









一、介绍
一个基于Python的食物识别系统开发项目。该项目通过构建包含11种常见食物类别(包括’Bread’, ‘Dairy product’, ‘Dessert’, ‘Egg’, ‘Fried food’, ‘Meat’, ‘Noodles-Pasta’, ‘Rice’, ‘Seafood’, ‘Soup’, ‘Vegetable-Fruit’)的图片数据集,并利用TensorFlow框架下的ResNet50神经网络模型进行开发。项目流程包括数据预处理和模型训练,最终生成一个高精度的H5模型文件用于识别。此外,系统还整合了Django框架,开发了一个网页平台,使用户能够上传食物图片并快速识别出食物名称。
二、效果图片

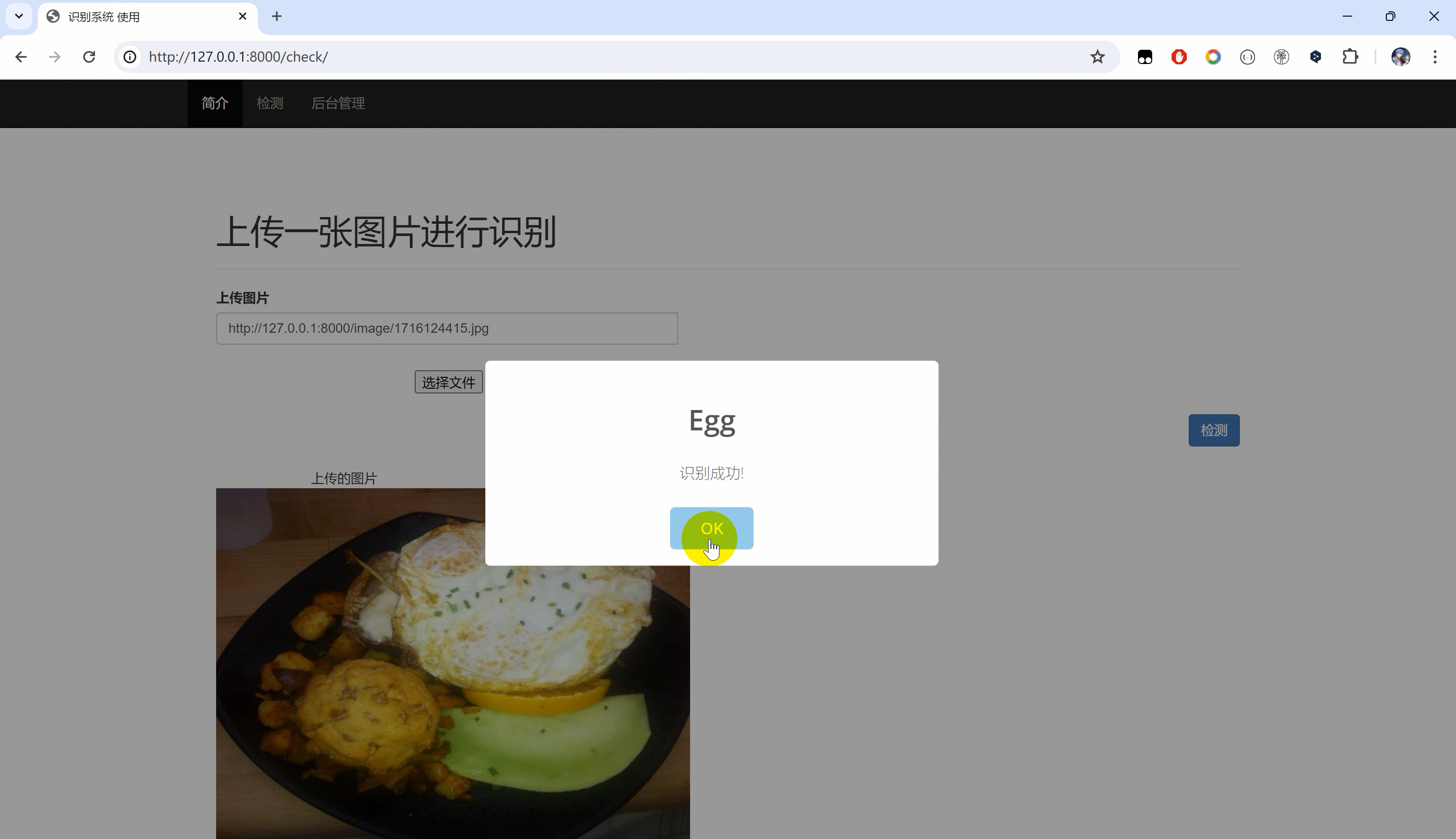
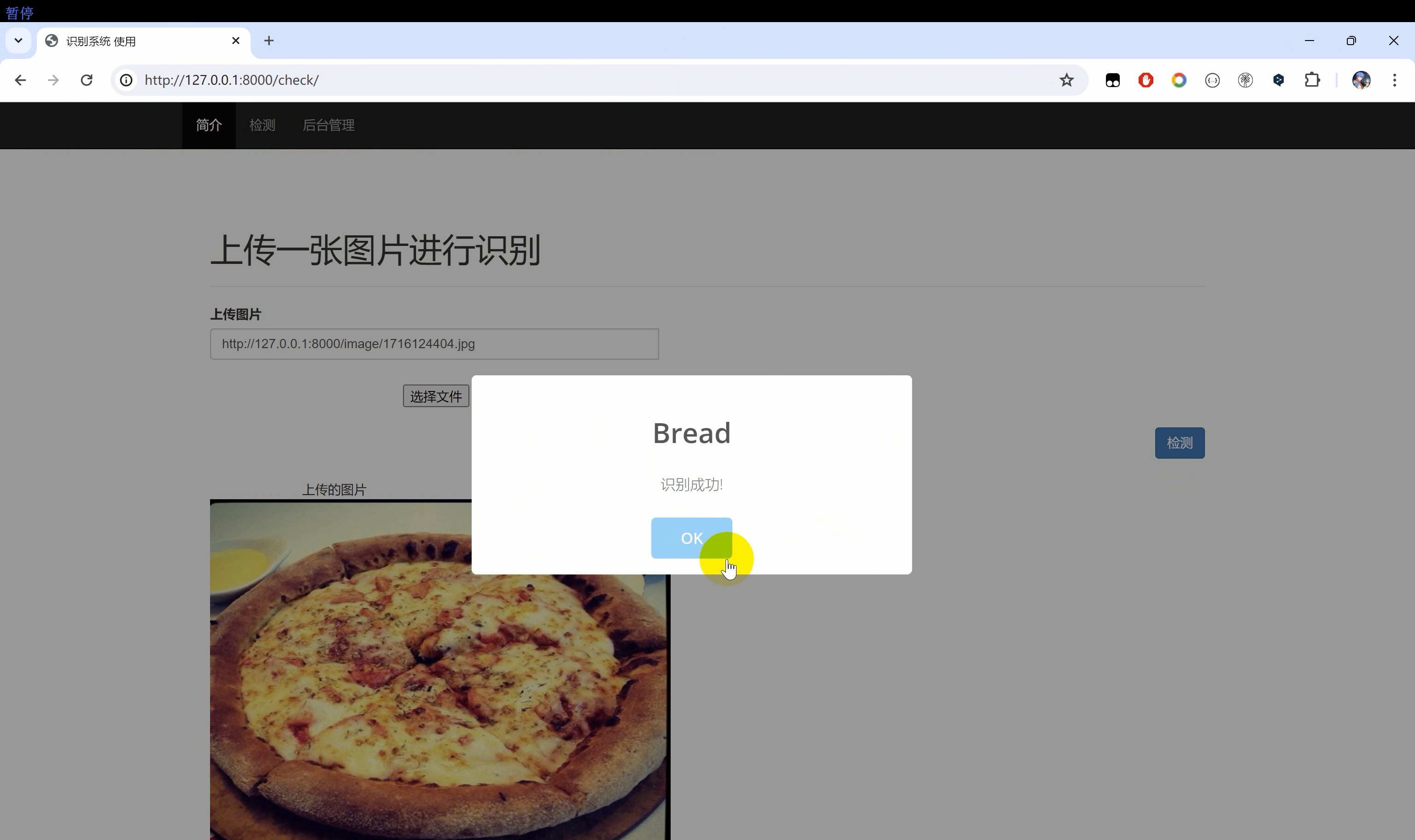
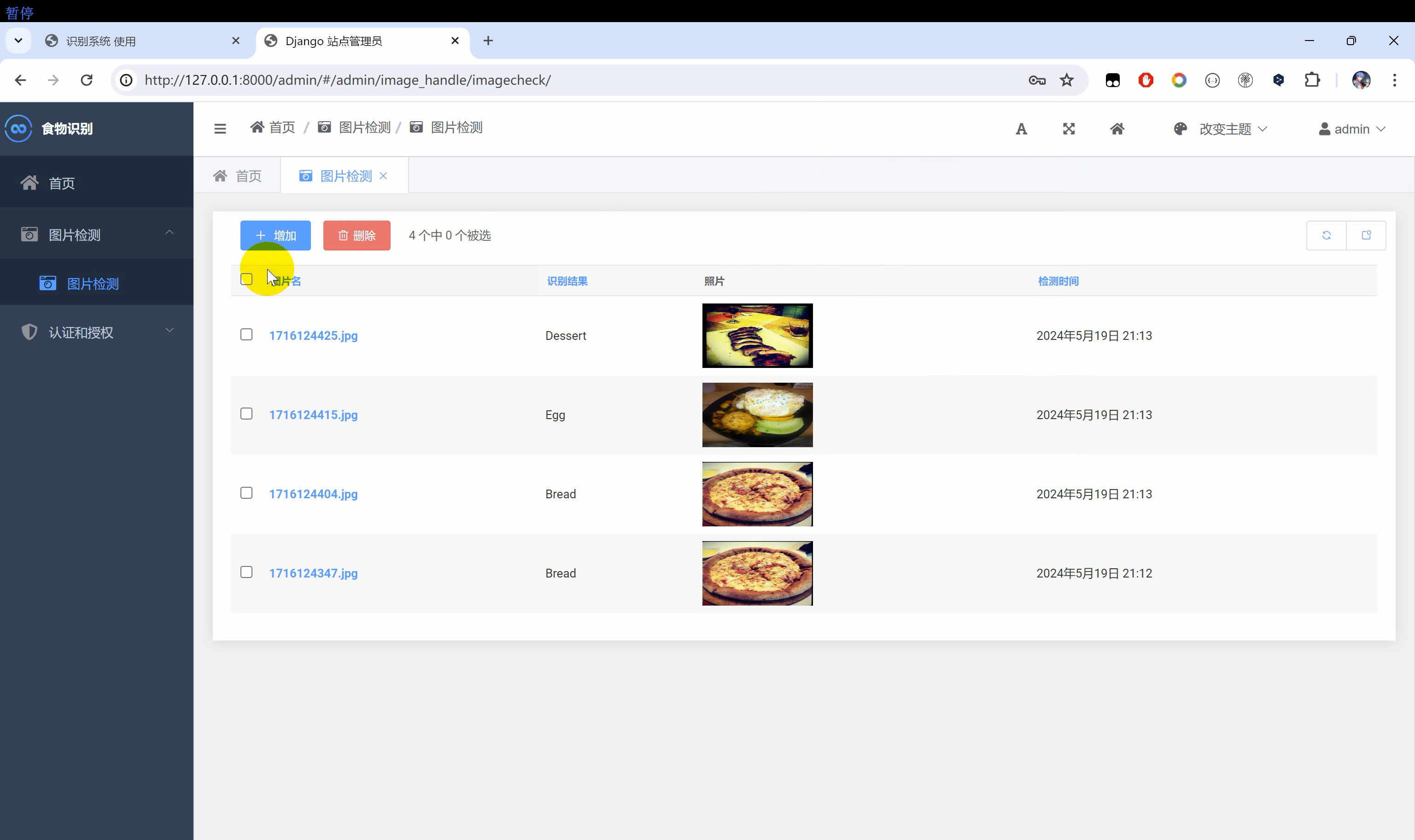
三、演示视频 and 代码 and 安装
地址:https://www.yuque.com/ziwu/yygu3z/yhd6a7vai4o9iuys
四、深度学习卷积神经网络算法
深度学习中的卷积神经网络(CNN)是图像识别领域应用最广泛的算法之一。CNN通过模仿人类的视觉系统结构设计而成,主要包括卷积层、池化层和全连接层。卷积层通过滤波器从图像中提取特征,池化层则用于降低特征的空间维度,增强模型的泛化能力。全连接层则负责将提取的特征转化为最终的分类结果。
CNN在图像识别中的一个关键优势是其局部感受野的设计,能够捕捉到图像局部的特征,并保持空间层次的信息。此外,权重共享机制减少了模型的参数数量,使得训练更加高效。这些特性使CNN特别适用于处理具有强烈空间相关性的图像数据。
在实际应用中,CNN已被广泛应用于面部识别、自动驾驶车辆的视觉系统、医疗图像分析等多个领域。例如,在医疗领域,CNN能够帮助识别和分类各种疾病的影像资料,如肺部X光片中的异常结构。
下面是一个使用TensorFlow框架的简单图像识别的例子,将使用经典的MNIST手写数字数据集来训练一个简单的CNN模型:
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
# 加载数据集
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
# 数据预处理,添加一个通道维度,并归一化
train_images = train_images.reshape((60000, 28, 28, 1)).astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1)).astype('float32') / 255
# 构建CNN模型
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
# 添加全连接层和输出层
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
# 编译和训练模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))
# 评估模型
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print(f'测试精度: {test_acc:.4f}')
这个简单的CNN模型通过卷积层提取特征demo案例,并通过全连接层进行分类,实现手写数字识别案例。














 1149
1149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









