







朴素贝叶斯分类算法,基于条件概率和贝叶斯公式,不同于 kNN 算法和 ID3 决策树算法(这二者都是明确分类算法),朴素贝叶斯是一种概率意义上的分类算法。下面先说一下概率的相关知识,再阐述朴素贝叶斯分类算法的原理。
1,联合概率和条件概率:P(x) 表示 x 事件发生的概率,P(y) 表示 y 事件发生的概率,P(x,y) 表示 x 发生并且 y 也发生的联合概率,P(x|y) 表示 在 y 发生的条件下 x 发生的概率,联合概率和条件概率的关系如下:
P(x,y) = P(y)*P(x|y)
这个公式的含义也非常容易理解,在此不在赘述。
2,贝叶斯公式:由 1 可知,P(x,y) = P(y) * P(x|y),并且P(x,y) = P(x) * P(y|x),则有P(y) * P(x|y) = P(x) * P(y|x)
于是 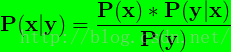
上式就是贝叶斯公式。
3,贝叶斯决策理论的核心思想:设w 表示一条数据的特征向量,w=(w1,w2,...,wn),C1表示类别一,C2表示类别二。要判断w 是属于类别C1还是属于类别C2 ,我们只需计算出P(C1|w)和P(C2|w),它们分别代表W属于类别C1和属于类别C2 的概率,
如果P(C1|w)>P(C2|w),那么w是属于类别C1。
如果P(C1|w)<P(C2|w),那么w是属于类别C2。
这就是贝叶斯决策理论的核心思想。
4,朴素贝叶斯分类算法:此算法的思想就是基于贝叶斯决策理论,但它之所以称为朴素贝叶斯算法,在于有如下两条假设。
第一个假设,特征向量w=(w1,w2,...,wn)中每个特征wi在统计学上来讲都是相互独立的,谁的出现都不依赖于 另一个谁,就像抛两次骰子,第一次的点数不依赖于第二次的点数,第二次点数也不依赖于第一次点数。
第二个假设,假设w=(w1,w2,...,wn)中的每个特征都同等重要。
虽然在现实环境中,这两个假设都不怎么成立。但也不能掩盖下面这样一个事实:朴素贝叶斯分类算法是一个效果 非常明显的分类算法,计算简单,计算出两个概率就可以搞定分类。
5,朴素贝叶斯分类算法的具体实现:由3知,我们只需计算出P(C1|w)和P(C2|w) ,那么根据贝叶斯公式易知
P(C1|w)=P(C1)*P(w|C1)/P(w)
P(C2|w)=P(C2)*P(w|C2)/P(w)
我们看出上面两个式子的分母是一样的,故只需比较二者分子的大小即可。训练集中P(C1)、P(C2)非常容易 求出。而朴素贝叶斯假设向量w=(w1,w2,...,wn)中每个特征wi之间是相互独立的。所以,
P(w|C1)=P(w1|C1)*P(w2|C1)*...*P(wn|C1)
P(w|C2)=P(w1|C2)*P(w2|C2)*...*P(wn|C2)
而P(wi|C1)、P(wi|C2)也是可以计算出来的。至此,一切都搞定。















 8445
8445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









