







背景
随着互联网的快速发展和互联网+物联网的场景不断增加,信息数据量正在呈几何式的爆发。这些海量数据决定着企业的未来发展。这些数据中,有用的价值数据就需要数据分析师或分析系统去分析。
但是使用一般的工具己满足不了和承受不住庞大的数据带来的压力。近两年针对大数据的开发工具开启了开源大潮,为大数据开发者提供了多个选择,但是也增加了开发者选择合适的工具的难度。
尤其是新入行的开发者,会增加很大的学习成本,框架的多样化和复杂度成了很大的难题。有时候会需要各种框架、工具、中间件、平台等整合到一起才能完成数据分析。
因此,大数据分析平台简单化和统一化成了开发者刚需。
什么是ClickHouse?
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
我们可能都听过clickhouse速度很快,也听说过它不能处理高并发等各种特性,下面我们就从它的工作原理来分析下这些结论到底对不对,以及为什么会是这样。
要想弄清楚ClickHouse做查询分析那么快的原因,咱们可以反客为主,先想想自己设计一款OLAP数据库的核心技术应该有哪些?然后我们再来看看ClickHouse是如何实现如何工作的。
我们先看两条查询语句
场景一:
select username, number from user where id = 1;
场景二:
select department, avg(age) from student group by department;
第一种场景:
如果数据量小,并且数据是结构化的,使用MySQL去存储即可;
如果数据量大,不管是不是结构化的,可以转成key-value的存储,使用 HBase,Cassandra等来解决。
第二种场景:
如果数据量小,并且数据是结构化的,使用MySQL去存储即可;
如果数据量大,不管是不是结构化的,设计一个专门用来做分析的存储计算引擎解决分析的低效率问题。
一、如何设计一个oltp数据库?
-
内存 + 磁盘:
保证处理效率,也保证数据安全
-
内存:必须经过设计,内存具备优秀的数据结构,保证基本的读写高效,甚至为了不同的需求,可以让读写效率倾斜。
-
磁盘:数据必须存放在磁盘,保证数据安全。磁盘数据文件必须经过精心设计,保证扫描磁盘数据文件的高效率
-
数据排序:在海量数据中要想保证低延时的随机读写操作,数据最好是排序的
-
范围分区:当数据排序之后,可以进行范围分区,来平摊负载,让多台服务器联合起来对外提供服务
-
跳表:基于数据排序+范围分区构建索引表,形成跳表的拓扑结构,方便用户操作时快速定位数据分区的位置
-
LSM-Tree存储引擎:把随机写变成顺序追加,在通过定期合并的方式来合并数据,去除无效数据,从而实现数据的删除和修改。
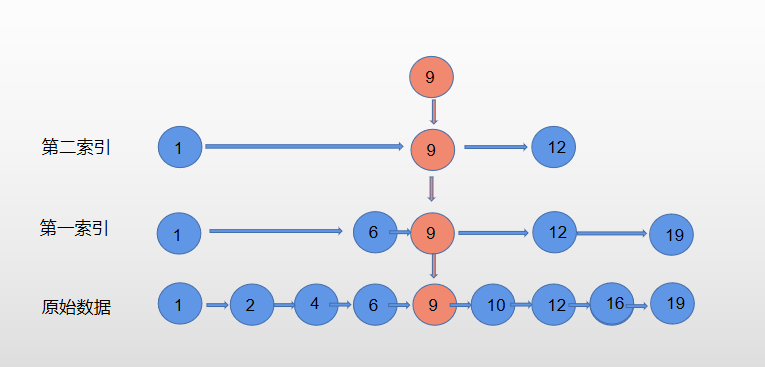
海量数据中,如果进行高效率的查询的核心思想:设计一种架构,能够快速把待搜寻的数据范围降低到原来的1/n,然后再结合索引或者热点数据放在内存等思路,就能实现高效率的查询了。
那么一个专门用来做OLAP分析的存储引擎该如何设计呢?如何在海量数据中,针对大量数据进行查询分析呢?一些常见的方案和手段如下:
-
列式存储 + 字段类型统一
-
列裁剪
-
数据排序
-
数据分区分片 + 分布式查询
-
预聚合
-
利用CPU特性:向量化引擎,操作系统必须支持
-
主键索引+二级索引+位图索引+布隆索等
-
支持近似计算pv
-
定制引擎:多样化的存储引擎满足不同场景的特定需要
-
多样化算法选择:Volnitsky高效字符串搜索算法和HyperLogLog基于概率高效去重算法
总结一下:单条记录的增删改等操作,通过数据的横向划分,做到数据操作的快速定位,在海量数据查询分析中,一般就是针对某些列做分析,既然并不是全部列,那么把数据做纵向切分把表中的数据按照列来单独存储,那么在做分析的时候,同样可以快速把待查询分析的数据总量降低到原来表的1/n,同样提高效率。
二、总体介绍:
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。来自于2011 年在纳斯达克上市的俄罗斯本土搜索引擎企业Yandex公司,诞生之初就是为了服务Yandex公司自家的Web流量分析产品Yandex.Metrica,后来经过演变,逐渐形成为现在的 ClickHouse,全称是:Click Stream,Data WareHouse ClickHouse.
官网:https://clickhouse.tech/
ClickHouse具有ROLAP、在线实时查询、完整的DBMS功能支持、列式存储、不需要任何数据预处理、支持批量更新、拥有非常完善的SQL支持和函数、支持高可用、不依赖 Hadoop复杂生态、开箱即用等许多特点。
在1亿数据集体量的情况下,ClickHouse的平均响应速度是Vertica的2.63倍、InfiniDB的17倍、MonetDB的27倍、Hive的126倍、MySQL的429倍以及Greenplum的10倍。
详细的测试结果可以查阅:
https://clickhouse.tech/benchmark/dbms/。
ClickHouse非常适用于商业智能领域(也就是我们所说的BI领域),除此之外,它也能够被广泛应用于广告流量、Web、App流量、电信、金融、电子商务、信息安全、网络游戏、物联网等众多其他领域。ClickHouse是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域。
目前国内社区火热,各个大厂纷纷跟进大规模使用:
-
今日头条内部用ClickHouse来做用户行为分析,内部一共几千个ClickHouse节点,单集群最大1200节点,总数据量几十PB,日增原始数据300TB左右。
-
腾讯内部用ClickHouse做游戏数据分析,并且为之建立了一整套监控运维体系。
-
携程内部从18年7月份开始接入试用,目前80%的业务都跑在ClickHouse上。每天数据增量十多亿,近百万次查询请求。
-
快手内部也在使用ClickHouse,存储总量大约10PB,每天新增200TB,90%查询小于3S。
三:ClickHouse表引擎介绍
表引擎在ClickHouse中的作用十分关键,直接决定了数据如何存储和读取、是否支持并发读写、是否支持index、支持的query种类、是否支持主备复制等。
-
数据的存储方式和位置,写到哪里以及从哪里读取数据
-
支持哪些查询以及如何支持。
-
并发数据访问。
-
索引的使用(如果存在)。
-
是否可以执行多线程请求。
-
数据复制参数
具体可看官网:https://clickhouse.tech/docs/zh/engines/table-engines/
关于ClickHouse的底层引擎,其实可以分为数据库引擎和表引擎两种。在此,我们重点关注表引擎。
关于库引擎,简单总结一下:ClickHouse也支持在创建库的时候,指定库引擎,目前支持5种,分别是:Ordinary,Dictionar
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1823
1823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









