









Overview
- Amazon Aurora (Aurora) is a fully managed relational database engine that's compatible with MySQL and PostgreSQL.
- With some workloads, Aurora can deliver up to five times the throughput of MySQL and up to three times the throughput of PostgreSQL without requiring changes to most of your existing applications.
- Aurora includes a high-performance storage subsystem.The underlying storage grows automatically as needed. Aurora also automates and standardizes database clustering and replication
Amazon Aurora DB clusters
- An Amazon Aurora DB cluster consists of one or more DB instances and a cluster volume that manages the data for those DB instances.
- An Aurora cluster volume is a virtual database storage volume that spans multiple Availability Zones, with each Availability Zone having a copy of the DB cluster data.
- Two types of DB instances make up an Aurora DB cluster:
- Primary DB instance – Supports read and write operations, and performs all of the data modifications to the cluster volume. Each Aurora DB cluster has one primary DB instance.
- Aurora Replica – Connects to the same storage volume as the primary DB instance and supports only read operations.
- Each Aurora DB cluster can have up to 15 Aurora Replicas in addition to the primary DB instance.
- Maintain high availability by locating Aurora Replicas in separate Availability Zones.
- Aurora Replicas can also offload read workloads from the primary DB instance
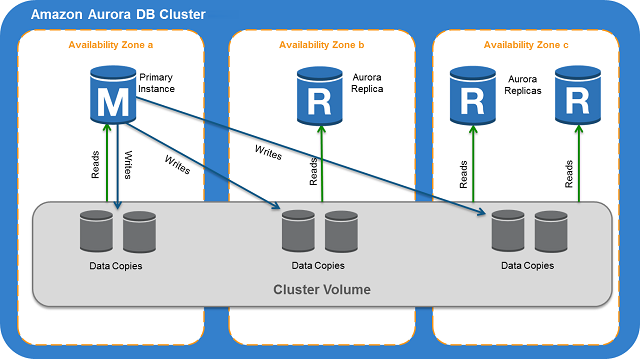
- Each Aurora DB cluster hosts copies of its storage in three separate AZs。 Every DB instance in the cluster must be in one of these three AZs。If an AWS Region has fewer than three AZs, Aurora isn't available in that Region.
Amazon Aurora connection management
- An endpoint is represented as an Aurora-specific URL that contains a host address and a port.
- When you connect to an Aurora cluster, the host name and port that you specify point to an intermediate handler called an endpoint.
- Aurora uses the endpoint mechanism to abstract these connections.
- Cluster endpoint
- A cluster endpoint (or writer endpoint) for an Aurora DB cluster connects to the current primary DB instance for that DB cluster.
- This endpoint is the only one that can perform write operations such as DDL statements.
- Each Aurora DB cluster has one cluster endpoint and one primary DB instance.
- You use the cluster endpoint for all write operations on the DB cluster, including inserts, updates, deletes, and DDL changes. You can also use the cluster endpoint for read operations, such as queries.
- If the current primary DB instance of a DB cluster fails, Aurora automatically fails over to a new primary DB instance. During a failover, the DB cluster continues to serve connection requests to the cluster endpoint from the new primary DB instance, with minimal interruption of service.
- Reader endpoint
- A reader endpoint for an Aurora DB cluster provides load-balancing support for read-only connections to the DB cluster.
- The reader endpoint load-balances connections to available Aurora Replicas in an Aurora DB cluster.
- It doesn't load-balance individual queries.
- If you want to load-balance each query to distribute the read workload for a DB cluster, open a new connection to the reader endpoint for each query.
- Use the reader endpoint for read operations, such as queries.
- Each Aurora DB cluster has one reader endpoint.
- If the cluster only contains a primary instance and no Aurora Replicas, the reader endpoint connects to the primary instance.
- A reader endpoint for an Aurora DB cluster provides load-balancing support for read-only connections to the DB cluster.
- Custom endpoint
- A custom endpoint for an Aurora cluster represents a set of DB instances that you choose.
- When you connect to the endpoint, Aurora performs load balancing and chooses one of the instances in the group to handle the connection.
- You define which instances this endpoint refers to, and you decide what purpose the endpoint serves.
- An Aurora DB cluster has no custom endpoints until you create one. You can create up to fivustom endpoints for each provisioned Aurora cluster. You can't use custom endpoints for Aurora Serverless clusters.
- With custom endpoints, you can predict the capacity of the DB instance used for each connection. When you use custom endpoints, you typically don't use the reader endpoint for that cluster.
- Instance endpoint
- An instance endpoint connects to a specific DB instance within an Aurora cluster.
- Each DB instance in a DB cluster has its own unique instance endpoint.
- The instance endpoint provides direct control over connections to the DB cluster, for scenarios where using the cluster endpoint or reader endpoint might not be appropriate.
Amazon Aurora storage and reliability
- Aurora data is stored in the cluster volume, which is a single, virtual volume that uses solid state drives (SSDs).
- A cluster volume consists of copies of the data across three Availability Zones in a single AWS Region.
- The Aurora cluster volume contains all your user data, schema objects, and internal metadata such as the system tables and the binary log
- The Aurora shared storage architecture makes your data independent from the DB instances in the cluster.
- Aurora cluster volumes automatically grow as the amount of data in your database increases. An Aurora cluster volume can grow to a maximum size of 128TB。
- Aurora is designed to be reliable, durable, and fault tolerant.
- Storage auto-repair: Aurora automatically detects failures in the disk volumes that make up the cluster volume. When a segment of a disk volume fails, Aurora immediately repairs the segment. As a result, Aurora avoids data loss and reduces the need to perform a point-in-time restore to recover from a disk failure
- Survivable cache warming: Aurora "warms" the buffer pool cache when a database starts up after it has been shut down or restarted after a failure. That is, Aurora preloads the buffer pool with the pages for known common queries that are stored in an in-memory page cache.
- Crash recovery:Aurora is designed to recover from a crash almost instantaneously and continue to serve your application data without the binary log.
- The amount of binary log data affects recovery time. If there is more data logged in the binary logs, the DB instance must process more data during recovery, which increases recovery time.
- If you don't need the binary log for external replication (or an external binary log stream), we recommend that you set the
binlog_formatparameter toOFFto disable binary logging.
High availability for Amazon Aurora
- High availability for Aurora data:When data is written to the primary DB instance, Aurora synchronously replicates the data across Availability Zones to six storage nodes associated with your cluster volume. Doing so provides data redundancy, eliminates I/O freezes, and minimizes latency spikes during system backups.
- High availability for Aurora DB instances: For a cluster using single-master replication, after you create the primary instance, you can create up to 15 read-only Aurora Replicas.
- High availability across AWS Regions with Aurora global databases:Each Aurora global database spans multiple AWS Regions, enabling low latency global reads and disaster recovery from outages across an AWS Region. Aurora automatically handles replicating all data and updates from the primary AWS Region to each of the secondary Regions
- Fault tolerance for an Aurora DB cluster:The cluster volume spans multiple Availability Zones in a single AWS Region, and each Availability Zone contains a copy of the cluster volume data. This functionality means that your DB cluster can tolerate a failure of an Availability Zone without any loss of data and only a brief interruption of service.
Configuring your Amazon Aurora DB cluster
- You can only create an Amazon Aurora DB cluster in a virtual private cloud (VPC) based on the Amazon VPC service, in an AWS Region that has at least two Availability Zones.
Using Amazon Aurora Serverless v1
- An Aurora Serverless DB cluster is a DB cluster that scales compute capacity up and down based on your application's needs.
- Aurora Serverless v1 provides a relatively simple, cost-effective option for infrequent, intermittent, or unpredictable workloads.
- The cluster volume for an Aurora Serverless v1 cluster is always encrypted. You can choose the encryption key, but you can't disable encryption.
- By using Aurora Serverless v1, you can create a database endpoint without specifying the DB instance class size. You specify only the minimum and maximum range for the Aurora Serverless v1 DB cluster's capacity.
- The Aurora Serverless v1 database endpoint makes up a router fleet that supports continuous connections and distributes the workload among resources.

- Currently, Aurora Serverless v1 tries to find a scaling point for 5 minutes (300 seconds). If Aurora Serverless can't find a scaling point within 5 minutes, the autoscaling operation times out.
- If the DB instance for an Aurora Serverless v1 DB cluster becomes unavailable or the Availability Zone (AZ) it is in fails, Aurora recreates the DB instance in a different AZ
- Aurora Serverless v1 is available in certain AWS Regions and for specific Aurora MySQL and Aurora PostgreSQL versions only.
- Aurora Serverless v1 provides the following advantages:
- Simpler than provisioned – Aurora Serverless v1 removes much of the complexity of managing DB instances and capacity.
- Scalable – Aurora Serverless v1 seamlessly scales compute and memory capacity as needed, with no disruption to client connections.
- Cost-effective – When you use Aurora Serverless v1, you pay only for the database resources that you consume, on a per-second basis.
- Highly available storage – Aurora Serverless v1 uses the same fault-tolerant, distributed storage system with six-way replication as Aurora to protect against data loss.
- Aurora Serverless v1 is designed for the following use cases:
- Infrequently used applications
- New applications
- Variable workloads
- Unpredictable workloads
- Development and test databases
- Multi-tenant applications
Using Amazon Aurora Serverless v2
- By using Amazon Aurora Serverless v2, now in preview, you can get optimal cost performance for your database clusters.
- Don't use Aurora Serverless v2 (preview) for production databases.
Using Amazon Aurora global databases
- Amazon Aurora global databases span multiple AWS Regions, enabling low latency global reads and providing fast recovery from the rare outage that might affect an entire AWS Region.
- An Aurora global database has a primary DB cluster in one Region, and up to five secondary DB clusters in different Regions.
- You issue write operations directly to the primary DB cluster in the primary AWS Region. Aurora replicates data to the secondary AWS Regions using dedicated infrastructure, with latency typically under a second.
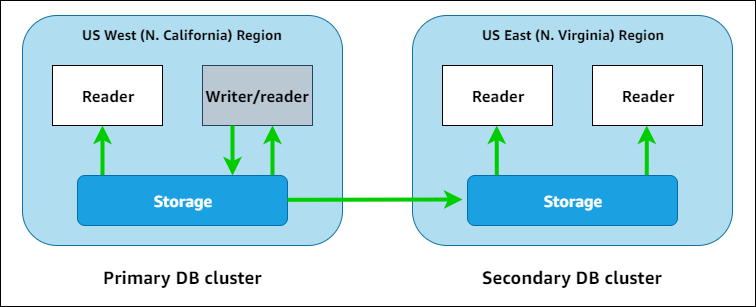
- You can scale up each secondary cluster independently, by adding one or more Aurora Replicas (read-only Aurora DB instances) to serve read-only workloads.
- Aurora global database uses the cluster storage volume and not the database engine for replication
- By using Aurora global databases, you can get the following advantages:
- Global reads with local latency
- Scalable secondary Aurora DB clusters
- Fast replication from primary to secondary Aurora DB clusters
- Recovery from Region-wide outages
Managing an Amazon Aurora DB cluster
- Stop a cluster
- You can't stop a cluster that's part of an Aurora global database, or a multi-master cluster.
- You can't stop a DB cluster that acts as the replication target for data from another DB cluster, or acts as the replication master and transmits data to another cluster.
- You can't stop an Aurora serverless cluster.
- You can't stop an individual Aurora DB instance.
- Adding Aurora Replicas
- You can't create an Aurora Replica for an Aurora Serverless v1 DB cluster.
- You can't create Aurora Replicas for an Aurora multi-master cluster. By design, an Aurora multi-master cluster has read-write DB instances only.
- Aurora PostgreSQL–based DB clusters can have only one Aurora Replica
- Aurora PostgreSQL–based DB clusters can't have Aurora Replicas in different AWS Regions. In other words, Aurora PostgreSQL doesn't support cross-region Aurora Replicas.
- By using Aurora cloning, you can quickly and cost-effectively create a new cluster that uses the same Aurora cluster volume and has the same data as the original.
- Aurora cloning works at the storage layer of an Aurora DB cluster.
- It uses a copy-on-write protocol that's both fast and space-efficient in terms of the underlying durable media supporting the Aurora storage volume.
- Avoid using clones for long-term purposes, especially those involving many writes by the source Aurora DB cluster and the clone.
- By using AWS Resource Access Manager (AWS RAM) with Amazon Aurora, you can share Aurora DB clusters and clones that belong to your AWS account with another AWS account or organization.
- To allow other AWS accounts to clone a cluster that you own, use AWS RAM to set the sharing permission.
- To meet your connectivity and workload requirements, Aurora Auto Scaling dynamically adjusts the number of Aurora Replicas provisioned for an Aurora DB cluster using single-master replication.
- target-tracking scaling policy
Backing up and restoring an Amazon Aurora DB cluster
- Aurora backs up your cluster volume automatically and retains restore data for the length of the backup retention period.
- You can specify a backup retention period, from 1 to 35 days
- Aurora backups are stored in Amazon S3.
- Automated backups occur daily during the preferred backup window.
- Aurora backups are continuous and incremental, but the backup window is used to create a daily system backup that is preserved within the backup retention period. You can copy it to preserve it outside of the retention period.
- You can recover your data by creating a new Aurora DB cluster from the backup data that Aurora retains, or from a DB cluster snapshot that you have saved.
Best practices with Amazon Aurora
- Monitor your memory, CPU, and storage usage.
- If your client application is caching the Domain Name Service (DNS) data of your DB instances, set a time-to-live (TTL) value of less than 30 seconds.
- Test failover for your DB cluster to understand how long the process takes for your use case.
- We recommend that you try out DB parameter group and DB cluster parameter group changes on a test DB cluster before applying parameter group changes to your production DB cluster.
Reference
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/CHAP_AuroraOverview.html

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









