







UC伯克利的一篇文章
介绍:
1.Semantic Segmentation有两个固有性质:
1)semantic: global information解决目标是什么的问题
2)location:local information解决目标在哪的问题
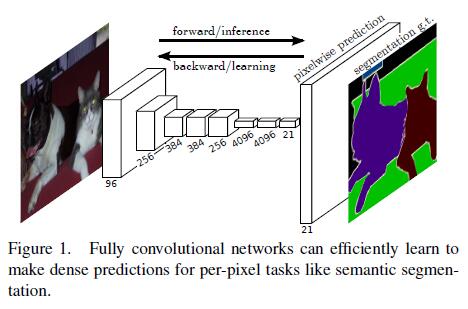
2.关于本文提出的FCN:
1)利用现有的Classification model进行finetuning
2)通过 skip connections来combine deep,coarse,semantic和shallow,fine,appearance layer
3)没有pre-或者post- process
4)任意的input size,输出相应size的output
Idea:
1. Fully Convolutional Networks
1)Adapting classifiers for dense prediction:通过增大input size,使得原来Classification model的vectors变成map(全连接层也要相应的变成1x1的卷积层)
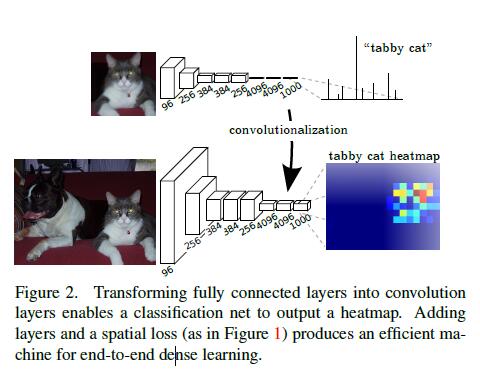
2)Shiftandstitch is filter rarefaction:这个其实是overfeat的手段,由于第一步后最终输出的map太小(10x10),所以需要进行upsampling操作。这里的做法就是:如果input被网络subsample的factor为f,则在Segmentation的时候,在input上进行shift(left-top padding)操作。
3)Upsampling is backwards strided convolution:本文的实验的upsampling最终是使用这个trick的:Deconvolution(即将原来的Convolution过程反向),可以理解为双线性差值,但是其参数是可以随着back-propagation进行学习的,如果加上activation,甚至可以实现non-linearty的upsampling。要实现最简单的FCN,只需在卷积化的Classification model后加一个1x1的Deconvolution(参数不可更行,双线性插值)层就行了,如果input 被subsample了f倍,则将Deconvolution的stride设置为f即可
4)Patchwise training is loss sampling:除了whole image training,作者也试了patch-wise的training。相较于whole image,patch-wise有利于class-balance(whole image 也可以通过weighting loss达到)
2.Segmentation Architecture:
除了最简单的FCN(本文称为FCN-32s,即最后的Deconvolution stride设置为32),也探讨了几种skip-connections
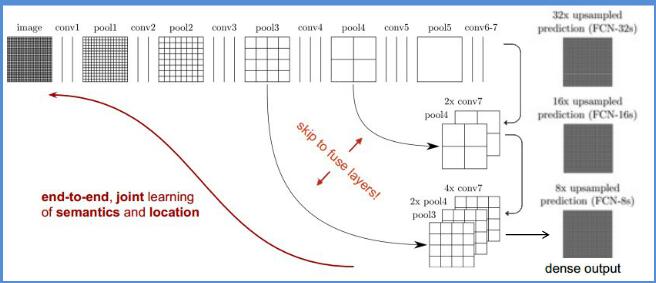
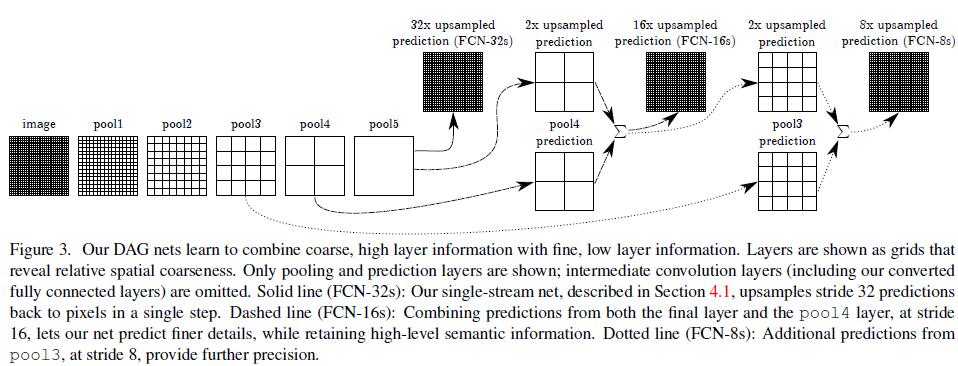















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









