







在写关于教育数字化的东西,希望能嵌入一些数据分析,而非纯纯的语言性表述,在查阅了这方面的各种文献后,以下这篇让我觉得在方法上有一定借鉴意义:
[1]钟羽, 王觅, 郭心懿. 基础教育信息化研究热点与趋势分析——基于知识图谱的视角[J]. 现代教育科学, 2021(6):6.
文章研究流程大致遵循文献检索、词频统计、 相异矩阵生成、 聚类分析,最后通过多维尺度描绘知识图谱。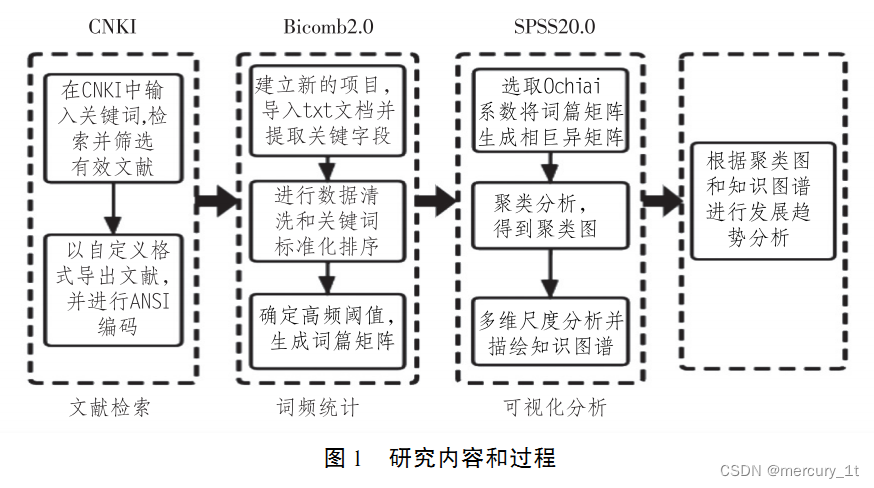
现在人在行业外,手头的工具自然有限,好在anaconda还是装了,用jupyter notebook还可以进行一些简单的动作。
素材
在“宝山教育”公众号以“教育数字化”为关键词检索历史信息,将相关的21篇内容保存到txt中,作为本次分析的素材。(由于没搞定微信的批量下载,一篇篇点开时大致过了下内容,将相关性不大的,比如只是年度工作总结中提了一下这词的文章就略去,最后剩下21篇手动复制)。
流程
1、数据读取
2、词频分析
3、共现矩阵及相异矩阵构建
4、层次聚类分析
准备工作
中文文本分析,分词是最基础的,“jieba”是其中比较常用的一个库。
一般缺少的库都会直接使用“pip install xxx”的方式下载,但在jieba的pip安装时发生了time out 报错。在https://www.lfd.uci.edu/~gohlke/pythonlibs/ 这个经常使用的第三方下载网站也没找到,于是检索了一下,使用国内镜像进行尝试并成功:
pip3 install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple/而制作图云的wordcloud可以直接使用“pip install wordcloud”下载。
此外,本次还涉及的库有:
# load data
import os
# word segmentation and word cloud
import jieba
import numpy as np
import PIL.Image as Image
from wordcloud import WordCloud
# build count matrix by the code 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 905
905











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









