







 本文介绍如何使用Python爬取百度百科数据,包括设定初始词条,分析网页结构,爬取网址、标题和简介。通过逐步讲解,展示非封装方式的爬虫实现过程,涉及编码格式处理、数据存储到txt文件等步骤。
本文介绍如何使用Python爬取百度百科数据,包括设定初始词条,分析网页结构,爬取网址、标题和简介。通过逐步讲解,展示非封装方式的爬虫实现过程,涉及编码格式处理、数据存储到txt文件等步骤。
1.前言
在Python网络爬虫系列的前两篇文章中,我们分别介绍了使用socket库和urllib库爬取网页数据,也稍稍提及了正则表达式。
但是,实际的爬虫工作更具系统性,更具模块性,也更加具备实用价值
接下来,我们将在一个模块中完成爬虫的几项基本工作:第一,爬取网页;第二,分析网页数据;第三,存储所需资源。
一个可参考的实例是:指定初始地址,利用网络爬虫爬取n条百度百科数据。当n很大时,我们爬取的数据也将具备高价值。
4
2.实例任务
爬取一百条百度百科数据,包含网址,百科词条(标题),百科简介(因为全文数据量较大,故作为演示只需爬取内容简介即可)。初始词条可设置为任意你感兴趣的内容,比如大家现在最喜欢抢的“红包君”。
3.预热分析
在抓取某种网页之前,我们有必要去分析这种网页的重要元素:内容特征,网页结构,编码格式等等。
比如,打开“红包”的百度百科页面,如下图所示:
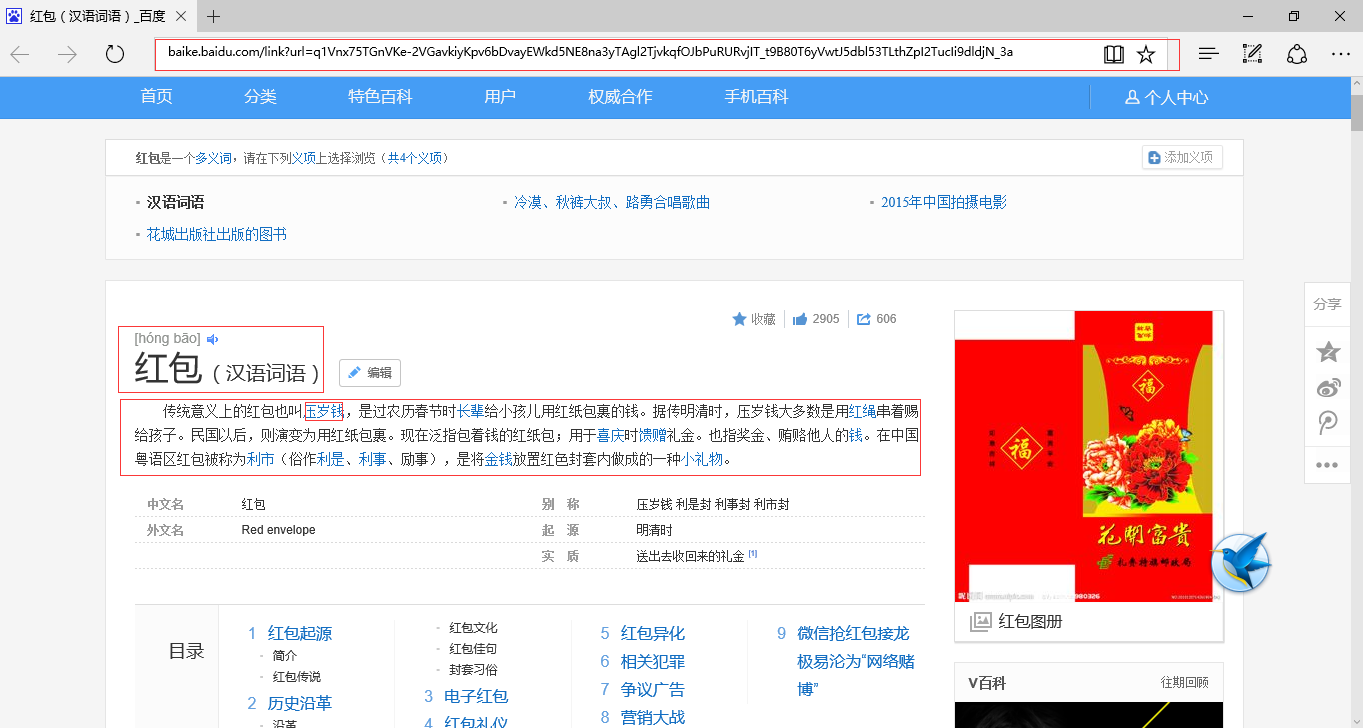
值得注意的内容有:
一、网址url,注意显示的url并不完全,用鼠标点击可以获取完整的url如下:
完整url:
http://baike.baidu.com/link?url=q1Vnx75TGnVKe-2VGavkiyKpv6bDvayEWkd5NE8na3yTAgl2TjvkqfOJbPuRURvjIT_t9B80T6yVwtJ5dbl53TLthZpI2TucIi9dldjN_3a;
二、百科词条(红包)
三、内容简介
四、超链接(蓝字部分)
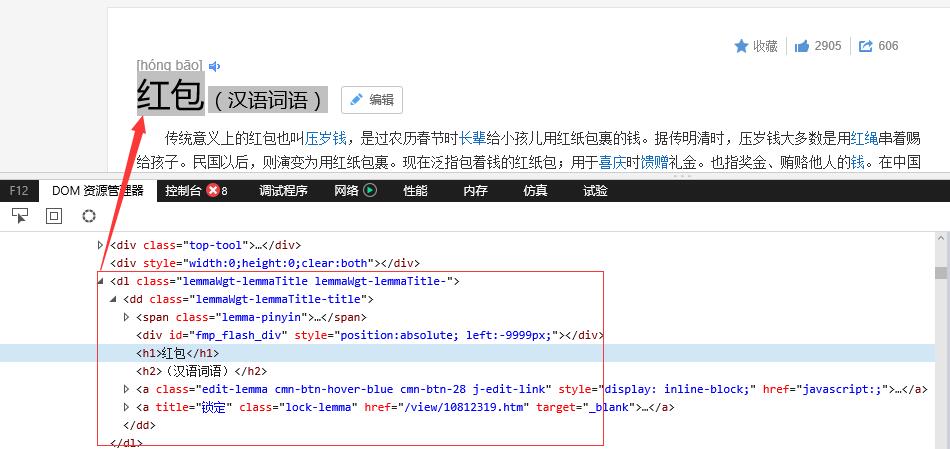
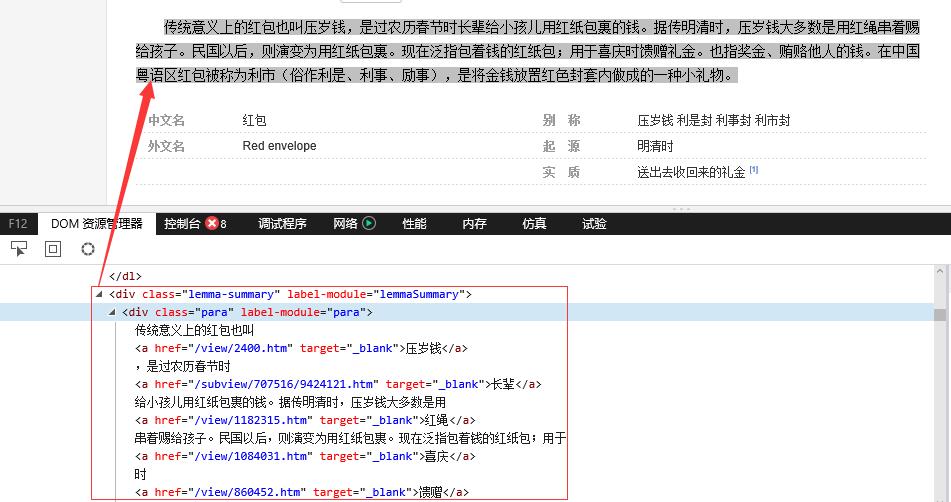
接下来,就需要使用审查元素功能查看网页的内容特征和结构。
我们编程时会用到的信息显示在下面两图中:
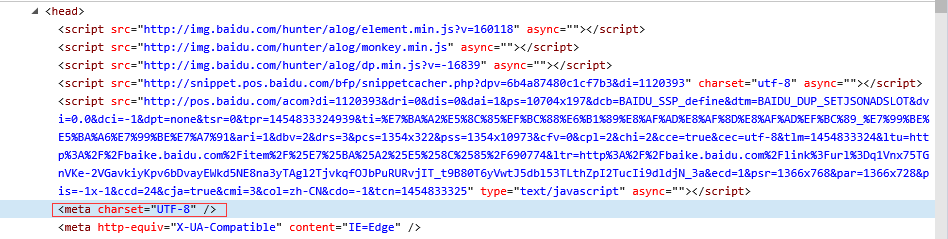
当然还有编码格式,在head部分可以找到:
现在准备工作已基本完成。我们就来开始编程工作吧!
4.非封装方式
为了便于理解,本文不采用面向对象的方式编程,但是下一篇博客我会将其整理为五个模块:爬虫调度器,数据管理器,爬虫下载器,网页分析器,内容输出器
以下代码采用循序渐进的方式呈现出来,能够体现出爬虫实现的思想历程。
- 首先导入一些有用的包
#coding:utf8
#written by python 2.7
import re
import urlparse
import urllib
from BeautifulSoup import BeautifulSoup
author = 'Meditator_hkx'- 完成基本网页内容下载
#coding:utf8
#written by python 2.7
import re
import urlparse
import urllib
from BeautifulSoup import BeautifulSoup
author = 'Meditator_hkx'
url = raw_input('Enter-') #default url
if len(url) < 1 : url = 'http://baike.baidu.com/item/%E7%BA%A2%E5%8C%85/690774'
##Download and Prettify Using BeautifulSoup
response = urllib.urlopen(url)
data = response.read()
soup = BeautifulSoup(data)
#print soup.prettify()
print soup #test crawing运行程序,直接按Enter选择默认url执行程序,结果如下图所示:
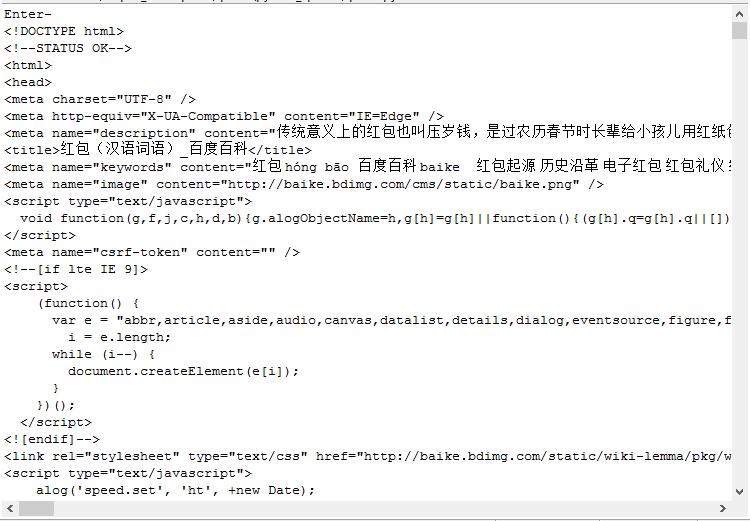
可知爬虫爬取成功,中文能够正确显示。
接下来我们将从该页面中提取标题和内容简介,这就必须用到预热分析中的标注内容。
- 存储网页关键数据
#coding:utf8
#written by python 2.7
import re
import urlparse
import urllib
from BeautifulSoup import BeautifulSoup
author = 'Meditator_hkx'
data_want = dict() #Used to store data contained in one url
data_list = list() #Used to store all data as list
url = raw_input('Enter-')
if len(url) < 1 : url = 'http://baike.baidu.com/item/%E7%BA%A2%E5%8C%85/690774'
##Down 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2269
2269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









