







本文目录
iproute2是一个软件包,这个软件包包含了多种用于高级路由,隧道和流量控制配置工具软件。
iproute2提供了Linux内核对QoS的实现,你可以在以下网站中找到英文原版的信息osdl.org和lartc.org。这些工具软件中,最重要的当数ip和tc这二个工具。
1、网络配置: "ip"工具
ip工具提供了Linux网络配置所需要的大部分功能。通过它,你可以配置网络接口, ARP,路由策略,隧道等等。ip工具支持IPv4和IPv6,并且它的语法简单易懂。最重要的是我们要学会在什么时候使用这个工具来完成什么功能。
首先,ip工具可以用于配置 动态路由协议(BGP, OSPF, and RIP) 。
我们可以通过ip help来查看一下ip工具支持哪些功能。
xxx@raspberrypi:~ $ ip help
Usage: ip [ OPTIONS ] OBJECT { COMMAND | help }
ip [ -force ] -batch filename
where OBJECT := { link | address | addrlabel | route | rule | neigh | ntable |
tunnel | tuntap | maddress | mroute | mrule | monitor | xfrm |
netns | l2tp | fou | macsec | tcp_metrics | token | netconf | ila |
vrf | sr | nexthop | mptcp }
OPTIONS := { -V[ersion] | -s[tatistics] | -d[etails] | -r[esolve] |
-h[uman-readable] | -iec | -j[son] | -p[retty] |
-f[amily] { inet | inet6 | mpls | bridge | link } |
-4 | -6 | -I | -D | -M | -B | -0 |
-l[oops] { maximum-addr-flush-attempts } | -br[ief] |
-o[neline] | -t[imestamp] | -ts[hort] | -b[atch] [filename] |
-rc[vbuf] [size] | -n[etns] name | -N[umeric] | -a[ll] |
-c[olor]}
-
ip link命令:
显示出所有可以用ip link set命令去修改的配置项。本命令用于修改网络接口设备的属性,但不能用于修改IP地址。 -
ip addr命令
显示所有网络接口设备的IP地址(等同于ip addr show)。ip addr add命令可以用于给网络接口设置增加主或者第二IP地址。ip addr del命令用于删除网络接口设备的IP地址。还有其它一些用途,比如ip addr flush dynamic命令可以直接清除掉所有通过动态路由协议添加到内核的路由表项。 -
ip neighbor命令
用于管理Arp表,它包含了add, change, replace, delete和flush多个子功能。 -
ip tunnel命令
用于管理隧道连接。支持gre, ipip和sit等多种隧道协议。用于创建管理隧道。 -
ip monitor命令
ip工具提供了实时查看路由,地址,设备状态的的功能。 -
ip route命令
此命令用于对内核的路由表进行操作,包括add, change, replace, delete, show, flush和get等功能。 -
ip rule命令
iproute2还有一个非常重要的功能就是它能通过ip rule和ip route二种命令实现策略路由。
2、流量控制工具Traffic Control: tc工具
tc工具让使用Linux来代替昂贵的QoS设备成为可能,因为tc工具可以让工程师在Linux主机上配置各种QoS策略。Linux甚至比常用的QoS设备支持更多的QoS功能,这使得我们用Linux机器当做便宜又强大的QoS设备。这个的前提是你的Linux发行版的内核在编译里已经支持QoS选项(CONFIG_NET_QOS=“Y” 和 CONFIG_NET_SCHED=“Y”,这个一般目前能拿到的通用的Linux发行版都是默认打开的,如果你自己编译内核才需要注意这二个配置)。
2.1、流量整形:Queuing Packets(也称做traffic shaping)
Linux系统里,使用Queuing队列机制来决定数据如何被发送,比如控制发送数据包的速度与多少,控制数据包发送的优先级等等。注意队列机制只能用于管理发出的数据包,不能用来管理收到的数据包(这个很好理解,收到的数据包的多少与速度是由发送发决定的,接收方只能被动接收)。如下图所示:我们可以看到,在路由器上,我们只能控制上下行二个方向的发送的QoS。
- 下行方向
路由器只能控制路由器从网口eth1 向PC发送的数据包; - 上行方向
路由器只能控制路由器从网口eth0向网络上的服务器发送的数据包。
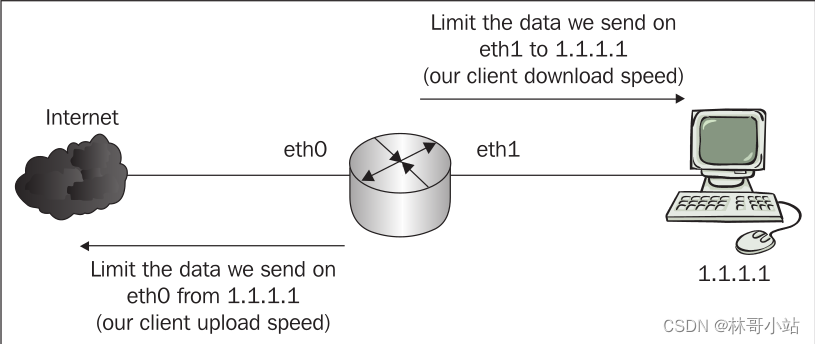
虽然只能控制发送一个方向的数据流量,但考虑到TCP协议的流控功能 (即:通信双方能通过TCP协议的ACK报文的发送来控制对方的发包速度),控制发送速度与数量就可以达到很好的双向流量整形的效果。UDP不支持协议层面上的流量控制,但大多数基于UDP协议的上层应用层协议带了流量控制功能,所以同样可以达到流量整形的效果。
但因为只能控制发送方向的数据,不能控制接收方向数据包的QoS,还是带来一些问题,比如泛洪攻击flood attacks导致的DoS的存在就是因为无法控制接收方向上的数据包的多少与速度。
用于流量整形的队列机制queuing disciplines可以分成二种,classless和classful。
开始讨论这二种Qdiscs之前,让我们来回顾一下qdiscs工作在哪里,ingress Qdiscs工作在进入Linux的TCP/IP协议栈之前, egress Qdiscs工作在报文出了CP/IP协议栈之后。
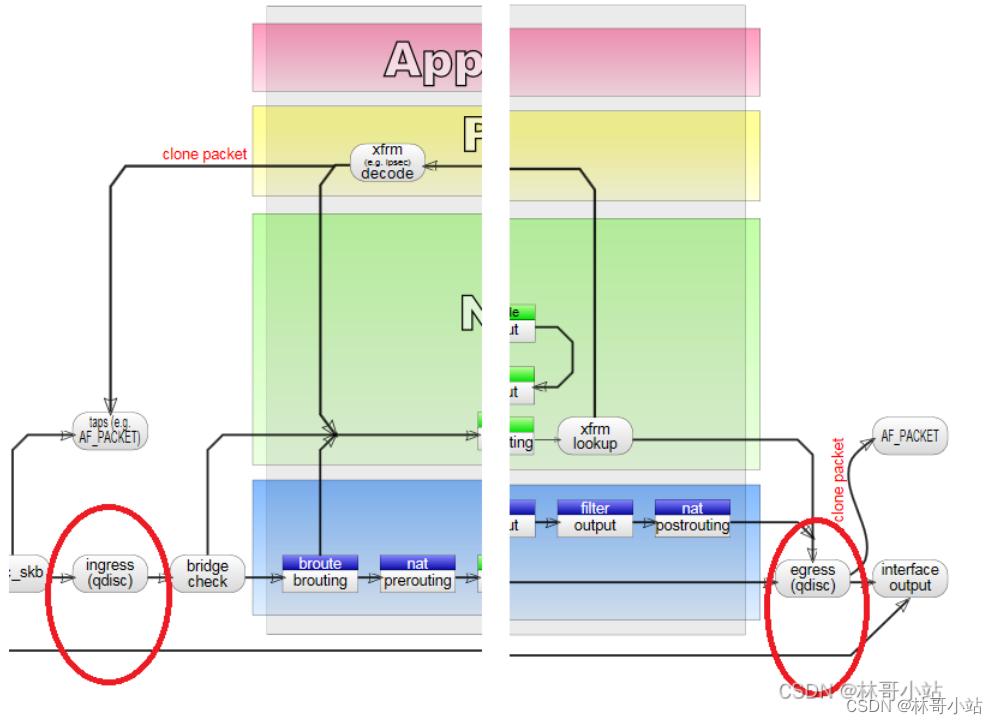
2.2、Classless Queuing Disciplines (Classless qdiscs)无分类Qdiscs
Classless qdiscs只支持最简单的规则,比如accept, drop, delay 或者 reschedule数据包。这个classless Qdiscs可以被配置在一个网络接口设备上,也只能对该网络接口设备上的所有数据包做整形,不知道对数据包和流量作分类整形。
Linux内核支持以下几种classless Qdiscs:
- FIFO (pfifo 和 bfifo):
最基本的qdisc, 这个只支持最基本的先进先出原则。FIFO算法分成二类,如果是pfifo, 那么它定义了一个队列长度限制;如果是bfifo, 那么它定义了一个缓冲区字节长度限制。 - pfifo_fast:
这个是Linux网络接口设备默认的Qdisc。后面我们会详解pfifo_fast的具体工作原理。 - Token Bucket Filter (tbf):
这个通常被称为令牌桶,用于限定某个网络接口设备的发送速率。这个机制允许短时间的超出限制,称为burst,是一种CPU占用率友好型的Qdisc。 - Stochastic Fair Queuing (SFQ):
这是使用最为广泛的Qdisc。SFQ的原则是尽可能公平合理的调度传输多个数据流flow上的数据包。 - Enhanced Stochastic Fair Queuing (ESFQ):
非Linux内核原生支持的Qdisc,它的工作原理与SFQ相似,但为用户提供了更多配置项如depth (flows) limit, hash table size options (SFQ中这个参数是固定值)和 hash types等,以让用户可以更好的控制流量。 - Random Early Detection and Generic Random Early Detection (RED and GRED):
一种适用于骨干网的qdiscs。
除了上面列出来的Qdisc之外,还有很多各种流量整形的方法。通常SFQ和ESFQ能对流量做出非常好的整形和控制效果。
Linux默认的Qdisc是pfifo_fast。 它是一种以数据包为单位的先进先出的机制,但实际上,它之所以被称为_fast是因为它提供了三个等级,0, 1和 2, 数据包按照TOS字节的值被分成这三个等级。然后以下面的规则进行发送:
- 定义为0级的报文拥有最高的优先级
- 定义为1级的报文,只有在定义为0级的报文全部发送完毕后才能被发送
- 定义为2级的报文的优先级最低,只有定义为0和1的所有报文全部发送完毕后才能被发送
如下图我们可以看到系统是数据根据每个报文的TOS将数据包映射为0,1,2三个级别的:
 TOS字节里,3-6bits被定义为TOS比特,每个bit的意义的定义如下:
TOS字节里,3-6bits被定义为TOS比特,每个bit的意义的定义如下:

然后按下表,映射成3个等级:
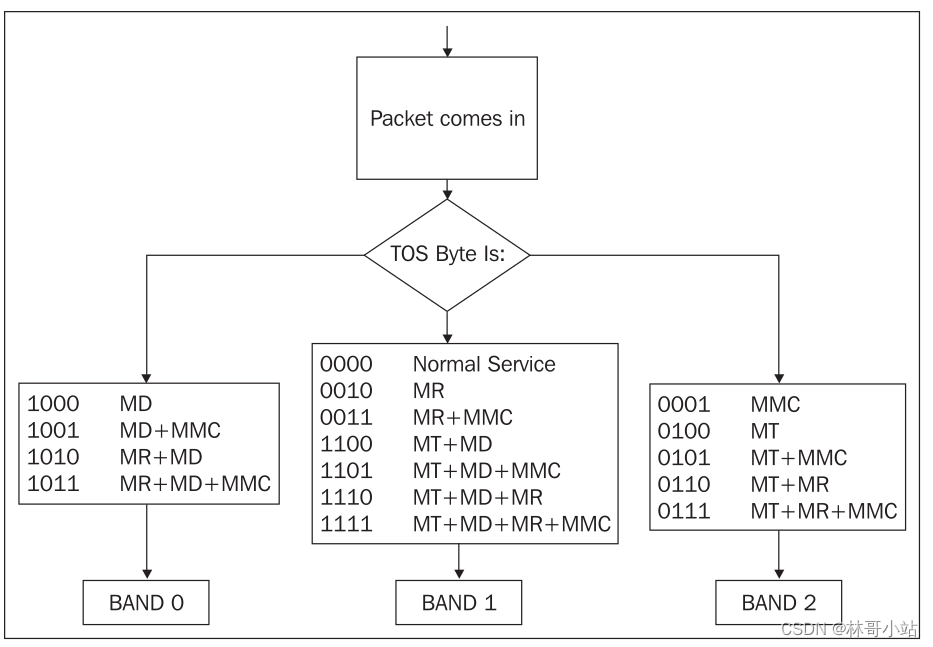 由于Linux默认使用pfifo_fast这种Qdisc,所以Linux是会根据数据包的TOS字节定义的优先级进行传输的,通常,类似Telnet, FTP, SMTP这些协议就是通过定义TOS 字节来优化传输效率的。
由于Linux默认使用pfifo_fast这种Qdisc,所以Linux是会根据数据包的TOS字节定义的优先级进行传输的,通常,类似Telnet, FTP, SMTP这些协议就是通过定义TOS 字节来优化传输效率的。
2.3、 Classful Queuing Disciplines (Classfull qdiscs)
分类classful qdiscs用于对不同类型的数据流进行分类整形,按流据流类型的不同,提供不同的QoS服务。最觉的classful qdiscs是CBQ (Class Based Queuing,基于流类型的流量整形)和HTB (Hierarchical Token Bucket分层令牌桶)。
首先,我们来理解一下classful queuing disciplines 是怎么工作的。第一个是分层,每个网络接口设备都有一个root qdisc。其次,有一个子类child class附属于这个root qdisc。 这个子分类child class有自己的一个或者多个子子分类child classes,每人子子类又有自己的去真正配置如何进行数据包的传输调度qdiscs和一个或者多个的叶子分类leaf classes。如下图所示的一个5层结构:
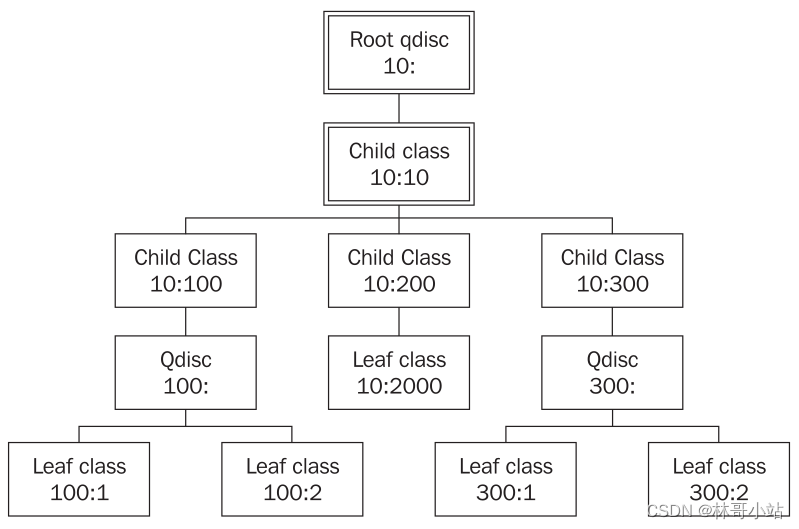
所以CBQ 或者 HTB qdiscs 允许我们去创建自己的CBQ 或 HTB子分类 classes,以支持对不同的数据流进行不同的数据整形QoS服务。
3、tc的 qdisc, class和filter三个概念之间的关系
上图中显示的树状层次关系配置,我们需要用到以下tc命令:
- tc qdisc
配置queuing disciplines. - tc class
配置classes. - tc filter
配置filters, 用于对数据流进行分类
我们可以通过调整CBQ 和 HTB的参数,来优化它们的性能。在本文中可以看到针对不同的App产生的不同流量,我们使用了不同的参数。
CBQ 的qdiscs和classes命令格式如下:
xxx@xxx-OptiPlex-3080:~$ tc qdisc add cbq help
Usage: ... cbq bandwidth BPS avpkt BYTES [ mpu BYTES ]
[ cell BYTES ] [ ewma LOG ]
xxx@xxx-OptiPlex-3080:~$ tc class add cbq help
Usage: ... cbq bandwidth BPS rate BPS maxburst PKTS [ avpkt BYTES ]
[ minburst PKTS ] [ bounded ] [ isolated ]
[ allot BYTES ] [ mpu BYTES ] [ weight RATE ]
[ prio NUMBER ] [ cell BYTES ] [ ewma LOG ]
[ estimator INTERVAL TIME_CONSTANT ]
[ split CLASSID ] [ defmap MASK/CHANGE ]
[ overhead BYTES ] [ linklayer TYPE ]
HBQ 的qdiscs和classes命令格式如下:
xxx@xxx-OptiPlex-3080:~$ tc qdisc add htb help
What is "help"?
Usage: ... qdisc add ... htb [default N] [r2q N]
[direct_qlen P] [offload]
default minor id of class to which unclassified packets are sent {0}
r2q DRR quantums are computed as rate in Bps/r2q {10}
debug string of 16 numbers each 0-3 {0}
direct_qlen Limit of the direct queue {in packets}
offload enable hardware offload
... class add ... htb rate R1 [burst B1] [mpu B] [overhead O]
[prio P] [slot S] [pslot PS]
[ceil R2] [cburst B2] [mtu MTU] [quantum Q]
rate rate allocated to this class (class can still borrow)
burst max bytes burst which can be accumulated during idle period {computed}
mpu minimum packet size used in rate computations
overhead per-packet size overhead used in rate computations
linklay adapting to a linklayer e.g. atm
ceil definite upper class rate (no borrows) {rate}
cburst burst but for ceil {computed}
mtu max packet size we create rate map for {1600}
prio priority of leaf; lower are served first {0}
quantum how much bytes to serve from leaf at once {use r2q}
TC HTB version 3.3
xxx@xxx-OptiPlex-3080:~$ tc class add htb help
Usage: ... qdisc add ... htb [default N] [r2q N]
[direct_qlen P] [offload]
default minor id of class to which unclassified packets are sent {0}
r2q DRR quantums are computed as rate in Bps/r2q {10}
debug string of 16 numbers each 0-3 {0}
direct_qlen Limit of the direct queue {in packets}
offload enable hardware offload
... class add ... htb rate R1 [burst B1] [mpu B] [overhead O]
[prio P] [slot S] [pslot PS]
[ceil R2] [cburst B2] [mtu MTU] [quantum Q]
rate rate allocated to this class (class can still borrow)
burst max bytes burst which can be accumulated during idle period {computed}
mpu minimum packet size used in rate computations
overhead per-packet size overhead used in rate computations
linklay adapting to a linklayer e.g. atm
ceil definite upper class rate (no borrows) {rate}
cburst burst but for ceil {computed}
mtu max packet size we create rate map for {1600}
prio priority of leaf; lower are served first {0}
quantum how much bytes to serve from leaf at once {use r2q}
TC HTB version 3.3
Filters 是用于对数据流进行分类的。我们可以通过基于防火墙规则的fw classifier, 基于IP头的u32 classifier, route classifier或者rsvp/rsvp6 classifiers。
tc filter的命令格式如下:
xxx@xxx-OptiPlex-3080:~$ tc filter help
Usage: tc filter [ add | del | change | replace | show ] [ dev STRING ]
tc filter [ add | del | change | replace | show ] [ block BLOCK_INDEX ]
tc filter get dev STRING parent CLASSID protocol PROTO handle FILTERID pref PRIO FILTER_TYPE
tc filter get block BLOCK_INDEX protocol PROTO handle FILTERID pref PRIO FILTER_TYPE
[ pref PRIO ] protocol PROTO [ chain CHAIN_INDEX ]
[ estimator INTERVAL TIME_CONSTANT ]
[ root | ingress | egress | parent CLASSID ]
[ handle FILTERID ] [ [ FILTER_TYPE ] [ help | OPTIONS ] ]
tc filter show [ dev STRING ] [ root | ingress | egress | parent CLASSID ]
tc filter show [ block BLOCK_INDEX ]
Where:
FILTER_TYPE := { rsvp | u32 | bpf | fw | route | etc. }
FILTERID := ... format depends on classifier, see there
OPTIONS := ... try tc filter add <desired FILTER_KIND> help
一般来说,最大的需求是根据源IP地址,目标IP地址,源端口,目标端口来对数据流进行分类,所以最常用的classifier是u32 classifier。本文中,我们会同时使用fw classifier和u32 classifier。
u32 classifier 的命令参数如下:
xxx@xxx-OptiPlex-3080:~$ tc filter add u32 help
Usage: ... u32 [ match SELECTOR ... ] [ link HTID ] [ classid CLASSID ]
[ action ACTION_SPEC ] [ offset OFFSET_SPEC ]
[ ht HTID ] [ hashkey HASHKEY_SPEC ]
[ sample SAMPLE ] [skip_hw | skip_sw]
or u32 divisor DIVISOR
Where: SELECTOR := SAMPLE SAMPLE ...
SAMPLE := { ip | ip6 | udp | tcp | icmp | u{32|16|8} | mark }
SAMPLE_ARGS [ divisor DIVISOR ]
FILTERID := X:Y:Z
NOTE: CLASSID is parsed at hexadecimal input.
fw classifier的命令参数格式如下:
wangsheng@wangsheng-OptiPlex-3080:~$ tc filter add fw help
Usage: ... fw [ classid CLASSID ] [ indev DEV ] [ action ACTION_SPEC ]
CLASSID := Push matching packets to the class identified by CLASSID with format X:Y
CLASSID is parsed as hexadecimal input.
DEV := specify device for incoming device classification.
ACTION_SPEC := Apply an action on matching packets.
NOTE: handle is represented as HANDLE[/FWMASK].
FWMASK is 0xffffffff by default.
3.1、一个详细配置例子
如下图,我们准备将10M带宽分给home-user, office和 另外一个网络三者去使用,如下图所示:
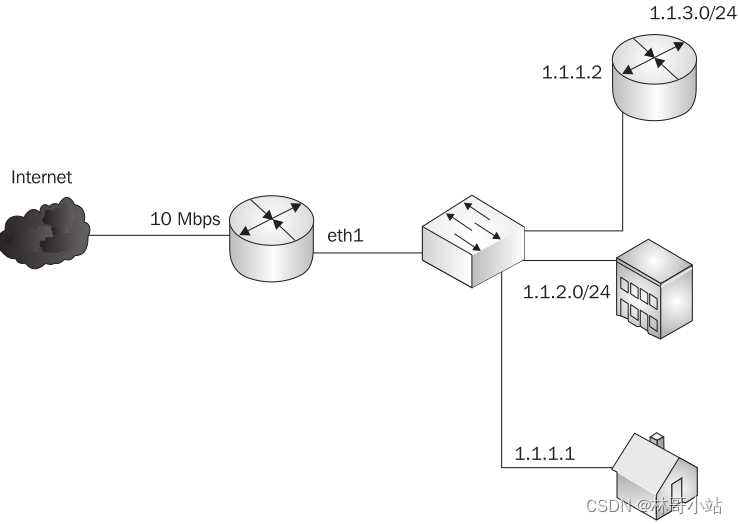

我们准备给home user 分配1Mbps带宽,给office分配4Mbps带宽,给另外一个网络分配5Mbps带宽。
3.1.1、下面我们看一下用CBQ如何来实现。
- 第一步,我们在eth1网卡下添加root qdisc:
tc qdisc add dev eth1 root handle 10: cbq bandwidth 100Mbit avpkt 1000
这条命令用于
- 在设备eth1下增加一个Qdisc。
- root这个参数表示这是一个root qdisc。
- 然后把这个root qdisc的handle设置成10。
- cbq 表示root qdics 的类型是cbq。
- bandwidth设置带宽成100Mbps,表示当前网络接口上的网络的最大带宽
- avpkt表示报文的平均长度为1000
- 第二步,创建child class
这个子类是所有其它类的父节点。这个child class的带宽是等于root qdisc的带宽的,与网络最大可用带宽一至。
tc class add dev eth1 parent 10:0 classid 10:10 cbq bandwidth 100Mbit rate 100Mbit allot 1514 weight 10Mbit prio 5 maxburst 20 avpkt 1000 bounded
-
配置child classes的parent class,它是10:0,在这里是指root class。
-
配置classid 10:10
-
可用带宽100Mbit
-
rate参数,限制可用带宽为100Mbps。
-
allot参数:定义一次当着class可以发送的数据量。
-
weight参数:是给CBQ使用的,CBQ会用这个参数和allot参数去计算一次可以发送的数据量,定义了以字节为单位的数据发送速率。
注意本文中只用到了bandwidth, rate和weight三个参数, 如果你有其它参数的问题的话,请自行查阅http://www.lartc.org/howto/lartc.qdisc.classful.html#AEN939
- 第三步,针对这里的家用电脑,办公室和子网络,我们为它们各定义一个leaf classes, qdiscs 和 filters
- 为家用电脑定义:
tc class add dev eth1 parent 10:10 classid 10:100 cbq bandwidth 100Mbit rate 1Mbit allot 1514 weight 128Kbit prio 5 maxburst 20 avpkt 1000 bounded
tc qdisc add dev eth1 parent 10:100 sfq quantum 1514b perturb 15
tc filter add dev eth1 parent 10:0 protocol ip prio 5 u32 match ip dst 1.1.1.1 flowid 10:100
我们先创建一个叫10:100的child class(这个class的rate是1Mbit, weight是128Kbit。然后,我们把一个sfq的qdisc和一个过滤目标地址为1.1.1.1的u32 filter挂在这个10:100的class下。 bounded参数表示这个class 10:100最大速率不会超过1Mbps。
- 为办公室定义:
#the office
tc class add dev eth1 parent 10:10 classid 10:200 cbq bandwidth 100Mbit rate 4Mbit allot 1514 weight 512Kbit prio 5 maxburst 20 avpkt 1000 bounded
tc qdisc add dev eth1 parent 10:200 sfq quantum 1514b perturb 15
tc filter add dev eth1 parent 10:0 protocol ip prio 5 u32 match ip dst 1.1.2.0/24 flowid 10:200
- 为子网络定义:
#the ISP
tc class add dev eth1 parent 10:10 classid 10:300 cbq bandwidth 100Mbit rate 5Mbit allot 1514 weight 640Kbit prio 5 maxburst 20 avpkt 1000 bounded
tc qdisc add dev eth1 parent 10:300 sfq quantum 1514b perturb 15
tc filter add dev eth1 parent 10:0 protocol ip prio 5 u32 match ip dst 1.1.1.2 flowid 10:300
tc filter add dev eth1 parent 10:0 protocol ip prio 5 u32 match ip dst 1.1.3.0/24 flowid 10:300
在子网终的例子里,我们可以看到,多个filters可以被加入到同一个class里。
- 验证我们的配置
使用tc class show dev eth1 命令来查看:
root@router:~# tc class show dev eth1
class cbq 10: root rate 100000Kbit (bounded,isolated) prio no-transmit
class cbq 10:100 parent 10:10 leaf 806e: rate 1000Kbit (bounded) prio 5
class cbq 10:10 parent 10: rate 100000Kbit (bounded) prio 5
class cbq 10:200 parent 10:10 leaf 806f: rate 4000Kbit (bounded) prio 5
class cbq 10:300 parent 10:10 leaf 8070: rate 5000Kbit (bounded) prio 5
现在我们可以看出来,class是用来做流量整形的,我们发送3个ping报文到1.1.1.1, 然后使用tc -s class show dev eth1命令去查看CBQ class是不是命中了这三个报文。
root@router:~# tc -s class show dev eth1 | fgrep -A 2 10:100
class cbq 10:100 parent 10:10 leaf 806e: rate 1000Kbit (bounded) prio 5
Sent 294 bytes 3 pkts (dropped 0, overlimits 0)
borrowed 0 overactions 0 avgidle 184151 undertime 0
我们可以看到,所有的配置都正常生效了。
3.1.2、下面我们看一下用HTB如何来实现。
- 删除之前添加的CBQ root qdisc:
root@router:~# tc qdisc del root dev eth1
- 添加HTB的root qdisc:
tc qdisc add dev eth1 root handle 10: htb
- 创建child class 10:10
tc class add dev eth1 parent 10:0 classid 10:10 htb rate 100Mbit
- 为家用电脑,办公室室和子网络创建class, qdisc和filter:
# home user
tc class add dev eth1 parent 10:10 classid 10:100 htb rate 1Mbit
tc qdisc add dev eth1 parent 10:100 sfq quantum 1514b perturb 15
tc filter add dev eth1 protocol ip parent 10:0 prio 5 u32 match ip dst 1.1.1.1 flowid 10:100
#the office
tc class add dev eth1 parent 10:10 classid 10:200 htb rate 4Mbit
tc qdisc add dev eth1 parent 10:200 sfq quantum 1514b perturb 15
tc filter add dev eth1 parent 10:0 protocol ip prio 5 u32 match ip dst 1.1.2.0/24 flowid 10:200
#the ISP
tc class add dev eth1 parent 10:10 classid 10:300 htb rate 5Mbit
tc qdisc add dev eth1 parent 10:300 sfq quantum 1514b perturb 15
tc filter add dev eth1 parent 10:0 protocol ip prio 5 u32 match ip dst 1.1.1.2 flowid 10:300
tc filter add dev eth1 parent 10:0 protocol ip prio 5 u32 match ip dst 1.1.3.0/24 flowid 10:300
- 用tc class show dev eth1确认配置
root@router:~# tc class show dev eth1
class htb 10:10 root rate 100000Kbit ceil 100000Kbit burst 126575b cburst 126575b
class htb 10:100 parent 10:10 leaf 8072: prio 0 rate 1000Kbit ceil 1000Kbit burst 2849b cburst 2849b
class htb 10:200 parent 10:10 leaf 8073: prio 0 rate 4000Kbit ceil 4000Kbit burst 6599b cburst 6599b
class htb 10:300 parent 10:10 leaf 8074: prio 0 rate 5000Kbit ceil 5000Kbit burst 7849b cburst 7849b
- 验证数据包是不是命中class
root@router:~# tc -s class show dev eth1 | fgrep -A 4 10:100
class htb 10:100 parent 10:10 leaf 8072: prio 0 rate 1000Kbit ceil
1000Kbit burst 2849b cburst 2849b
Sent 294 bytes 3 pkts (dropped 0, overlimits 0)
rate 24bit
lended: 3 borrowed: 0 giants: 0
tokens: 18048 ctokens: 18048
4、汇总
本文介绍了netfilter/iptables和iproute2。 我们如果想构建自己的防火墙的话,很重要的是理解报文是在哪里如何被分析的。所以在qdiscs工作在哪里这篇文章中,我们介绍了数据报文进入Linux后,是如何在filter, nat, mangle , raw这些table里转发的。使用iptables命令,我们可以在tables的chain里(append, insert, delete, list)规则,然后给命中这些规则的报文设置一个target (DROP, ACCEPT, REJECT, LOG) 来告诉Linux应该如何处理这些被规则命中的报文。
我们介绍了 iproute2的二个工具软件ip和tc。同时我们学习了Qdiscs的工作原理,并以CBQ和HTB这二种Qdiscs为例,讲述了如何 配置Qdiscs以实现QoS。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









