






一、介绍
雪花算法(Snowflake)是一种由 Twitter 开源的分布式唯一ID生成算法,用于在高并发分布式系统下生成全局唯一、递增的长整型ID。
| 时间戳 | 数据中心ID | 机器ID | 序列号 |
|---|---|---|---|
| 41位 | 5位 | 5位 | 12位 |
具体含义:
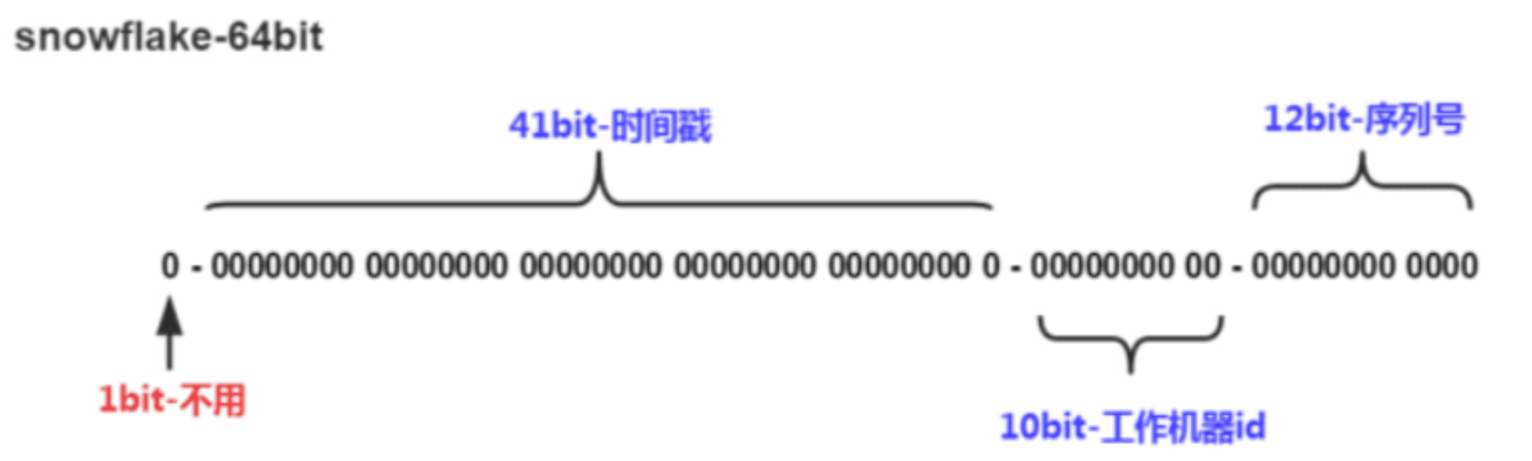
- 第1位占用1bit,其值始终是0,可看做是符号位不使用。
- 41位时间戳:毫秒级,能用69年(2^41毫秒)
- 5位数据中心ID:支持32个数据中心
- 5位机器ID:支持每个数据中心32台机器
- 12位序列号:每毫秒同一机器可生成4096个不同ID
最终组成64位整数,既保证唯一性,也能做到大致有序(递增)。
二、与其他ID方案对比
| 方案 | 格式 | 唯一性 | 有序性 | 性能 | 适用场景 |
|---|---|---|---|---|---|
| 雪花算法 | 64位整型 | 很高(全局) | 是(时间排序) | 非常高(本地生成) | 分布式系统 |
| UUID | 128位字符串 | 极高(全局) | 否 | 较高(本地生成) | 分布式、无序唯一 |
| 自增ID | 整型 | 仅表内唯一 | 是 | 依赖DB/缓存 | 单机、简单场景 |
三、雪花算法优势
- 高性能、本地生成:不依赖数据库或第三方服务,单台可毫秒生成数千个ID
- 分布式唯一性强:不重复、可控
- 有序递增:带有时间戳,ID基本有序,有利于数据库索引
- 存储高效:64位long型,存储和索引效率高(远小于UUID)
- 可扩展性强:支持多机房、多节点并发
UUID的特点和劣势:
- 高唯一性:全球唯一,冲突概率极低
- 无序、字符串型:UUID 不带时间,不递增,作为主键时插入、索引效率低
- 存储空间大:128位,通常以36字符字符串存储(如 550e8400-e29b-41d4-a716-446655440000)
自增ID劣势
- 分布式难协调,跨库唯一性难保证
- 安全性差,容易被猜测(业务有安全要求时不推荐)
- 分布式难协调,跨库唯一性难保证
四、场景案例
业务场景:
● 服务目前QPS10万,预计几年之内会发展到百万。
● 当前机器三地部署,上海,北京,深圳都有。
● 当前机器10台左右,预计未来会增加至百台。
这个时候我们根据上面的场景可以再次合理的划分64bit,QPS几年之内会发展到百万,那么每毫秒就是千级的请求,目前10台机器那么每台机器承担百级的请求,为了保证扩展,后面的循环位可以限制到1024,也就是2^10,那么循环位10位就足够了。
机器三地部署我们可以用3bit总共8来表示机房位置,当前的机器10台,为了保证扩展到百台那么可以用7bit 128来表示,时间位依然是41bit,那么还剩下64-10-3-7-41-1 = 2bit,还剩下2bit可以用来进行扩展。

五、时钟回拨
因为机器的原因会发生时间回拨,我们的雪花算法是强依赖我们的时间的,如果时间发生回拨,有可能会生成重复的ID。我们可以用当前时间和上一次的时间进行判断,如果当前时间小于上一次的时间那么肯定是发生了回拨,算法会直接抛出异常。
六、代码实现
示例代码:
# snowflake.py
# Twitter's Snowflake algorithm implementation which is used to generate distributed IDs.
# https://github.com/twitter-archive/snowflake/blob/snowflake-2010/src/main/scala/com/twitter/service/snowflake/IdWorker.scala
import time
# 64位ID的划分
WORKER_ID_BITS = 5
DATACENTER_ID_BITS = 5
SEQUENCE_BITS = 12
# 最大取值计算
MAX_WORKER_ID = -1 ^ (-1 << WORKER_ID_BITS) # 2**5-1 0b11111
MAX_DATACENTER_ID = -1 ^ (-1 << DATACENTER_ID_BITS)
# 移位偏移计算
WOKER_ID_SHIFT = SEQUENCE_BITS
DATACENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS
TIMESTAMP_LEFT_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATACENTER_ID_BITS
# 序号循环掩码
SEQUENCE_MASK = -1 ^ (-1 << SEQUENCE_BITS)
# Twitter元年时间戳
TWEPOCH = 1288834974657
class ClockBackwardsException(Exception):
"""时钟回拨异常"""
def __init__(self, last_timestamp, current_timestamp):
super().__init__(
f"时钟回拨异常:当前时间戳 {current_timestamp} 小于上次生成ID的时间戳 {last_timestamp},系统拒绝生成ID!")
self.last_timestamp = last_timestamp
self.current_timestamp = current_timestamp
class Snowflake(object):
"""
用于生成IDs
"""
def __init__(self, datacenter_id, worker_id, sequence=0):
"""
初始化
:param datacenter_id: 数据中心(机器区域)ID
:param worker_id: 机器ID
:param sequence: 序号
"""
# sanity check
if worker_id > MAX_WORKER_ID or worker_id < 0:
raise ValueError('worker_id值越界')
if datacenter_id > MAX_DATACENTER_ID or datacenter_id < 0:
raise ValueError('datacenter_id值越界')
self.worker_id = worker_id
self.datacenter_id = datacenter_id
self.sequence = sequence
self.last_timestamp = -1 # 上次计算的时间戳
def _gen_timestamp(self):
"""
生成整数时间戳
:return:int timestamp
"""
return int(time.time() * 1000)
def get_id(self):
"""
获取新ID
:return:
"""
timestamp = self._gen_timestamp()
# 时钟回拨
if timestamp < self.last_timestamp:
raise ClockBackwardsException(self.last_timestamp, timestamp)
if timestamp == self.last_timestamp:
self.sequence = (self.sequence + 1) & SEQUENCE_MASK
if self.sequence == 0:
timestamp = self._til_next_millis(self.last_timestamp)
else:
self.sequence = 0
self.last_timestamp = timestamp
new_id = ((timestamp - TWEPOCH) << TIMESTAMP_LEFT_SHIFT) | (self.datacenter_id << DATACENTER_ID_SHIFT) | \
(self.worker_id << WOKER_ID_SHIFT) | self.sequence
return new_id
def _til_next_millis(self, last_timestamp):
"""
等到下一毫秒
"""
timestamp = self._gen_timestamp()
while timestamp <= last_timestamp:
timestamp = self._gen_timestamp()
return timestamp
# settings中配置数据中心 和 机器号
# 这个地方是写死的,后续如果部署到服务器上,可以使用读取环境变量的形式
# 数据中心标识、机器号标识
DATACENTER_ID = 0
WORKER_ID = 0
user.py模型中进行修改
from . import Base
from sqlalchemy import Column, BigInteger
from utils.snowflake import Snowflake
from settings import DATACENTER_ID, WORKER_ID
snowflake = Snowflake(DATACENTER_ID, WORKER_ID)
def generate_snowflake_id():
new_id = snowflake.get_id()
return new_id
class User(Base):
__tablename__ = 'user'
id = Column(BigInteger, primary_key=True, default=generate_snowflake_id)

















 964
964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









