









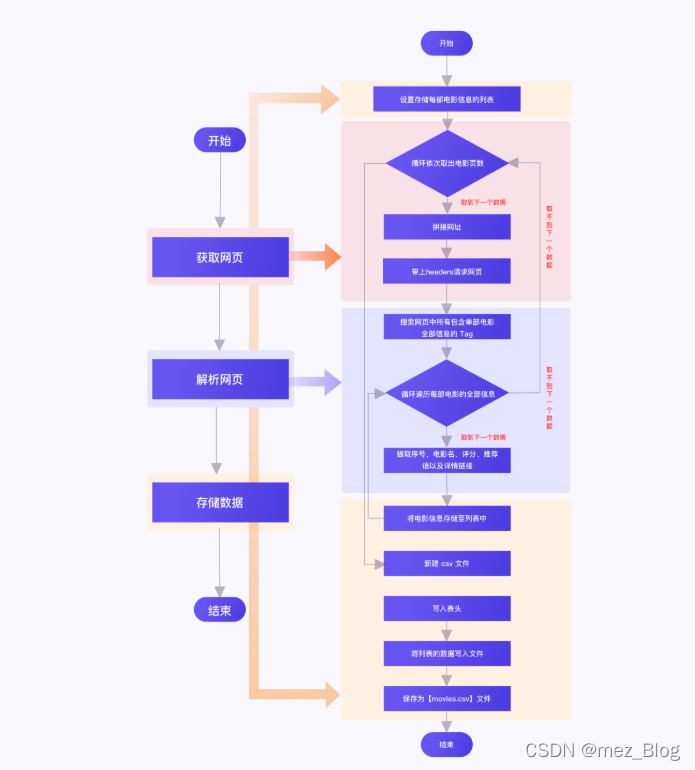
网站爬取的流程图:
实现项目我们需要运用以下几个知识点
一、获取网页
1.找网页规律;
2.使用 for 循环语句获得网站前4页的网页链接;
3.使用 Network 选项卡查找Headers信息;
4.使用 requests.get() 函数带着 Headers 请求网页。
二、解析网页
1.使用 BeautifulSoup 解析网页;
2.使用 BeautifulSoup 对象调用 find_all() 方法定位包含单部电影全部信息的标签;
3.使用 Tag.text 提取序号、电影名、评分、推荐语;
4.使用 Tag['属性名'] 提取电影详情链接。
三、存储数据
1.使用 with open() as … 创建要写入内容的 csv 文件;
2.使用 csv.DictWriter() 将文件对象转换为 DictWriter 对象;
3.参数 fieldnames 用来设置 csv 文件的表头;
4.使用 writeheader() 写入表头;
5.使用 writerows() 将内容写入 csv 文件。
实现代码:
import csv
import requests
from bs4 import BeautifulSoup
# 设置列表,用以存储每部电影的信息
data_list = []
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
# 使用 for 循环遍历取值范围为 0~3 的数据
for page_number in range(4):
# 设置要请求的网页链接
url = 'https://movie.douban.com/top250?start={}&filter='.format(page_number * 25)
# 请求网页
movies_list_res = requests.get(url, headers=headers)
# 解析请求到的网页内容
bs = BeautifulSoup(movies_list_res.text, 'html.parser')
# 搜索网页中所有包含单部电影全部信息的 Tag
movies_list = bs.find_all('div', class_='item')
# 使用 for 循环遍历搜索结果
for movie in movies_list:
# 提取电影的序号
movie_num = movie.find('em').text
# 提取电影名
movie_name = movie.find('span').text
# 提取电影的评分
movie_score = movie.find("span",class_='rating_num').text
# 提取电影的推荐语
movie_instruction = movie.find("span",class_='inq').text
# 提取电影的链接
movie_link = movie.find('a')['href']
# 将信息添加到字典中
movie_dict = {
'序号': movie_num,
'电影名': movie_name,
'评分': movie_score,
'推荐语': movie_instruction,
'链接': movie_link
}
# 打印电影的信息
print(movie_dict)
# 存储每部电影的信息
data_list.append(movie_dict)
# 新建 csv 文件,用以存储电影信息
with open('movies.csv', 'w', encoding='utf-8-sig') as f:
# 将文件对象转换成 DictWriter 对象
f_csv = csv.DictWriter(f, fieldnames=['序号', '电影名', '评分', '推荐语', '链接'])
# 写入表头与数据
f_csv.writeheader()
f_csv.writerows(data_list)代码分析:
(1)通过观察网站一页的电影数,可以发现一页只有 25 部电影的信息。
也就是说我们需要爬取网站前4页(100 = 25*4)的电影信息。

这里我们使用了遍历,爬取前四页的数据。
(2)通过快捷键打开网页的开发者工具(Windows 用户可以在浏览器页面下按 Ctrl + Shift + I 键或者直接F12唤出浏览器开发者工具,Mac 用户的快捷键为 command + option + I)。
接着使用开发者工具中的指针工具,大致查看一下前两部电影中,需爬取的信息所在位置,观察一下其中是否有什么规律。
可以发现第一部电影里序号、电影名、评分、推荐语以及详情链接在class属性值为"item"的标签里。

(3)豆瓣电影 Top250 的 Robots 协议

并没有看到Disallow: /Top250,这说明可以对这个网页进行爬取。
(4)在互联网世界中,网络请求会将浏览器信息储存在请求头(Request Header)当中。
只要我们将浏览器信息复制下来,在爬虫程序只要在发起请求时,设置好与请求头对应的参数,即可成功伪装成浏览器。

(5)代码思路
1)熟练地使用开发者工具的指针工具,可以很方便地帮助我们定位数据。
2)用指针工具定位到各个数据所在位置后,查看它们的规律。
3)想要提取的标签如果具有属性,可以使用 Tag.find(HTML元素名, HTML属性名='')来提取;没有属性的话,可以在这个标签附近找到一个有属性的标签,然后再进行 find() 提取。
通过上述步骤将信息爬取下来后,就走到我们爬虫的最后一步——存储数据。
(6)存储数据
1)调用 csv 模块中类 DictWriter 的语法为:csv.DictWriter(f, fieldnames)。语法中的参数 f 是 open() 函数打开的文件对象;参数 fieldnames 用来设置文件的表头;
2)执行csv.DictWriter(f, fieldnames)后会得到一个 DictWriter 对象;
3)得到的 DictWriter 对象可以调用 writeheader() 方法,将 fieldnames 写入 csv 的第一行;
4)最后,调用 writerows() 方法将多个字典写进 csv 文件中。
运行结果:

生成的CSV文件:

















 860
860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











