




 本文介绍了如何使用Python爬取孔夫子旧书网的店铺评论,重点在于寻找动态加载评论的js文件,解析URL规律,并通过json模块处理数据。通过分析网页源码和网络请求,获取评论数据并存储。
本文介绍了如何使用Python爬取孔夫子旧书网的店铺评论,重点在于寻找动态加载评论的js文件,解析URL规律,并通过json模块处理数据。通过分析网页源码和网络请求,获取评论数据并存储。
python爬取孔夫子旧书网的店铺评论
python2.7.15
这次爬取的是动态网页,所谓动态网页就是动态网页是指网页文件里包含了程序代码,通过后台数据库与Web服务器的信息交互,由后台数据库提供实时数据更新和数据查询服务。它的数据不会直接出现在网页的源码里,它是通过js、xhr等文件动态加载的,比如一些网页里的商品信息,用户评论。
这次爬取的孔夫子旧书网的店铺评论就是存放在js文件里的,想要爬取它首先要找到网页对这个文件的请求,这个可以在浏览器里右键审查元素来找
一、查找对应文件
首先打开浏览器,孔夫子旧书网,书店区。右侧有很多排行榜,也就是书店列表,我们可以挑一个进行操作比如这个销量排行榜,点进去我们可以看到2000条书店信息。随便点一个书店进去,右侧书店信息里有书店的好评率等评价信息,点进去,就找到我们想要的评论列表啦。
评论对应的js文件怎么找呢?右键审查元素,Network,刷新,这些文件就出来了。
现在需要筛选出评论对应的那个文件,这些文件一班为js或xhr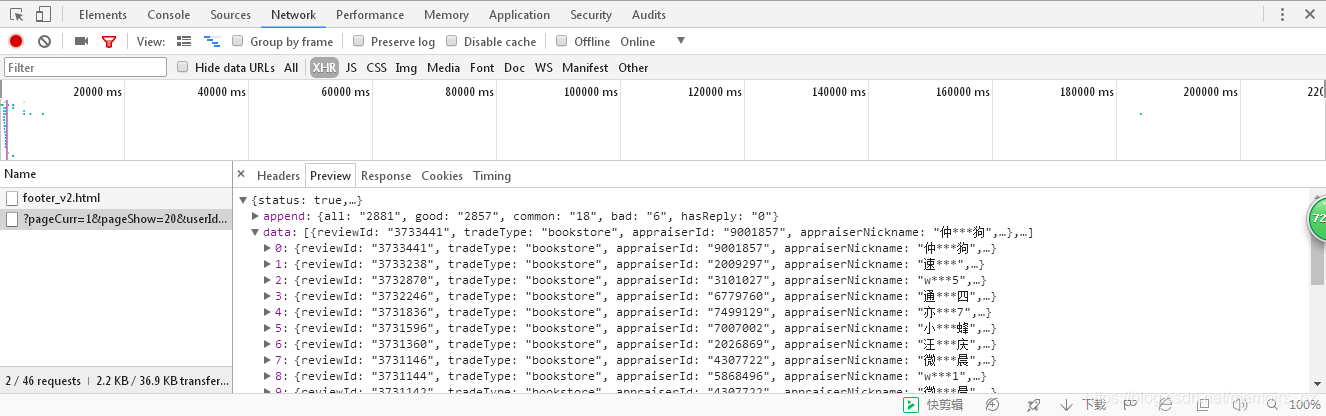
这个就是了,格式类似于python的字典,每一条对应一条评论,包括评论者,商品信息,评论,评论日期等。
在它的headers里我们可以看到它的URL和请求方式等信息,稍后我们会用到。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









