








爬虫又称为网页蜘蛛,是一种程序或脚本。
但重点在于,它能够按照一定的规则,自动获取网页信息。
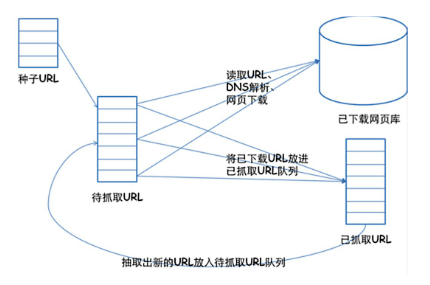
爬虫的基本原理——通用框架
1.挑选种子URL;
2.讲这些URL放入带抓取的URL列队;
3.取出带抓取的URL,下载并存储进已下载网页库中。此外,讲这些URL放入带抓取URL列队,进入下一循环。
4.分析已抓取列队中的URL,并且将URL放入带抓取URL列队,从而进去下一循环。
爬虫获取网页信息和人工获取信息,其实原理是一致的。
如我们要获取电影的“评分”信息

人工操作步骤:
1.获取电影信息的网页;
2.定位(找到)要评分信息的位置;
3.复制、保存我们想要的评分数据。
爬虫操作步骤:
1.请求并下载电影页面信息;
2.解析并定位评分信息;
3.保存评分数据。
爬虫的基本流程
简单来说,我们向服务器发送请求后,会得到返回的页面,通过解析页面后,我们可以抽取我们想要的那部分信息,并存储在指定文档或数据库中,这样,我们想要的信息会被我们“爬”下来了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 857
857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









