







文章目录
声明
文章所涉及的内容仅为学习交流所用。
scrapy 基础
- scrapy 是框架 类似于一个工具
- 采用异步框架 实现高效率的网络采集
- 最强大的数据采集框架
安装 scrapy
pip install scrapy
注:
1 如果遇到 vc++14.0 twisted 错误,则应离线安装。
百度:python whl
下载好后:pip install xxx.whl
2 如果运行 scrapy bench 遇到 win32 错误,安装:pip install pywin32
scrapy 原理
1.引擎(Engine)
– 引擎负责控制数据流在系统所有组件中的流向,并在不同的条件时触发相对应的事件。这个组件相当于爬虫的“大脑”,是整个爬虫的调度中心。
2.调度器(Scheduler)
– 调度器从引擎接受请求并将它们加入队列,以便之后引擎需要它们时提供给引擎。初始爬取的URL和后续在网页中获取的待爬取的URL都将放入调度器中,等待爬取,同时调度器会自动去除重复的URL。如果特定的URL不需要去重也可以通过设置实现,如post请求的URL。
3.下载器(Downloader)
– 下载器的主要功能是获取网页内容,提供给引擎和Spiders。
4.Spiders
– Spiders是Scrapy用户编写用于分析响应,并提取Items或额外跟进的URL的一个类。每个Spider负责处理一个(一些)特定网站。
5.Item Pipelines
– Item Pipelines主要功能是处理被Spiders提取出来的Items。典型的处理有清理、验证及持久化(例如存取到数据库中)。当网页被爬虫解析所需的数据存入Items后,将被发送到
项目管道(Pipelines),并经过几个特定的次序处理数据,最后存入本地文件或数据库
6.下载器中间件(Downloader Middlewares)
– 下载器中间件是一组在引擎及下载器之间的特定钩子(specific hook),主要功能是处理下载器传递给引擎的响应(response)。下载器中间件提供了一个简便的机制,通过插
入自定义代码来扩展Scrapy功能。通过设置下载器中间件可以实现爬虫自动更换useragent、IP等功能
7.Spider中间件(Spider Middlewares)
– Spider中间件是一组在引擎及Spiders之间的特定钩子(specific hook),主要功能是处理Spiders的输入(响应)和输出(Items及请求)。Spider中间件提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。各组件之间的数据流向如图所示。
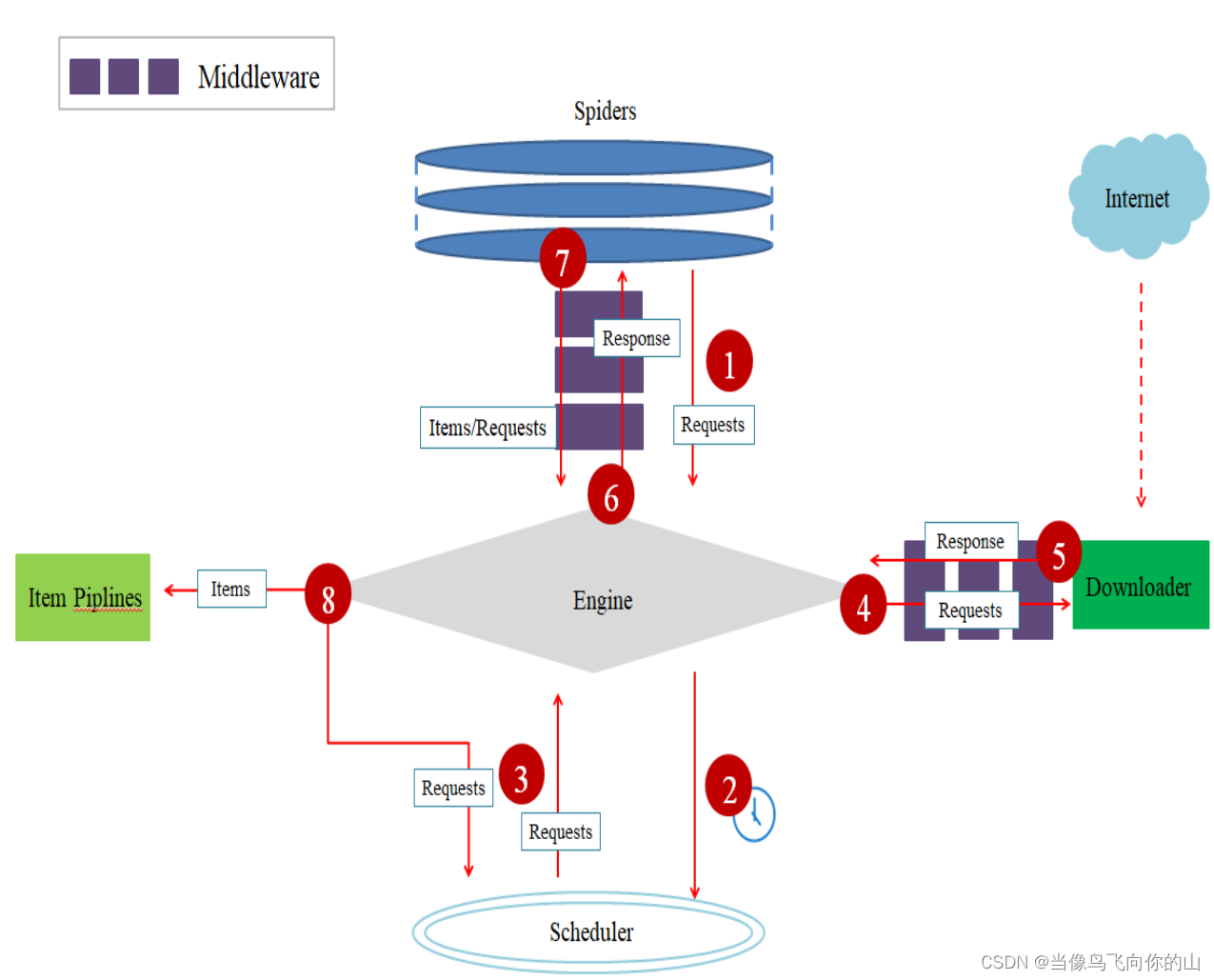
从初始URL开始,Scheduler会将其交
给Downloader进行下载
• 下载之后会交给Spider进行分析
• Spider分析出来的结果有两种
– 一种是需要进一步抓取的链接,如 “下一
页”的链接,它们会被传回Scheduler;
– 另一种是需要保存的数据,它们被送到
Item Pipeline里,进行后期处理(详细分
析、过滤、存储等)。
scrapy 应用示例
一 爬取新闻
基础信息
采集目标:标题 链接 日期
url
https://www.ucas.ac.cn/site/26
1 新建项目
良好习惯:根据 域名 + Spider 命名项目(爬虫)名称。
在项目文件夹cmd下执行如下代码,我是用的pycharm下面的terminal,感觉很好用()
scrapy startproject ucasSpider
(一个文件夹中包含__init__.py表示这是一个模块)
2 创建爬虫
根据基础模板创建爬虫文件:
进入项目,项目内有两个文件 文件夹 和 cfg
cd ucasSpider
ls
genspider 爬虫名 域名
scrapy genspider ucas ucas.ac.cn
注意:
第一个参数是爬虫名字不是项目名字;
第二个参数是网站域名,是允许爬虫采集的域名。比如:baidu.com 不限制域名 可能爬到 zhihu.com 。后期可以更改,但要先有。
生成了ucas爬虫文件:
很多教程都是自己写这个文件 QAQ
3 君子协议
setting.py 中君子协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
一般设置为false,不然爬虫没得干。
比如:https://www.nike.com.cn/
浏览:https://www.nike.com/robots.txt
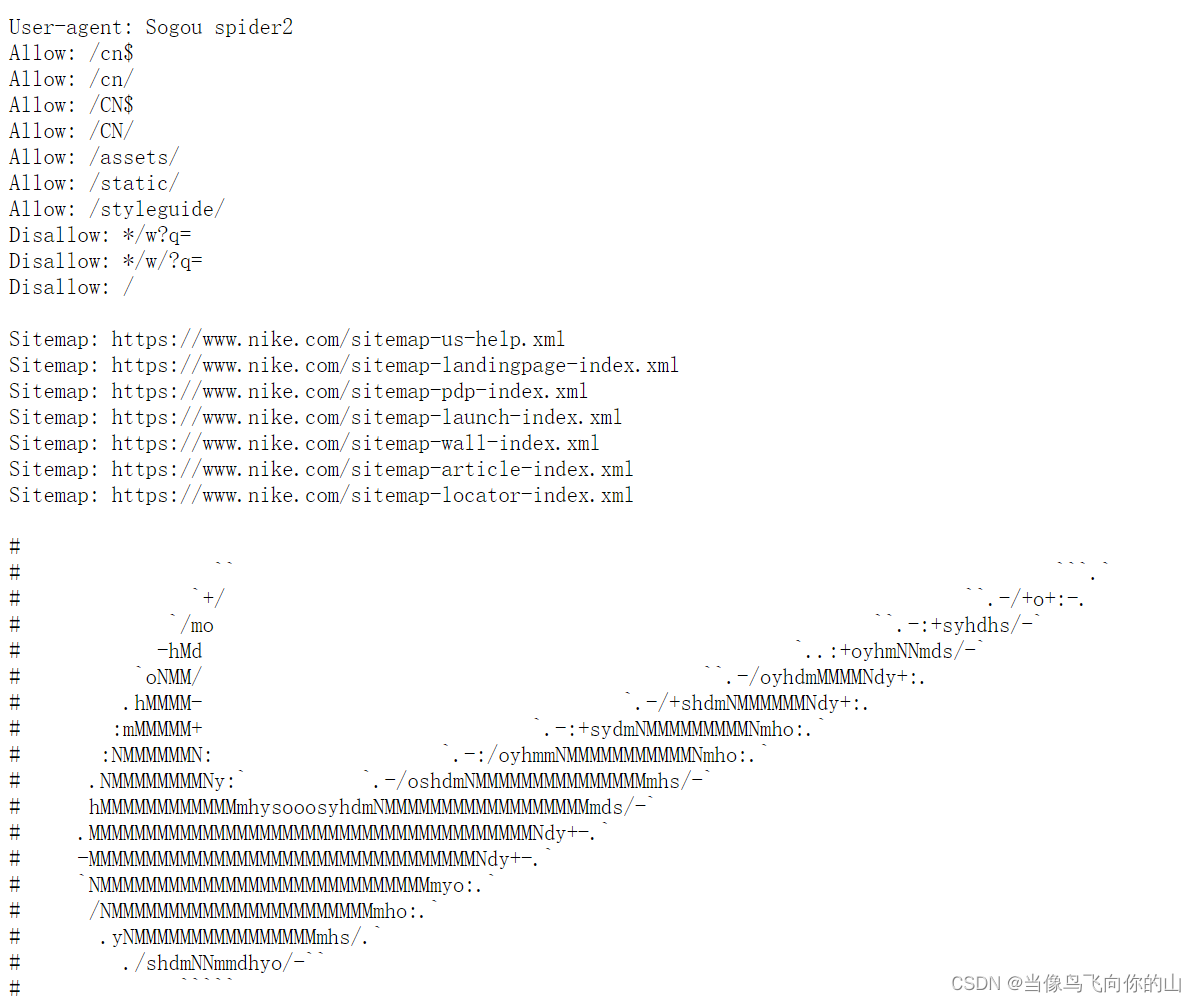
4 爬虫文件解释
import scrapy
# 创建爬虫类 继承自scrapy.Spider --> 最基础的类
# 另外几个类都是继承自这个
# 查看一共几个基础类:scrapy genspider -l
# 4个 basic crawl csvfeed xmlfeed 但源码中有5个
class UcasSpider(scrapy.Spider):
name = 'ucas' # 爬虫名字 必须唯一
allowed_domains = ['ucas.ac.cn'] # 允许采集的域名
start_urls = ['https://www.ucas.ac.cn/'] # 开始采集的网址
# 解析响应数据 提取数据或者网址等
# response 响应 网页源码
def parse(self, response):
pass
5 分析网站
把要采集的网址:https://www.ucas.ac.cn/site/26
放入上面spider/ucas.py中。
start_urls = ['https://www.ucas.ac.cn/site/26'] # 开始采集的网址
5.1 提取数据
方法1 正则表达式
方法2 XPath --> 从HTML中提取数据语法
方法3 CSS --> 从HTML中提取数据语法
函数:
response.xpath('xpath').get()
# get得到一个元素
# getall得到多个元素
下面使用方法2:
教程:百度 w3 xpath
首先打开网址。
右键页面检查;找到关注的元素的源代码。
使用谷歌浏览器插件:xpath helper

然后,根据html代码查找目标内容的位置,得到xpath:
# 文章标题
//body//div[4]//div[3]/p[img]/a/text()
# 文章链接
//body//div[4]//div[3]/p[img]/a/@href
# 文章日期
//body//div[4]//div[3]/p/span/text()
p [img] 选取所有拥有名为 img 的属性的 p 元素,因为 “通知公告” 没有 img。
参考:https://www.w3school.com.cn/xpath/xpath_syntax.asp
(一开始span忘写text了虽然可以提取数据,但是一加get就找不到了,debug一会才发现这个问题,基础不牢地动山摇啊啊啊……)
5.2 spider/ucas.py
import scrapy
# 创建爬虫类 继承自scrapy.Spider --> 最基础的类
# 另外几个类都是继承自这个
# 查看一共几个基础类:scrapy genspider -l
# 4个 basic crawl csvfeed xmlfeed 但源码中有5个
class UcasSpider(scrapy.Spider):
name = 'ucas' # 爬虫名字 必须唯一
allowed_domains = ['ucas.ac.cn'] # 允许采集的域名
start_urls = ['https://www.ucas.ac.cn/site/26'] # 开始采集的网址
# 解析响应数据 提取数据或者网址等
# response 响应 网页源码
def parse(self, response):
# 提取数据 selectors选择器
# 标题 //body//div[4]//div[3]/p/a/text()
# 链接 //body//div[4]//div[3]/p/a/@href
# 日期 //body//div[4]//div[3]/p/span
# 因为新闻标题 链接 日期是一一对应的 所以要先定位到大的 再遍历里面的内容
selectors = response.xpath('//body//div[4]//div[3]/p[img]')
# 遍历上面标签的内部标签 --> 3个
for selector in selectors:
title = selector.xpath('./a/text()').get() # .在当前目录下继续选择
link = selector.xpath('./a/@href').get()
date = selector.xpath('./span/text()').get()
print(title, link, date)
执行爬虫,可以看到数据:
scrapy crawl ucas
5.3 如果遇到反爬
ucas网站没有反爬,如果你的网站遇到了反爬,则需要添加headers。
在setting.py文件中,修改默认请求头。
原始:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
添加请求头,user-agent:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
5.5 运行爬虫
scrapy crawl ucas
6 爬取多页
方法一:观察网址变化 start_url 中引入 for 循环
start_urls = [f'https://www.ucas.ac.cn/site/26?pn={page}' for page in range(1, 12)] # 开始采集的网址
缺点:写死了 必须先知道有多少页
方法二:翻页操作
先找到下一页按钮的源代码根据 [@class=“next_page”] 等方法筛选,锁定到需要更改的链接后缀。ucas网址不适用,因为ucas是text下一页。
<a href="/site/26?pn=4">下一页</a>
ucas的下一页和上一页没有什么特殊的分别,所以会锁定包括上一页和下一页的四个内容。(或许是我能力问题……)
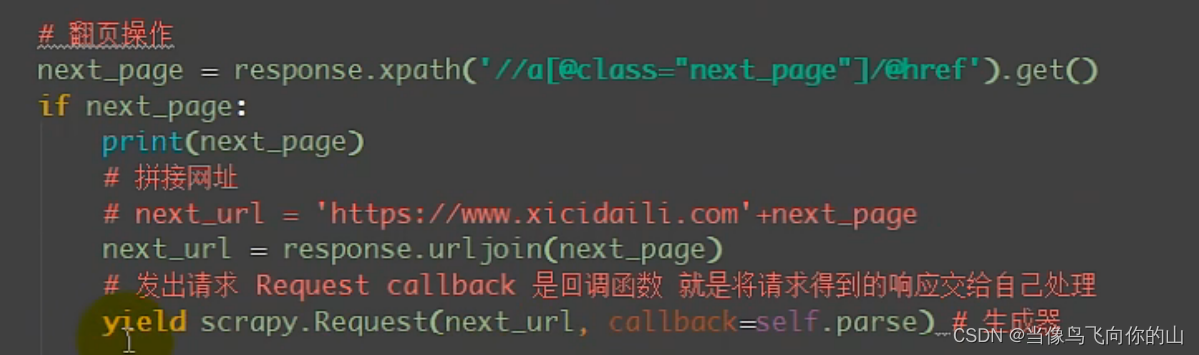
scrapy.Request(next_ url, callback= self.parse) # 生成器:
Request() 发出请求类似 requests . get()
callback 是将发出去的请求得到的响应还交给自己处理
注意:回调函数不要写()只写函数名
7 保存数据
上面ucas的spider文件中的print改为抛出数据:
items = {
'title': title,
'link': link,
'date': date
}
yield items # 抛出数据
运行改为:
scrapy crawl ucas -o ucas_news.json
附录
- 网址构成
http://:代表超文本传输协议,通知服务器显示Web页,通常不用输入
www:代表一个Web(万维网)服务器
yahoo是域名主体
/.cn/.是属于中国国内域名
.com/.***.org是属于国际域名
参考
[1] https://www.bilibili.com/video/BV1m441157FY/?spm_id_from=333.880.my_history.page.click&vd_source=db82cedead5da076759f8f459895dbd4
[2] https://www.w3school.com.cn/xpath/xpath_nodes.asp
[3] 我们老师的课件














 3241
3241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









