







Introduction
现代的分布式云服务通过将计算和存储进行解耦来获得更强的可扩展性和弹性。Amazon认为现在的分布式云服务还存在一些问题:
- 计算和存储的解耦使得性能瓶颈从I/O变为了发起请求的数据库和执行请求的底层存储系统之间的网络资源。
- 虽然现在大多数数据库操作可以并发执行,但是在某些情况下仍然需要进行同步,这会导致cpu stall和context switch现象。比如,数据库中的cache buffer miss,就需要进行换页或刷页。
- 事务的提交过程中意外中止会影响其它事务的提交。 传统的2pc等提交方案对故障容忍度较低,但是在大规模分布式系统中,硬件和软件经常出现问题。除此之外,由于大规模的分布式系统经常跨多个数据中心,因此网络的是高延迟也是一个很严重的问题。
Aurora通过将rodo logging和storage从database中分离出来以解决上述问题,其具体架构如下图所示。

相比传统数据库,Aurora具有以下优点:
- 将存储从数据库中分离,保护了数据库不受存储或网络的故障的影响从而导致性能波动。
- 只将redo log写入storage,减少了网络开销。
- 将一些负责和重要的功能(backup,redo recovery)从数据库引擎的一次昂贵操作转移到连续的异步操作。 这些异步操作可以由分布式集群分摊,这产生了无需checkpoint的近乎即时的故障恢复和不会对前台处理造成影响的廉价backup。
Durability at Scale
Replication and Correlated Failures
在分布式数据库服务中,instance lifetime和storage lifetime并不相关联,这种特性是有利于实现存储计算分离。但是,一旦将storage进行分离,disk和storage node就有可能发生故障,因此必须建立容错机制。
一种常见的容错机制是使用quorum-based voting,完成读操作需要 V r V_r Vr的投票数,完成写操作需要 V w V_w Vw的投票数,且其需要满足以下约束:
- V r + V w > V V_r + V_w > V Vr+Vw>V,该约束保证了每次读操作所获取的数据中至少有一个是最新版本(如何判别最新版本可以通过版本号等确定)。
- V w > V / 2 V_w > V/2 Vw>V/2,该约束保证了写一致性
Amazon认为常见的故障有两种:
- Avalibility Zone故障,即某个数据中心因火灾、地震等事件出现整体故障。
- SIngle Node故障,即某个AZ中的一部分disk出现故障。
为了提高Aurora地耐用性,Amazon认为Aurora需要容忍以下集群异常:
- 整个AZ故障外加single node故障不会影响读操作
- 整个AZ故障不会影响写操作
Aurora采用了3个AZ,每个AZ内2个replica nodes总共6个replica servers的方法来进行容错备份。 V = 6 , V w = 4 , V r = 3 V=6,V_w=4,V_r=3 V=6,Vw=4,Vr=3,Aurora可以容忍任何一个AZ出现故障,而不会影响写服务,任何一个AZ出现故障,以及另外一个AZ中的一个节点出现故障,不会影响读服务且不会丢失数据。
Segmented Storage
只要保证AZ故障和single node故障不要短时间内大量同时发生,就可以保证数据库永久可用。衡量数据库耐用性通常用两个指标,平均两次故障间隔时间(MTTF)和平均故障修复时间(MTTR)。 由于MTTF是不可控因素,因此Aurora通过减少MTTR来降低故障同时发生的概率。
Aurora将数据分为固定10GB大小的segments,每个segments有6个备份,每个segments的所有备份共60GB组成一个PG(Protection Group)。6个备份被平均分配在3个AZ中,每个AZ两个。Segments是出现故障和修复的最小单元,在Aurora中每个10GB segment在10Gbps网络下仅需要10s就能完成修复。 根据Amazon的使用情况,目前该方案能够保证数据库系统的长期运行。
The Log is The Database
The Burden of Amplified Writes
Aurora的3个AZ,每个AZ内部两个replica的复制方案带来了极强的容错性和弹性。然而,这种备份方式却不能直接用于MySQL等传统数据库,因为MySQL在一次写操作时实际上会触发大量的I/O操作,并且replication机制会将高I/O操作再次放大。
考虑一个传统的MySQL数据库执行一次写操作的流程,具体如下图所示。

上图展示了primary-standby模式下运行的MySQL数据库执行一次写操作的流程。在第一步和第二步中,primary instance向EBS发出写操作请求,然后EBS将其发送到同AZ中的本地EBS镜像,并等待这两个操作完成。在第三步中,primary instance将数据同步给replica instance。最后,在第四步和第五步中,replica instance将数据写入使用的EBS及同AZ中的EBS镜像。
在上述整个步骤中,存在以下几个问题:
- 仅仅一次写操作实际需要写入的数据有redo log, bin log, data, double write page, metadata files。
- 步骤1,3,5必须是顺序执行,导致延迟大大增加。
- 每个数据有4个备份,每次写操作必须在4个EBS上都写成功才能返回,容错性差。
Offloading Redo Processing to Storage
在Aurora系统中,一次写操作中仅仅需要保留redo log的传输即可,并且redo log的写入可以异步进行。 Aurora摒弃了传统MySQL的复杂写入机制,提升了系统的写吞吐量。
Aurora会直接将redo log发送到storage,data page的更新操作从传统的数据库层下沉到storage层,具体如下图所示:

Aurora数据库实例中的log applicator会直接将redo log record推送给存储层(storage service),而storage service则会在后台或者需要的时候基于redo log生成数据库的data page。 当然,基于redo log每次都从头去应用redo log进而生成data page的代价是非常大的。因此,Aurora的存储服务会不断在后台去应用redo log 从而生成数据库data page,以避免每次都从头开始重新生成它们,这个过程称之为后台物化(background materialization)。 在写入过程中,primary instance仅将redo log record写入存储服务,并将这些redo log record以及元数据更新信息流式地传输到replicate instance。不同与传统的MySQL数据库,数据库引擎在收到4个storage的回复,便认为数据已经写入成功。
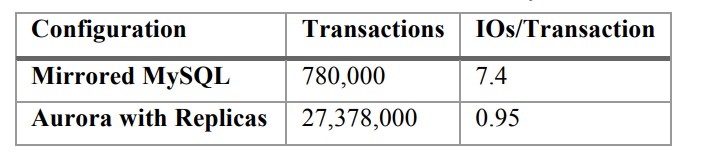
相比传统的MySQL数据库,该措施大大提升了系统吞吐量。
对于crash recovery而言,传统的数据库需要从最近的checkpoint开始重新应用redo log。在Aurora中,data page的更新操作一直由storage service负责进行,如果读取到的data page不是最新的,则需要等待storage进行background materialization。 由此,data page的更新操作被分散在了每次读操作中,数据库启动和故障恢复几乎不需要花费任何时间。
Storage Service Design Points
Aurora设计的核心要点是最小化database处理write request的时延。 传统数据库中,storage processing和compute processing都处在一个节点上,因此storage service的操作会直接影响database的性能。 为了实现这个目标,Aurora将大量的跟存储有关的操作从database转移到storage service。并且,由于batabase和storage service之间的性能解耦,Aurora可以充分利用这个关系来让CPU为disk服务。例如,Aurora不必在storage node繁忙时进行old redo log的垃圾回收,可以等到storage service空闲时在进行垃圾回收,

Aurora完成一次write request的具体I/O流如上图所示:
- 接收redo log recored并将其添加到内存队列中。
- 将redo log record 持久存储到磁盘上并将确认消息发送给数据库实例。
- 将受到的redo log record进行组织并识别出由于某些batch丢失而导致的redo log record空洞。(由于写入操作采用的是多数投票,因此可能会存在某些replica上面日志不一致的情况)
- 通过gossip协议与其他的storage node同步,获得丢失的redo log record。(利用gossip弱一致性协议完成日志同步)
- 将redo log record合并到新的data page中。
- 定期将阶段性的redo log和对应的新的data page暂存到S3。
- 定期对旧版本数据进行GC。
- 定期验证data page上的CRC code。
在上数步骤中,主要影响database性能的是1,2步,其它步骤均可以异步执行。
The Log Marches Forward
Solution Sketch:Asynchronous Processing
Aurora将database建模为redo log stream,并且通过日志来保障Aurora的一致性。Aurora摒弃了性能较差的2PC协议,转而使用了gossip协议来保证replicate log之间的一致性。 由于database中由很多独立执行的隔离事务,因此database需要决定这些事务的执行顺序。当database宕机或故障时,database需要决定哪些事务需要进行roll back,事务的追踪和回滚操作由database engine完成。然而,除了database的事务recovery机制,storage service也有自己的一套基于gossip的recovery机制,如何将两者协调起来,是Aurora要解决的问题。
为了保证一致性和可恢复性,Aurora定义了以下概念:
- LSN:每个log record都有一个由database自动生成的递增的log sequence number。
- VCL:storage service所拥有的能够保证一致性的最大的log record LSN,即任何小于等于VCL的log record都在至少保存在4个replicate server上。
- CPL:由database标记的consistency point,每个mini-transcation的最后一条日志被标记为CPL。
- VDL:满足小于等于VCL的最大CPL。
Aurora在进行crash recovery时,会截断所有大于VDL的日志。 例如:VCL=1007,database记录的CPL为900,1000,1100,Aurora则会将1000后面的日志全部截断。database和storage server的交互过程如下:
- 每个数据库级别的事务被分解为多个有序的mini-transactions(MTR),所有MTR必须按序原子执行。
- 每个mini-transaction都由多个连续的log record组成。
- mini-transaction中的最终log record被标记为CPL。
基于此过程我们可以发现,Aurora阶段截断VDL而不是截断VCL的原因是为了保证mini-transaction的有序原子性。 因为只有CPL标记才能唯一标识mini-transcation的执行结束。
Normal Operation
Writes
在Aurora中,database向storage service传递redo log,达成多数派后将事务标记为提交状态,然后推进VDL,使数据库进入一个新的一致状态。为了避免database处理事务的速度过快,导致LSN大幅度领先VDL,使得storage service称为性能瓶颈,Aurora规定了LSN和VDL的差距阈值LAL。
由于底层数据被划分为segments,当一个事务涉及到修改多个不同的segments时,事务对应的日志会被打散到多个segment上,每个segment只能看到这个事务的部分日志。 为了确保各个分片日志的完整性,每条日志中都包含一个前向链接,前向链接指向了前一条log record。 通过前向链接就可以遍历分布在PG中各个segment上的所有redo log,进而构建一份完整的SCL(Segment Complete LSN)链表。SCL主要用于各个storage node通过gossip协议查找和交换各自缺失的redo log record。

Commits
在Aurora中,事务提交是异步完成的。 每个事务由若干个日志组成,并包含有一个唯一的“commit LSN”,当VDL大于事务的commit LSN时,表示这个事务redo-log都已经持久化,可以向客户端回包,通知事务已经成功执行。在Aurora中,有一个独立的线程处理事务成功执行的回包工作,而工作线程不会等待事务提交完成,它们会继续处理其它的事务。

Reads
在Aurora中,数据页的请求从buffer cache中获取,只有当buffer cache中不存在时,才会用disk上获取。当buffer cache满时,需要进行置换算法将某些页换出,传统的数据库还需要将dirty page进行刷回,而Aurora不会将需要被置换出去的数据页刷写到磁盘,而是直接丢弃。
Aurora在进行page置换时,只会将page LSN小于等于VDL的页进行淘汰。 这一条件保证了:
- 这个数据页所有的修改都已经在日志中持久化。
- 当缓存不命中时,通过VDL总能得到最新的数据页。
Aurora在进行读操作时,正常情况下,不需要quorum read。 每当database处理读请求时,会将该读请求发生时的VDL值标记为read-point。database只需要访问VCL大于等于read-point的segment就可以得到最新的数据。 由于database存储了SCL和metadata等信息,因此其知道每个segment处理过的读请求中的minimum read-point,database通过统计所有的segments就可以得到全局的minimum read-point。所有LSN低于minimum read-point的redo log都可以被垃圾回收, 因为后续所有读操作的read-point一定大于等于minimum read-point。
Replicas
在Aurora中,一个writer可以和最多15个read replicas共享一套storage volume。因此增加read replicas并不会造成写放大,也不会增加磁盘存储资源。这也是共享存储的优势,在不增加存储成本的前提下增加新的read replicas,从而提升读能力。 为了减小writer和read replicas之间的log lag,wrtier往storage node发送日志的同时也会向read replicas发送日志。read replicas在进行日志回放时,如果所需要的page在reader buffer中,则直接将log应用到page上,如果不在则直接丢弃该条log。 可以丢弃的原因在于,storage node拥有所有日志,storage node根据read-point,可以构造出特定版本的数据页。wrtier向read replica发送日志是异步的,writer执行提交操作并不受read replicas的影响。
read replcias回放日志时需要遵守两个基本原则:
- 回放日志的LSN需要小于或等于VDL。
- 回放日志时需要以MTR为单位,确保副本能看到一致性视图。
















 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









