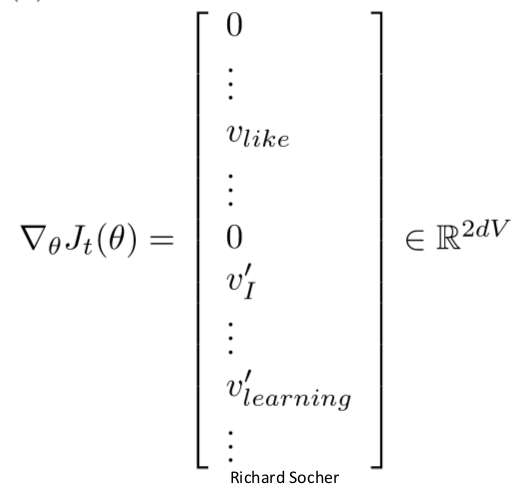
稀疏的解决方案:1.保持周围word vectors的散列值。2.更新整个word embedding matrix L和L’的确定的某些列。
PSet1
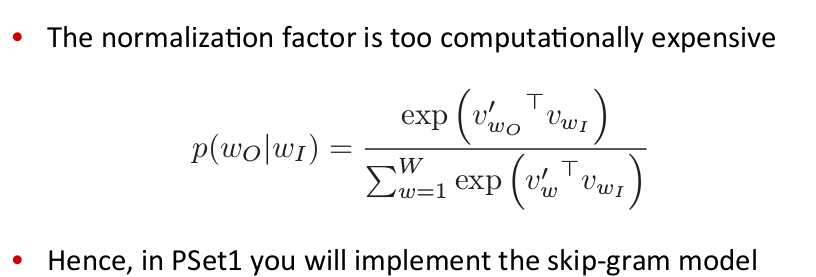
主要思想:用二分类的逻辑回归,训练一组true pairs(中心词和其context window内的其他词)和多组random pairs(中心词和其他随机挑选的词)
skip-gram模型和负采样(k为负采样数):
skip-gram cost(maximize该函数)

或者写成( unigram distribution U(w)):
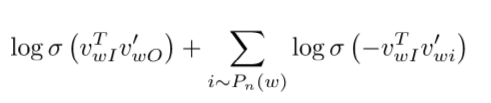
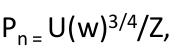
使得不频繁出现的词更多的被取样
另一个模型:CBOW(continuous bag of word):
CBOW主要思想:通过周围单词的word vectors的和预测中心词,不同于skip-gram,skip-gram是通过中心词预测周围的单词word vectors。
单个模型训练后会获得L和L’两个由word vectors组成的矩阵,但是这两个矩阵捕获的信息是相似的,所以,最好的信息的是将他们相加:
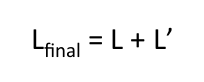
如何评估word vectors
word vector anology:
大多数以前评价word vector的方法是比较相近单词对应的vector间的距离和角度:

milolov提出了基于word anology的多维评价方法,例如:
对于句子“king is to queen as man is to women”,相对应的word vector应该满足:king - queen = man - women。又比如,在G loVe的误差测试test中(预测下划线中的词):
1.对于语义semantic:Athens is to Greece as Berlin is to __?
2.对于语法syntactic:dance is to dancing as fly is to __?
Analogy评估和模型参数选择
各个模型测试结果:
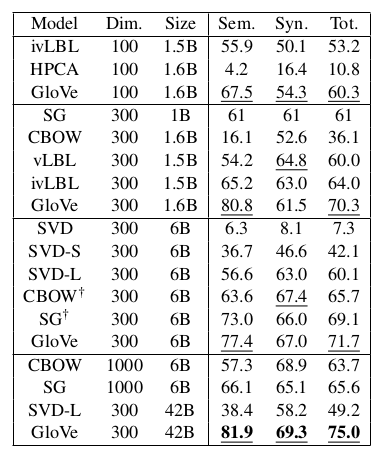
模型参数的选择:
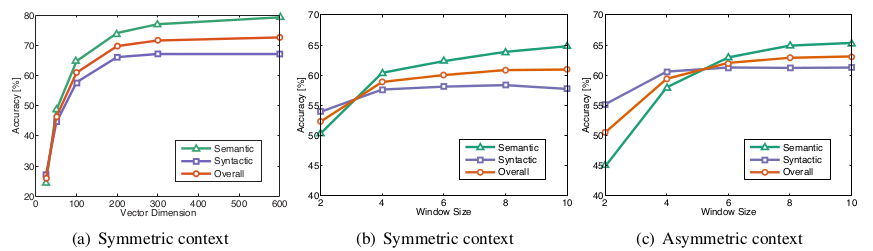
对于GloVe来说,context window size设置为8,word vector的维数设置为300是个不错的选择。
从模型的其他测试结果来看,还可以得到另外一些有用的技巧(结论),针对GloVe:
1.对于语法syntactic:较小的单边context window会的到更好的结果(原因是syntactic主要在于词序)
2.对于语义semantic:较大的双边context window会得到较好的结果
3.对于数据集corpus的大小:越大的数据及会有更好的结果,但是semantic对数据集的大小关系不那么明显,而是和数据集的真实性和丰富度有关(所有在wikipedia上训练得到的结果要比其他固定不变的数据集的结果要好)
可能你会想要一个词的word vector捕获所有类型的信息,例如:run既是动词也是名词。但是实际上对于不同的词性,对应的word vector被拉向了不同的方向,参考: Improving Word Representa4ons Via Global Context And Mul4ple Word Prototypes (Huang et.al. 2012)。


好的word vector的一个实例,named entity recognition(命名实体识别):标记一段文字中的一系列名词,如公司名,地址名,人名等。
在神经网络中使用word vector(单个词,无context window)
deep learned word vector的主要好处:
1.正确对单词分类的能力,例如:countries类的word vectors聚集在一起,有利于对地址进行分类。
2.整合各类信息到word vectors,例如:将情感信息映射到word vector,有利于找到数据集corpus中的一些积极的获得消极的单词。
softmax:
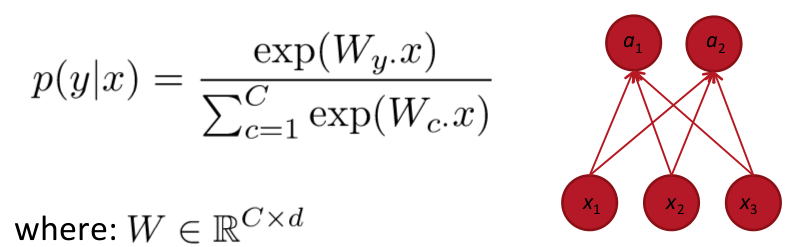
通常用于类别数大于2的分类任务
相关术语: Loss function = cost function = objective function
softmax的loss函数:Cross entropy(交叉熵)
计算p(y|x):
1.首先将权重W的第y行与X(训练集word vector)的每一行(列)相乘(视具体的矩阵有区别):
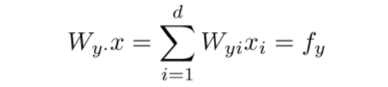
2.逐一相乘,计算fc for c=1,…,C
3.归一化(将数值限制在0~1之间),通过softmax获得概率值:
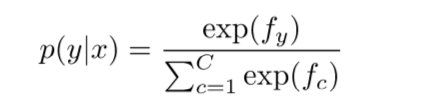
最小化负log似然函数(对于多分类问题,将所有类别的交叉熵加起来,作为最后的loss方程):
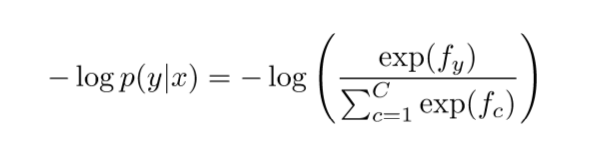
训练时,使用ground truth:对于正确的类别置1,其余的置0,即
p=[0,…,0,1,0,…0],所以交叉熵只计算每个样本的right class所对应的误差,错误类别也对求梯度无影响(q为softmax):
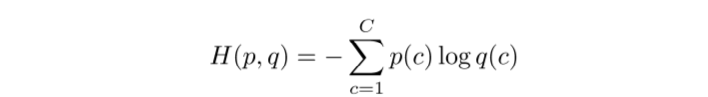
也可以写成:
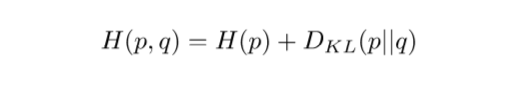
所以最小化交叉熵变成了最小化KL divergence(KL 散度),KL散度并非表示距离,而是测量两个概率分布(p和q)之间的差异:
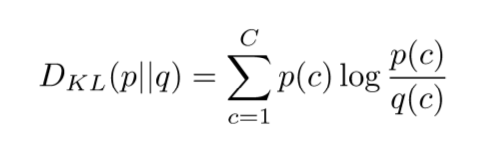
将交叉熵分别对X和W求导(见视频)
实例:情感分析(单个词,无context window)
两个训练方案:
1.固定word vector的值,只训练softmax的权值W
2.训练word vector的值,同时也训练softmax的权值W
训练word vector的利弊:
1.更好的拟合训练集(training set,非test set)
2.更差的泛化特性(because the words move in the vector space)
可视化情感分析中,训练得到的word vector

















 1438
1438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









