






目录
2. 缺失值处理(Handling Missing Values)
3. 异常值检测与处理(Outlier Detection and Treatment)
4. 数据类型转换(Data Type Conversion)
5. 数据格式统一(Data Format Standardization)
6. 重复数据处理(Dealing with Duplicate Data)
9. 记录清洗过程(Documenting the Cleaning Process)
一.了解数据清洗
数据清洗(Data Cleansing)是指对数据进行处理和纠错,以去除或修复数据集中存在的错误、不致、不完整和冗余的数据,从而使数据更加准确、可靠和有用。数据清洗是数据处理和数据分析中一个非常重要的步骤,它可以帮助我们提高数据的质量,从而提高数据分析和机器学习的准确性和可靠性。数据清洗是一个重要的过程,它可以帮助我们提高数据的质量,从而提高数据分析和机器学习的准确性和可靠性。在实际应用中,我们可以使用一些工具和技术来实现数据清洗,例如 Pandas、NumPy 和 OpenRefine 等。通过数据清洗,我们可以获得更加准确、可靠和有用的数据,从而提高数据分析和机器学习的效果。
二.数据清洗的步骤
1. 数据审查(Data Inspection)
在清洗之前,首先需要对数据进行全面的审查,以了解数据的结构、内容和质量。这包括检查数据的类型、缺失值、异常值、重复记录、格式不一致等问题。
2. 缺失值处理(Handling Missing Values)
缺失值是数据集中常见的问题。处理缺失值的方法包括:
- 删除:直接删除包含缺失值的行或列,适用于缺失值较少的情况。
- 填充:使用均值、中位数、众数或特定值(如0)填充缺失值。
- 插值:对于时间序列数据,可以使用插值方法(如线性插值)来填充缺失值。
- 预测模型:使用机器学习模型预测缺失值。
3. 异常值检测与处理(Outlier Detection and Treatment)
异常值可能是由于数据录入错误、测量误差或真实但极端的观测值。处理异常值的方法包括:
- 删除:直接删除异常值。
- 转换:对数据进行对数转换或其他数学变换,以减少异常值的影响。
- 分箱:将数据分到不同的箱子中,减少异常值的影响。
- 截断:将异常值截断到某个合理的范围。
4. 数据类型转换(Data Type Conversion)
确保数据集中所有列的数据类型正确无误,例如将字符串转换为日期格式,或将分类数据转换为数值型数据。
5. 数据格式统一(Data Format Standardization)
统一数据格式,例如日期格式、电话号码格式、地址格式等,以确保数据的一致性。
6. 重复数据处理(Dealing with Duplicate Data)
检测并处理重复的记录。重复数据可能是由于数据合并或多次录入造成的。处理方法通常是删除重复的记录。
7. 数据转换(Data Transformation)
根据分析需求,可能需要对数据进行转换,如归一化、标准化、编码(如独热编码)、分箱等。
8. 数据验证(Data Validation)
在清洗过程的每个阶段,都需要对数据进行验证,确保清洗操作没有引入新的错误。这可能包括手动检查、自动化脚本或使用统计方法。
9. 记录清洗过程(Documenting the Cleaning Process)
记录数据清洗的每一步操作,包括所做的更改、使用的工具和方法,以及任何决策的理由。这有助于未来的数据分析和审计。
10. 数据整合(Data Integration)
如果数据来自多个源,需要整合这些数据,确保数据的一致性和完整性。
11. 最终审查(Final Review)
在数据清洗完成后,进行最终审查,确保所有问题都已解决,数据已准备好用于分析。
数据清洗是一个迭代的过程,可能需要多次重复上述步骤,直到数据集达到可接受的质量标准。在实际操作中,数据清洗可能涉及复杂的逻辑和算法,需要结合领域知识和数据分析技能来完成。
三.认识数据清洗的工具
数据清洗是数据处理过程中的一个关键步骤,需要使用专门的工具来提高效率和准确性。以下是一些常用的数据清洗工具:
1. Excel
Excel是许多人们开始数据清洗的工具,它提供了基本的数据清洗功能,如查找和替换、条件格式、数据验证、文本函数等。
2. OpenRefine
OpenRefine(原名Google Refine)是一款开源的数据清洗工具,支持多种数据格式,如CSV、TSV、Excel、JSON、XML等。它提供了丰富的数据清洗功能,如数据转换、数据聚合、数据标准化、重复数据处理、缺失值处理、数据校验等。
3. Pandas
Pandas是Python中的一款数据分析库,提供了强大的数据清洗功能,如数据导入导出、数据过滤、数据转换、数据聚合、缺失值处理、数据统计等。
4. Trifacta
Trifacta是一款专业的数据清id工具,提供了丰富的数据清洗功能,如数据探索、数据预处理、数据转换、数据标准化、数据校验等。
5. Talend
Talend是一款数据集成工具,提供了数据清洗功能,如数据转换、数据映射、数据校验、数据质量管理等。
6. DataCleaner
DataCleaner是一款开源的数据清洗工具,支持多种数据格式,如CSV、Excel、XML、JSON等。它提供了丰富的数据清洗功能,如数据探索、数据转换、数据标准化、数据校验、数据质量管理等。
7. R
R是一款数据分析语言,提供了丰富的数据清洗功能,如数据导入导出、数据过滤、数据转换、数据聚合、缺失值处理、数据统计等。
8. SQL
SQL是一种数据库查询语言,可以用于数据清洗,如数据过滤、数据转换、数据聚合、数据校验等。
9. Power Query
Power Query是Excel中的一款数据清洗工具,提供了数据导入导出、数据过滤、数据转换、数据聚合、数据校验等功能。
10. DataWrangler
DataWrangler是一款开源的数据清洗工具,提供了数据探索、数据转换、数据标准化、数据校验等功能。
这些工具各有优劣,可以根据实际需求和数据规模选择合适的工具进行数据清洗。
四.数据清洗的实践
通过一个完整的数据清洗项目,展示如何从数据收集、数据清洗、数据分析、数据可视化的整个过程,现在我们用电影数据集为例(film.txt)等
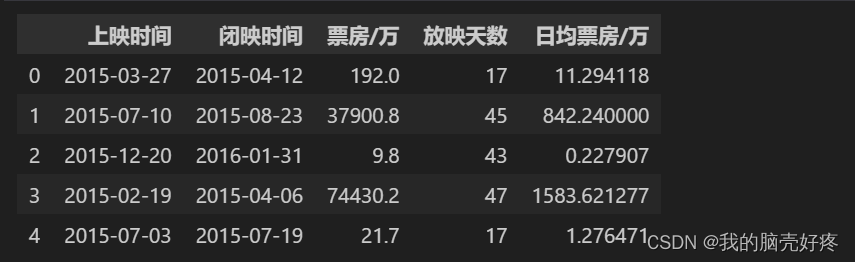
1.数据清洗
import pandas as pd
import numpy as np # 导入必要的库
# 用pandas读取文件
df = pd.read_csv('film.txt') # 假设文件名是'film.txt',
# 筛选指定内容
df = df[['上映时间', '闭映时间', '票房/万']]
# 除去带有空值的行
df = df.dropna(subset=['上映时间', '闭映时间', '票房/万'])
# 将'上映时间'和'闭映时间'列转换为时间类型
df[['上映时间', '闭映时间']] = pd.to_datetime(df[['上映时间', '闭映时间']])
# 计算电影放映天数
df['放映天数'] = (df['闭映时间'] - df['上映时间']).dt.days
# 票房数据转换为浮点型
df['票房/万'] = df['票房/万'].astype(float)
# 删除不符合条件的电影(例如,放映天数过少)
min_days = 7 # 设定最小放映天数为7天
df = df[df['放映天数'] >= min_days]
# 计算日均票房
df['日均票房'] = df['票房/万'] / df['放映天数']
# 重置索引列,不添加新的列
df = df.reset_index(drop=True)
# 显示前5行
df.head()
运行结果如下:
2.使用scikit-learn线性回归模型分析
import pandas as pd
from sklearn.linear_model import LinearRegression
# 用pandas读取文件
df = pd.read_csv('film.txt') # 假设文件名是'film.txt',请替换为实际文件名
# 筛选指定内容
df = df[['上映时间', '闭映时间', '票房/万']]
# 除去带有空值的行
df = df.dropna(subset=['上映时间', '闭映时间', '票房/万'])
# 将'上映时间'和'闭映时间'列转换为时间类型
df[['上映时间', '闭映时间']] = pd.to_datetime(df[['上映时间', '闭映时间']])
# 计算电影放映天数
df['放映天数'] = (df['闭映时间'] - df['上映时间']).dt.days
# 票房数据转换为浮点型
df['票房/万'] = df['票房/万'].astype(float)
# 删除不符合条件的电影(例如,放映天数过少)
min_days = 7 # 设定最小放映天数为7天
df = df[df['放映天数'] >= min_days]
# 计算日均票房
df['日均票房'] = df['票房/万'] / df['放映天数']
# 重置索引列,不添加新的列
df = df.reset_index(drop=True)
# 设定x和y的值
x = df[['放映天数']]
y = df[['日均票房']]
# 初始化线性回归模型
model = LinearRegression()
# 拟合模型
model.fit(x, y)
# 输出系数和截距
print('系数:', model.coef_[0])
print('截距:', model.intercept_)
运行结果如下:

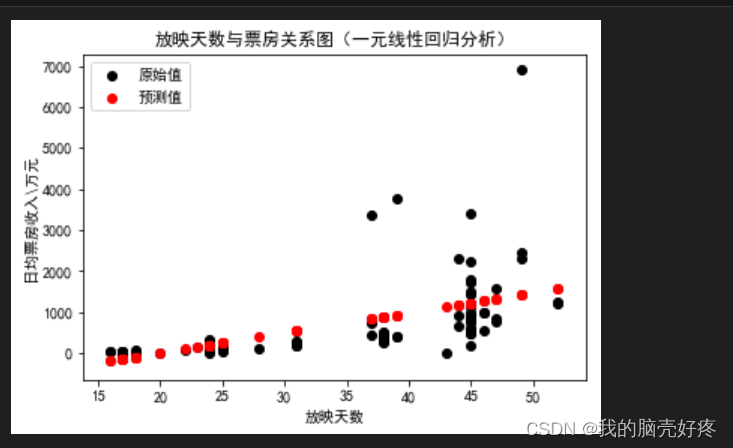
3.在完成线性回归模型拟合后,我们可以使用matplotlib来绘制散点图和回归线。以下是完整的代码:
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 假设我们已经保存了模型和数据
x = df[['放映天数']]
y = df[['日均票房']]
# 初始化线性回归模型
model = LinearRegression()
model.fit(x, y)
# 预测值
y_pred = model.predict(x)
# 可视化
plt.figure(figsize=(10, 6)) # 设置图形大小
# 画出原始点
plt.scatter(x['放映天数'], y['日均票房'], color='blue', label='原始值')
# 画出预测点,预测点的宽度为1,颜色为红色
plt.plot(x['放映天数'], y_pred, color='red', linewidth=1, label='预测值')
# 定义图表标题等
plt.title('放映天数与票房关系图(一元线性回归分析)')
plt.xlabel('放映天数')
plt.ylabel('日均票房收入\\万元')
# 设置图例
plt.legend(['原始值', '预测值'], loc='upper right')
# 显示图形
plt.show()
运行结果如下:
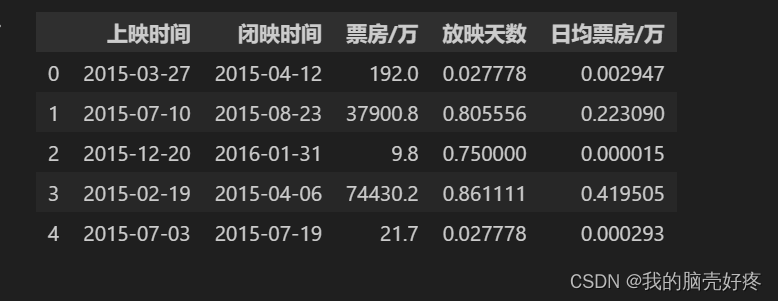
4.归一化处理:
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
df = pd.read_csv('film.txt')
# 对数据集进行归一化处理
scaler = MinMaxScaler()
df_normalized = pd.DataFrame(scaler.fit_transform(df[['放映天数', '日均票房']]), columns=['放映天数', '日均票房'])
# 显示前5行归一化后的数据集
print(df_normalized.head())
# 接下来,可以使用前面提到的Z分数方法来识别和去除数据集中的奇异点
z_scores = stats.zscore(df_normalized[['放映天数', '日均票房']]))
threshold = 3
mask = (z_scores < threshold).all(axis=1)
df_filtered = df_normalized[mask]
print(df_filtered.head())
运行结果如下:
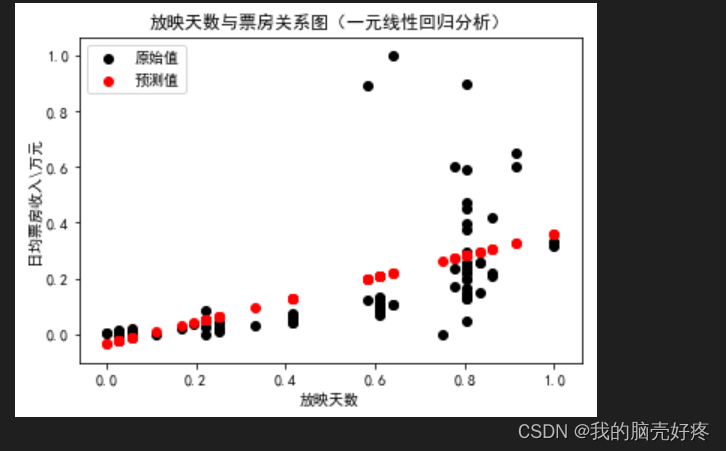
5.重新拟合:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn import linear_model
df = pd.read_csv('film.txt')
# 对数据集进行归一化处理
scaler = MinMaxScaler()
df_normalized = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
# 提取特征和目标变量
x = df_normalized[['放映天数']]
y = df_normalized[['日均票房/万']]
# 训练线性回归模型
regr = linear_model.LinearRegression()
regr.fit(x, y)
# 绘制散点图和回归线
plt.figure(figsize=(10, 6))
plt.title('放映天数与票房关系图(一元线性回归分析)')
plt.xlabel('放映天数')
plt.ylabel('日均票房收入\\万元')
plt.scatter(x, y, color='black', label='原始值')
plt.plot(x, regr.predict(x), color='red', linewidth=1, label='预测值')
plt.legend(loc=2)
plt.show()
运行结果如下:
 6. 数据集拆分成 训练集与测试集
6. 数据集拆分成 训练集与测试集
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import linear_model
df = pd.read_csv('film.txt')
# 提取特征和目标变量
x = df[['放映天数']]
y = df[['日均票房/万']]
# 拆分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
# 建立线性回归模型
regr = linear_model.LinearRegression()
# 使用训练集进行拟合
regr.fit(x_train, y_train)
# 给出测试集的预测结果
y_pred = regr.predict(x_test)
# 绘制预测值与实际值比较的曲线
plt.figure(figsize=(10, 6))
plt.title(u'预测值与实际值比较(一元线性回归)')
plt.xlabel(u'样本编号')
plt.ylabel(u'日均票房收入\\万元')
plt.plot(range(len(y_test)), y_test, 'r-', label='实际值')
plt.plot(range(len(y_test)), y_pred, 'b-', label='预测值')
plt.legend()
plt.show()
运行结果如下: 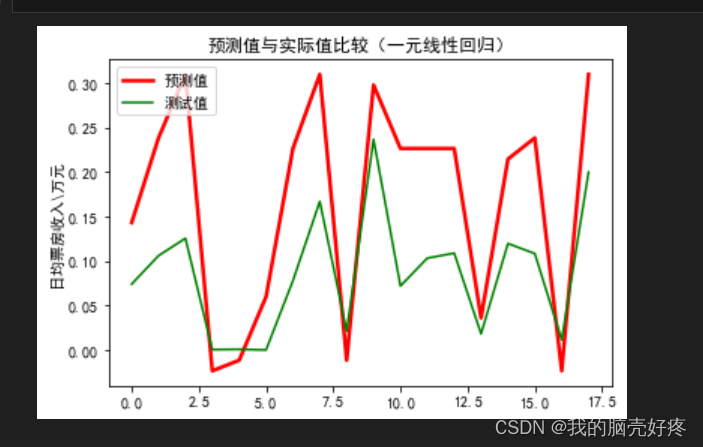
五.数据清洗的总结
数据清洗是数据预处理的一部分,旨在识别和处理不完整、不准确或不合理的数据。以下是数据清洗的总结:
-
导入数据:首先,我们需要导入数据集,可以使用像
pandas这样的库来加载数据。 -
探索数据:对数据进行初步探索,例如查看数据集的形状、数据类型和结构。
-
识别缺失值:识别数据集中的缺失值,可以使用
pandas的isnull()函数。 -
处理缺失值:根据数据集的特点和需求,决定如何处理缺失值。可以使用以下方法之一:
- 删除:如果缺失值的比例很小,可以直接删除包含缺失值的行或列。
- 插值:可以使用其他数据点的值来估计缺失值,例如使用前后几个数据点的平均值。
- 预测:如果数据集中有大量的缺失值,可以使用机器学习算法来预测缺失值。
-
识别异常值:识别数据集中的异常值,可以使用描述性统计和可视化技术。
-
处理异常值:根据数据集的特点和需求,决定如何处理异常值。可以使用以下方法之一:
- 删除:如果异常值的比例很小,可以直接删除包含异常值的行或列。
- 修正:如果异常值是输入错误,可以修正它们。
- 保留:如果异常值代表某种特殊情况,可以将它们保留下来。
-
验证数据:对数据进行最后的验证,确保数据集是干净、准确和可靠的。
-
导出数据:将数据集导出到可以用于机器学习算法的格式中。
数据清洗是一项重要的任务,需要仔细地处理,以确保数据集的准确性和可靠性。
9.数据清洗的难点
最后,可以谈谈数据清洗中的一些难点和挑战,例如数据量过大或过小、数据质量不好、数据的可靠性和完整性等。可以提供一些解决这些问题的方法和技巧。例如,我们可以使用数据采样来处理大规模数据,使用数据校验来提高数据的可靠性和完整性,使用数据归一化和数据标准化来提高数据的一致性。
本文链接:写文章-CSDN创作中心 https://mp.csdn.net/mp_blog/creation/editor?spm=1001.2100.3001.5352
https://mp.csdn.net/mp_blog/creation/editor?spm=1001.2100.3001.5352

















 1271
1271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









