









一.算法介绍
回归树指的是用来解决回归问题的树模型,之前介绍过的决策树可以视为一种特殊的回归树。
1.模型
回归树是对数据空间进行线性切分,得到多个Rm。每个Rm代表着一块区域,这块区域的样本点的输出值设为一个常数。
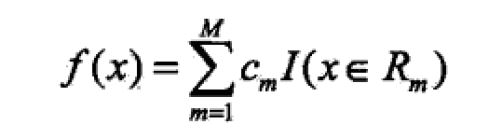
2.策略
为了针对训练数据求解到一个合适的回归树,关键问题有两个:如何划分数据空间 每个数据空间的输出值设为多少。回归树模型采用的损失函数是平方误差,策略即是:
最小化
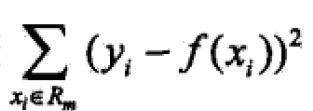
3.算法
回归树采用启发式的方法。假定输入样本是n维的(x1,x2…,xn),那么回归树每次是希望选取xj和它所取的值s,作为切分变量来对数据空间进行切分。在实际操作中,回归树会遍历每个xi(i=1…n)和每个xi可取的阈值。对于每个遍历得到的(xi,s)组合,回归树都可以将数据空间分成两个子空间:R1 R2。R1空间的输出值选为R空间的样本点输出值的平均值,R2亦然。然后统计R1+R2的均方误差。最后选取均方误差最小的(xj,s)组合对样本数据空间进行第一次划分。之后对R1,R2会继续递归的重复过程,直至满足预先设定的阈值。

相比于分类决策树,回归树的计算复杂度要高些。分类决策树是利用信息熵的差值来选取每轮的分类特征和阈值,回归树则需要遍历所有的可能性。
《统计学习方法》对回归树这块介绍的不够详细。相反,《机器学习实战》对回归树这块的介绍很好,我个人觉得收获蛮大,值得仔细看看。
回归树建立的模型还是蛮强大的,但是应该容易产生过拟合。之后有时间准备研究下随机森林模型。
二.python实现
def chooseBestSplit(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):
tolS = ops[0]; tolN = ops[1]
#if all the target variables are the same value: quit and return value
if len(set(dataSet[:,-1].T.tolist()[0])) == 1: #exit cond 1
return None, leafType(dataSet)
m,n = shape(dataSet)
#the choice of the best feature is driven by Reduction in RSS error from mean
S = errType(dataSet)
bestS = inf; bestIndex = 0; bestValue = 0
for featIndex in range(n-1):
for splitVal in (dataSet[:,featIndex]):
mat0, mat1 = binSplitDataSet(dataSet, featIndex, splitVal)
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): continue
newS = errType(mat0) + errType(mat1)
if newS < bestS:
bestIndex = featIndex
bestValue = splitVal
bestS = newS
#if the decrease (S-bestS) is less than a threshold don't do the split
if (S - bestS) < tolS:
return None, leafType(dataSet) #exit cond 2
mat0, mat1 = binSplitDataSet(dataSet, bestIndex, bestValue)
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): #exit cond 3
return None, leafType(dataSet)
return bestIndex,bestValue#returns the best feature to split on
#and the value used for that split
def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):#assume dataSet is NumPy Mat so we can array filtering
feat, val = chooseBestSplit(dataSet, leafType, errType, ops)#choose the best split
if feat == None: return val #if the splitting hit a stop condition return val
retTree = {}
retTree['spInd'] = feat
retTree['spVal'] = val
lSet, rSet = binSplitDataSet(dataSet, feat, val)
retTree['left'] = createTree(lSet, leafType, errType, ops)
retTree['right'] = createTree(rSet, leafType, errType, ops)
return retTree 














 3089
3089











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









