







本人第一次写blog,如有错误欢迎批评指正。
昨天刚学了一下bs4库的爬虫,今天实践了一下,感觉很好玩
安装所需库
我们所用到的库主要是bs4和requests
requests库的作用是向服务器请求所需信息,一般用get()函数获取网页信息,网址字符串作为参数传入。
bs4在此的作用主要是解析发送给服务器请求后get()的text内容,同时快速根据爬取内容筛选所需属性的html标签。
关于这两个库的安装可以通过如下命令:
pip install requests
pip install bs如果是conda python3.8以上的base环境可以用conda替代pip:
conda install requests
conda install bs安装好这两个库之后就可以开始具体的爬虫流程了!
获取html响应
通过requests.get()函数可以获取网页响应,用print查看响应结果
import bs4 as B
import requests
content=requests.get("https://movie.douban.com/top250")
print(content)结果如下:
 很显然,4开头的网页响应状态码表示客户端的问题
很显然,4开头的网页响应状态码表示客户端的问题
而<Response [418]>状态码是指访问的网站在请求头中,没有找到"User-Agent"信息,也就是没有浏览器版本,系统型号等等的信息。从而认为是非浏览器访问,即非真用户访问网址。可以理解为具有反爬虫机制,而解决方法就是传入请求头参数自定义的伪"User-Agent"来访问。
我们可以先用浏览器打开该网页,按F12或鼠标右键”检查“可以查看到网页源码,找到”网络“,随机查看一个请求头:

找到里面的"User-Agent"信息,直接复制粘贴到代码中:

在代码中,我们用一个字典header存储"User-Agent"信息,然后再requests.get()中将header传入headers参数中:("User-Agent"信息请根据自己浏览器用户信息填写)
import bs4 as B
import requests
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.42"
}
content=requests.get("https://movie.douban.com/top250",headers=header)
print(content)此时服务器响应就处理了该请求,变成200了:
 芜湖!向成功又迈进了一大步
芜湖!向成功又迈进了一大步
信息获取与解析
如果需要返回网页源码内容,可以获取content对象的.text属性,即:
print(content.text)此时会返回一系列反人类阅读的html元素:

这个时候bs4就该登场了!
我们把获取的content.text传入bs4的BeautifulSoup(漂亮的汤)函数中搅合一下
all_html=B.BeautifulSoup(content.text)
print(all_html) 注意BeautifulSoup的大小写
虽然输出还是这样依托东西,但是我们可以用bs4的findAll()函数来筛选我们需要的标签了
此代码中实际上是创建一个名为all_html的BeautifulSoup对象,content.text作为构造函数的属性传入,而findAll()是all_html类中的对content.text查找标签的方法
爬虫信息的筛选
我们去到浏览器,查看网页源码,如果需要片名,很显然它们都被放在<span>标签元素中,且属性"class"都为"title",我们可以根据这一筛选条件,在代码中筛选我们所需要的信息

我们可以用以下代码实现:
all_html=B.BeautifulSoup(content.text)
all_titles=all_html.findAll("span",attrs={"class":"title"})
for title in all_titles:
print(title)其中findAll()的第一个参数是查找的标签名,这里我们查找<span>标签,attrs参数表示查找的标签的属性,这里的属性可以是多个值,比如attrs={"class":"title","name":"title"}等等,此时的返回值是带标签的查找到的内容:

可以将输出改为
for title in all_titles:
print(title.string)就可以只输出标签里的字符串内容:

但是我们发现有的影片名有两个名字(标准中文名和其他名称),这是因为在筛选的过程中相同的不需要的标签也一起筛进来了:

其实这种的解决办法也很简单,有很多方法,只要找内容的不同就行了。
我们可以检测内容中是否含有 占位符,或者检测内容中是否有"/"字符就能轻松区分这两个内容,下面是以检测"/"为例子:
for title in all_titles:
cont=title.string
if "/" not in cont:
print(title.string)
内容问题解决后,我们又会发现另一个问题,那就是电影根本没有250个!只有25个鸭!
因为页面中一页只显示了25个电影,这时怎么办呢?
我们翻页后发现在网址域名/top250后面,每页都有新的start=的一个值,而这个值刚好是当前页面第一个电影的索引值,从0开始,每翻一页+25


所以可以写这样一个循环:(从0到250,步长为25)
for num in range(0,250,25):
content=requests.get(f"https://movie.douban.com/top250?start={num}&filter=",headers=header)
all_html=B.BeautifulSoup(content.text)
all_titles=all_html.findAll("span",attrs={"class":"title"})
for title in all_titles:
cont=title.string
if "/" not in cont:
print(title.string)并且用格式化的方式在网址前面+f,然后在网址中用{num}表示每次循环的num值,这样就能获取豆瓣前250的所有电影了

我们还可以通过一些个性化手段丰富输出的细节:
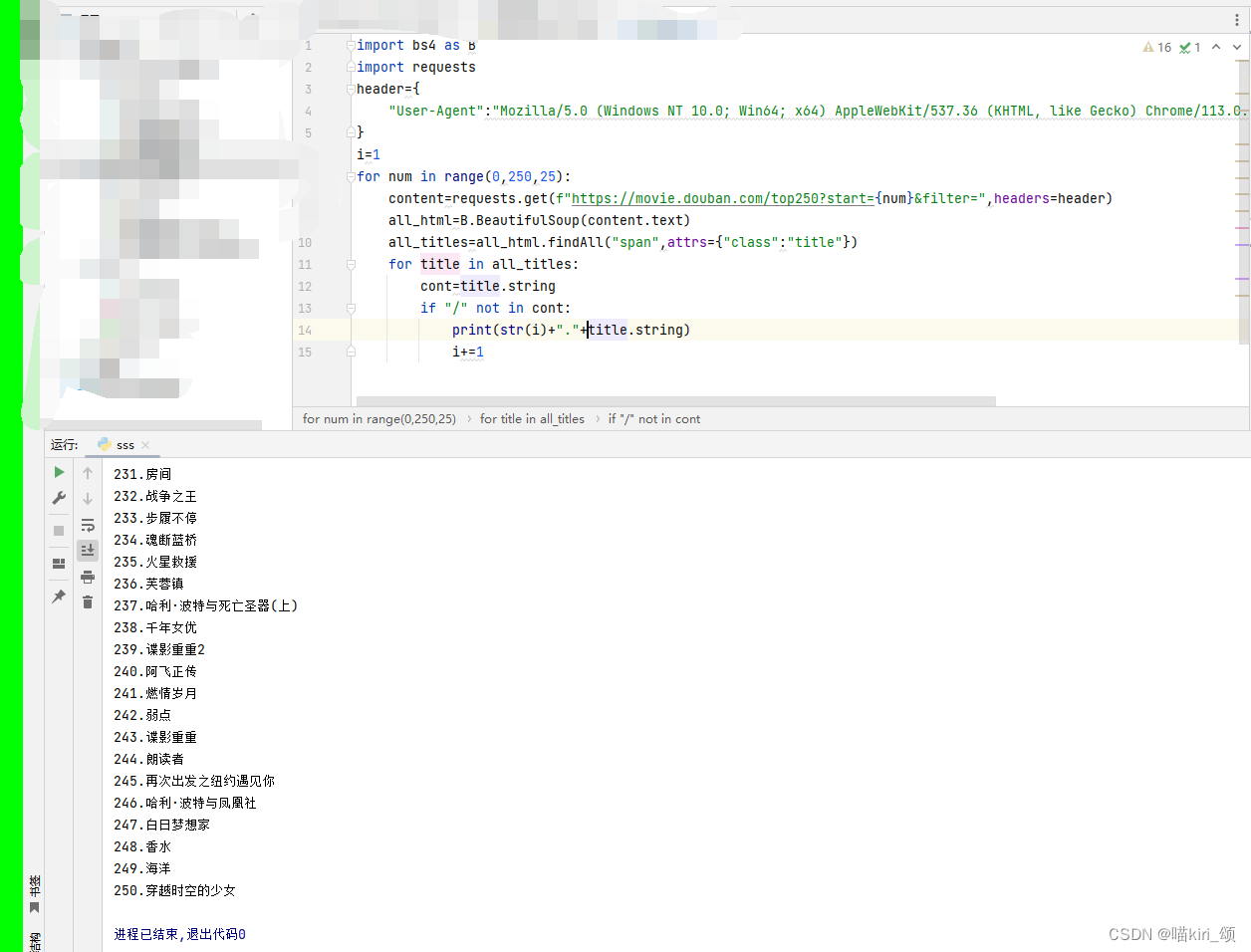
在此,一个基本的爬虫就已经写好啦:("User-Agent"信息请根据自己浏览器用户信息填写)
import bs4 as B
import requests
header={
"User-Agent":""
}
i=1
for num in range(0,250,25):
content=requests.get(f"https://movie.douban.com/top250?start={num}&filter=",headers=header)
all_html=B.BeautifulSoup(content.text)
all_titles=all_html.findAll("span",attrs={"class":"title"})
for title in all_titles:
cont=title.string
if "/" not in cont:
print(str(i)+"."+title.string)
i+=1思路就是这样,如果需要实时间隔时间爬取其他网站的信息可以添加一个time()库使用time.sleep()间隔一定时间爬取一次,并且在写文件时用”a“模式写入何时爬取的什么什么信息。总之爬虫还是很多样性的,更进阶一点的爬虫还有正则表达式等等用于自定义匹配字符的操作
爬虫获取信息写入文件
文件的写入和读取有两种写法,一个是直接将open()的文件对象赋给一个变量,另一种是将open()的文件打开with一个变量。区别是结束文件open时是否需要另外close()
f=open("data.txt","r")
f.read()
f.close()#需要close()
with open("data.txt","r") as f:
f.read()
#不需要close(),解除缩进即退出文件操作open()的参数中:
第一个是默认的文件路径path,字符串格式
第二个是打开方式,"w"是覆盖原文件写入,不可读;"r"是读取,不可写入;"a"是追加在末尾写入,不可读。并且如果本来没有这个文件,则会新建一个
若在w,r,a后加上“+”,则在原功能上即可写也可读,但是就不能自己新建原本没有的该文件了
(以上文件操作都是字符类型,如是字节类型则改为"wb","rb","ab",b表示byte)
处理前两个默认参数也可以添加其他参数如encoding(编码格式),一般默认encoding="utf-8"。
文件读取有以下常用方法:
with open("data.txt","r") as f:
f.read()#读取全部的文件,返回文本字符串
f.read(num)#读取num个字符,返回文本字符串
f.readline()#读取一行,返回改行的文本字符串
f.readlines()#读取全部行,返回由每行组成的字符串列表需要注意的是,文件读取会自己记录当前读到哪个位置,如果f.read()后,因为此时已经记录读到末尾了,再怎么读返回的都是空值
如果我们要写入刚刚爬取的内容我们可以用以下代码:
import bs4 as B
import requests
header={
"User-Agent":""
}
i=1
f=open("豆瓣电影top250.txt","w")
for num in range(0,250,25):
content=requests.get(f"https://movie.douban.com/top250?start={num}&filter=",headers=header)
all_html=B.BeautifulSoup(content.text)
all_titles=all_html.findAll("span",attrs={"class":"title"})
for title in all_titles:
cont=title.string
if "/" not in cont:
f.write(str(i)+"."+title.string+"\n")
i+=1
f.close()把之前的输出改为写入,别忘记f.close()释放内存资源
这里要注意的是,写入一行内容并不像print()能自动换行,所以要手动添加“\n”
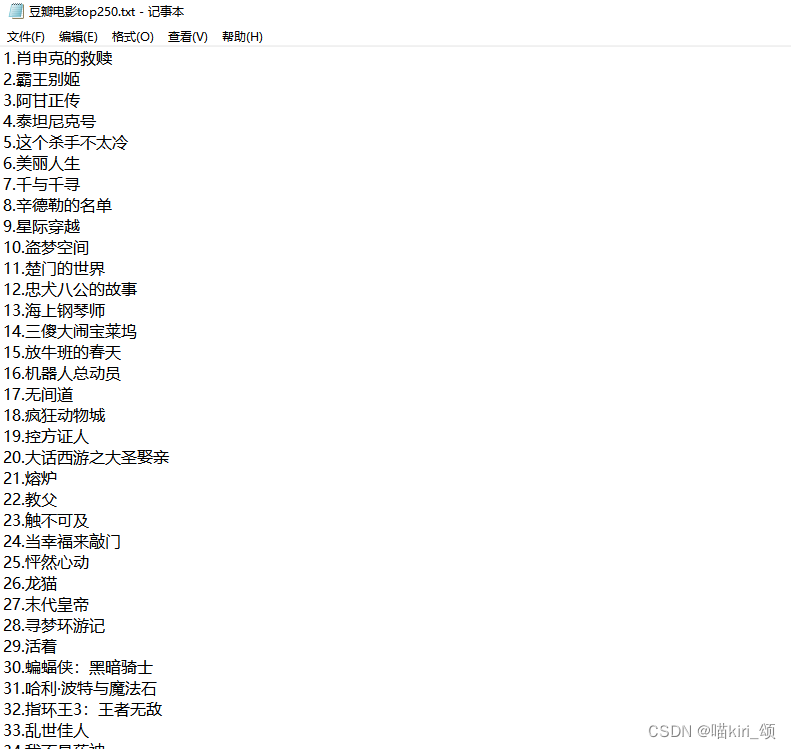
这样就将爬取的内容写入了本地文件,将爬取内容写入本地文件后主要是方便于后续做数据分析或可视化(尤其是对于那些实时性更新在网站上的数据)
爬取其他信息及处理
如果我还想爬取评分信息,则方法同理:
import bs4 as B
import requests
header={
"User-Agent":""
}
i=1
title_list,grade_list=[],[]
f=open("豆瓣电影top250.txt","w")
for num in range(0,250,25):
content=requests.get(f"https://movie.douban.com/top250?start={num}&filter=",headers=header)
all_html=B.BeautifulSoup(content.text)
all_titles = all_html.findAll("span",attrs={"class":"title"})
all_grades = all_html.findAll("span", attrs={"class": "rating_num"})
for title in all_titles:#用title_list存储影片名信息
cont=title.string
if "/" not in cont:
title_list+=[str(i + 1) + "." + title.string]
i += 1
for grade in all_grades:#用grade_list存储评分信息
grade_list+=[grade.string]
i=0
while True:
try:
f.write(title_list[i] + grade_list[i] + "\n")#结合再写入
i+=1
except:break
f.close()但是考虑到没有for title,grade in all_titles,all_grades:的循环方法。所以用一个列表分类存储当前爬取的信息,获得影片名称和评分列表后,再另外用循环组合字符串后写入。
try的用法:
尝试去执行try下的代码,如果报错,则执行except下的语句,并且报错后无论程序如何爆炸都执行finally下的语句。
如果是某种具体报错比如TypeError,则会再except中找是否有except TypeError,若有,则执行except TypeError下的语句(类似于if-elif)

可以看到效果很好,同理如果需要更多信息,也是类似的方法:爬取信息后用容器存储,然后按自定义格式组合字符串再写入。
总结
在本次练习中,我爬取了影片名,评分,年份,地区,类型信息并写入了文件
以下是完整代码:("User-Agent"信息根据自己浏览器用户信息填写)
import bs4 as B
import requests
header={
"User-Agent":""
}
title_list,grade_list,info_list=[],[],[]
for num in range(0,250,25):
content=requests.get(f"https://movie.douban.com/top250?start={num}&filter=",headers=header)
soup=B.BeautifulSoup(content.text,"html.parser")
all_titles=soup.findAll("span",attrs={"class":"title"})
all_grade=soup.findAll("span",attrs={"class":"rating_num"})
all_infos=soup.findAll("p",attrs={"class":""})
for intro in all_infos:
with open("change.txt","w",encoding="utf-8") as f:
f.write(str(intro))
with open("change.txt","r",encoding="utf-8") as f:
for i in range(3):
strrr=f.readline()
i,item=0,0
years,country,mtype="","",""
for m in strrr:
if m=="/":
item+=1
elif item==0:
if m!=" ":
years+=m
elif item==1:
if m!="\t":
country+=m
else:country+=","
elif item==2:
if m=="\n":
break
if m!="\t":
mtype+=m
else:mtype += ","
info_list+=["年份:"+years+"/国家:"+country+"/类型:"+mtype]
for title in all_titles:
cont=title.string
if "/" not in cont:
title_list+=[title.string]
for grade in all_grade:
grade_list += [grade.string]
i=0
f=open("豆瓣电影top250名单.txt","w",encoding="utf-8")
while True:
try:
line=str(i+1)+"."+title_list[i] + "\n评分:" + grade_list[i] + "\n信息(" +info_list[i]+")\n"
print(line)
f.write(line+"\n")
except:
print("//电影展示完毕//")
break
i+=1由于年份,地区,类型信息的标签中仍带有<br/>标签(html中的换行)无法用.string转化成字符串内容,在此我用的str()直接python的字符串强制转换,然后再写入文件change.txt(过渡文件),提取其中的第三行再字符串处理(实属是粗暴了点...)
可以看到,效果还是很棒滴捏!

今天的教学就到这里啦,拜拜!
欢迎交流,评论,指正!















 1770
1770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









