



物理级精确仿真正成为数字孪生落地的核心驱动力,而显存资源的高效管理是保障大规模实时模拟的关键瓶颈。
在工业元宇宙与数字孪生技术迅猛发展的今天,NVIDIA Omniverse平台凭借其物理级精确仿真能力和OpenUSD开放式工作流,已成为构建工业数字孪生的核心基础设施。对于高校研究团队而言,深入理解Omniverse物理引擎的GPU显存消耗规律,尤其是显存预分配策略,对优化大规模数字孪生场景的实时仿真效率至关重要。
本文将结合架构原理与实测策略,剖析Omniverse在数字孪生应用中的显存管理机制。
01 物理引擎与数字孪生的算力挑战
数字孪生技术的本质是通过虚实映射与闭环交互实现物理世界的动态镜像。其核心要素包括物理实体、虚拟模型、数据、连接和服务。Omniverse作为支撑数字孪生的物理仿真引擎,需实时处理三大算力密集型任务:
- 刚体/软体动力学计算:模拟机械碰撞、材料形变等连续物理过程
- 光线追踪渲染:实现亚毫米级精度的光学反射与材质表现
- AI合成数据生成:通过Replicator引擎生成带物理属性的训练数据集
这些任务对GPU显存提出双重需求:大容量与低延迟。例如宝马数字工厂项目中,Omniverse需实时处理数千台设备的运动学状态和传感器数据流,同时保持30fps以上的物理更新速率。传统动态显存分配机制(如CUDA的cudaMalloc)因系统调用开销过高,难以满足实时性要求。
02 显存预分配核心技术解析
预分配机制的核心逻辑
Omniverse借鉴了PaddlePaddle等框架的显存池化思想,采用分块预分配策略(Chunk-based Pre-allocation)
if requested_size ≤ chunk_size:
从预分配chunk中划拨显存
else:
直接调用cudaMalloc分配独立显存块
其中 chunk_size = FLAGS_fraction_of_gpu_memory_to_use * GPU总显存,该环境变量默认值为0.92,即引擎启动时立即占用92%的显存空间。这一设计将高频的小规模显存请求转化为内存指针运算,规避了操作系统级的显存申请延迟。
关键调节参数
- FLAGS_fraction_of_gpu_memory_to_use:降低此值可预留显存给其他并行任务,但会增大碎片化风险
- FLAGS_eager_delete_tensor_gb:设置为0时启用即时垃圾回收(GC),显存释放延迟降至毫秒级
- build_strategy.enable_inplace:开启输入输出显存复用,减少中间变量占用
优势与局限
- 优势:预分配策略使显存分配操作从μs级降至ns级,尤其利于高频更新的物理变量(如粒子位置、关节角度)。在台达电子工厂的数字孪生测试中,流水线仿真帧率提升达40%。
-
- 局限:静态分配导致显存利用率波动较大。当场景复杂度突然增加(如爆炸模拟)时,需动态扩展预分配池,可能引发5-10ms的卡顿。此时建议启用FLAGS_fraction_of_gpu_memory_to_use=0.6,为突发负载预留缓冲空间。
不同显存优化策略对比:
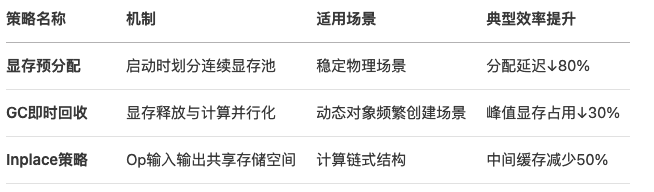
03 硬件配置与集群化扩展
单卡配置规范
Omniverse官方认证的工作站GPU需具备:
- 显存容量≥24GB:满足城市级场景的几何数据加载(如RTX 5000的32GB GDDR6)
- Tensor Core支持:加速物理方程的矩阵运算
- NVLink桥接能力:实现多卡显存池
大规模集群部署
针对工厂级或城市级数字孪生,Supermicro推出的Omniverse SuperCluster提供线性扩展能力:
单个计算单元配置:
- 32台SYS-421GE-TNRT服务器节点
- 256颗NVIDIA L40S GPU
- 400Gbps NVIDIA Spectrum-X网络
- 5机柜液冷系统:cite[9]
该架构通过NVIDIA BlueField-3 SuperNIC实现跨节点GPU显存虚拟化,使256颗GPU的显存可作为统一地址空间访问。在劳氏集团仓库仿真中,集群将百万级货架的物理状态更新延迟控制在8ms以内。
网络优化要点
- 计算与存储网络分离:避免IoT数据流挤占物理状态同步带宽
- RDMA over Converged Ethernet:通过RoCE协议实现GPU显存直接访问
- QoS策略保障:为物理引擎进程分配最高网络优先级
04 场景化显存优化实践
数字孪生场景分类
根据显存需求特征可分为:
- 静态场景(建筑/道路):几何数据占显存70%以上,建议启用USD模型分块加载
- 动态场景(机械臂/AGV):物理状态频繁更新,需增加GC回收频率
- 突变场景(碰撞/灾害):突发粒子生成,预留显存安全余量
典型优化案例
案例1:自动驾驶多传感器融合
- 挑战:16路摄像头+LiDAR点云数据显存峰值达18GB
- 策略:采用Omniverse Sensor RTX API共享传感器底层缓冲区
- 效果:显存复用率提升60%,帧率稳定在45fps
案例2:暴雨洪涝仿真
- 挑战:流体粒子数超2000万,显存需求呈指数增长
- 策略:实施动态粒子LOD,中远距离粒子降精度至4字节/粒
- 效果:显存占用量减少43%,仿真速度提升2.1倍
不同场景显存需求特征对比
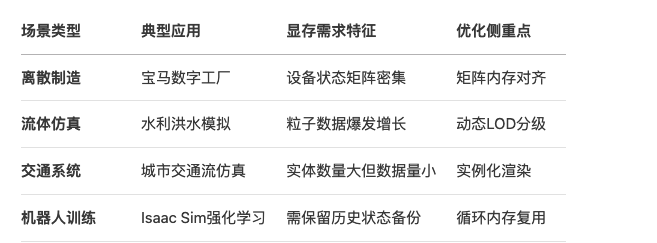
05 前沿演进趋势
随着物理AI(Physical AI)的兴起,Omniverse的显存管理正面临新挑战:
- 生成式世界模型集成:NVIDIA Cosmos通过世界基础模型(WFM) 生成物理合成数据,显存消耗增加30%-50%10
- 多模态LLM接入:大型语言模型需常驻显存,挤占物理引擎资源
- 光子级渲染演进:路径追踪采样点存储需求呈指数增长
应对方案初露端倪:
- 显存-内存分级存储:将低频访问数据(如材质库)迁移至CPU内存
- GPU解构式架构:NVIDIA Blackwell采用裸片互联技术,使显存带宽突破8TB/s
- 量子化物理计算:使用8位浮点存储物理状态(实验性精度损失<3%)
06 总结与建议
显存预分配策略是Omniverse物理引擎实现实时数字孪生的关键基础设施。通过FLAGS_fraction_of_gpu_memory_to_use等参数调节,可平衡效率与灵活性。对于研究团队,建议遵循以下实践路径:
- 基准测试先行:使用FLAGS_fraction_of_gpu_memory_to_use=0测量场景原始显存需求
- 渐进式优化:从0.6开始逐步提高预分配比例,监控帧时间标准差
- 集群化扩展:当单机显存突破80%使用率时,评估OVX架构扩展性
物理仿真正从离线计算走向实时交互,显存资源的精细化管理将成为数字孪生落地能力的分水岭。当虚拟世界中的一粒沙也需要遵循真实物理定律时,每一字节显存的优化都意味着向元宇宙终极愿景迈出坚实一步。



















 1276
1276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









