






scrapy结合xpath爬取爱问知识人
python2.7.15
xpath是个很简洁方便的东西,很清晰,熟练运用xpath可以让你更快的找到想要爬取的东西。
xpath教程请移步X Path语法
先来写spider
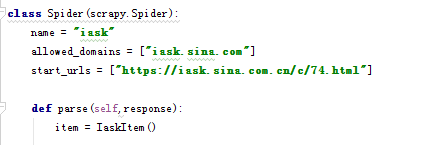
star_url里是爱问知识人的网站的一个问题分类,爬取它的问题和答案。
下面是进入这个页面
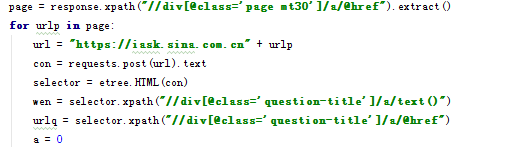
response是star_url传给parse函数的网页信息,对它使用xpath方法,获取我们想要的元素的。
这里是这个问题分类的每一页的网址,这里注意要使用extract方法,获取它的值,如果不使用的话传回的是xpath选择器,是[<Selector xpath=。。。这样的,不是我们想要的文本。
接下来request我们获取的网址,这里如果你直接对request传回的值使用xpath方法的话是用不了的。它和刚才的response不是一个类型,这里我们就要引入一个模块把它编码成网页类型
from lxml import etree
编码之后虽然和response不一样但可以使用xpath方法了。这个xpath选出来的就不是xpath选择器类型了,直接就是文本,比如字符串或列表,所以就没有extract方法了。
剩下的问题和回答的爬取就简单了,最下面源码见。
其他的scrapy相关设置跟上一篇酒店的差不多,不了解的移步上一篇或百度
spider源码
# coding=utf-8
import requests
import scrapy
from lxml import etree
from ..items import IaskItem
class Spider(scrapy.Spider):
name = "iask"
allowed_domains = ["iask.sina.com"]
start_urls = ["https://iask.sina.com.cn/c/74.html"]
def parse(self,response):
item = IaskItem()
def daan(self, urlq, a):
b = urlq[a]
answerurl = "https://iask.sina.com.cn" + b
requ = requests.get(answerurl).text
selector = etree.HTML(requ)
answers = selector.xpath("//pre/text()")
answer = ''.join(answers)
return answer
page = response.xpath("//div[@class='page mt30']/a/@href").extract()
for urlp in page:
url = "https://iask.sina.com.cn" + urlp
con = requests.post(url).text
selector = etree.HTML(con)
wen = selector.xpath("//div[@class='question-title']/a/text()")
urlq = selector.xpath("//div[@class='question-title']/a/@href")
a = 0
for question in wen:
item['question'] = question.encode('utf-8')
print question + '\n'
answer = daan(self,urlq,a)
a+=1
item['answer'] = answer.encode('utf-8')
print answer
yield item















 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









