







 本文探讨了在开发过程中遇到的爬虫问题,涉及JSONDecodeError的解决,包括Unicode编码解码、hosts文件修改与requests头设置,详细展示了遇到的问题及有效解决策略。
本文探讨了在开发过程中遇到的爬虫问题,涉及JSONDecodeError的解决,包括Unicode编码解码、hosts文件修改与requests头设置,详细展示了遇到的问题及有效解决策略。
本节将介绍本人在开发过程中遇到的一些问题。
首先是面临着程序虽然能够正常运行,但是点击查询并不出现效果,并出现强退的场景。
原因:爬取网页时出现json.decoder.JSONDecodeError
解决方案:在经过网上查询后,得到了几种解决方案。举例如下:
1.Unicode编码的解码问题。
当我们在爬取一些网页时,有些网页的内容是通过Unicode字符编码进行传输的,比如:
s="\u7b14\u8bb0\u672c\u7535\u8111\u4ea4\u6d41\uff1a834237275\uff0c\u8be6\u7ec6\u54a8\u8be2\u8bf7\u8d70\u4ed8\u8d39\u54a8\u8be2\u3002"
如果我们想让它正常显示,解决方式为:
爬虫解码法
1 import requests
2
3 reps = requests.get(url=url)
4 reps.content.decode("utf-8")
5 #或者使用这条语句 reps.content.decode("unicode_escape")但是有的时候我们运行时下面那条被注释的语句又能正常运行,但是有时候又会报错误,也就是题目中的错误,所以,我们如果想要正常显示的话那就使用“utf-8”进行解码。
个人尝试,这种方法不行。出现了时而可以运行,时而不能运行【大部分情况下不能运行】
2.在hosts中加入12306的固定域名解析
打开cmd
输入 nslookup 命令并访问域名对象 kyfw.12306.cn ,查询域名对应的所有实际ip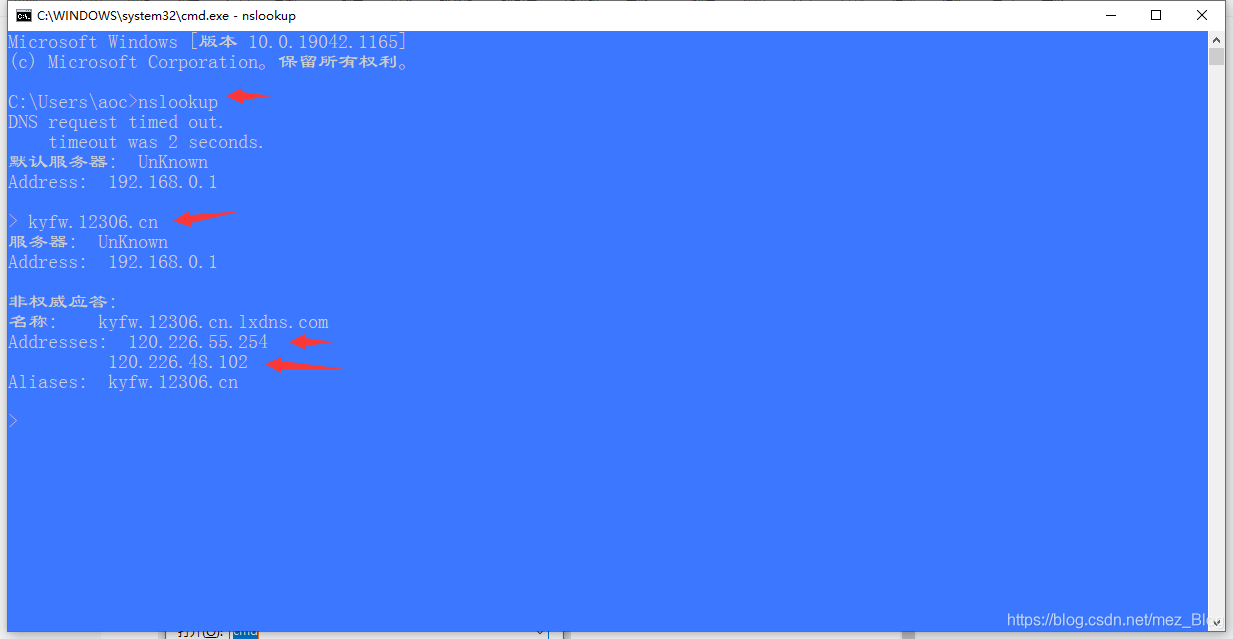
找到 hosts文件 ,在windows中hosts文件路径:C:\Windows\System32\drivers\etc
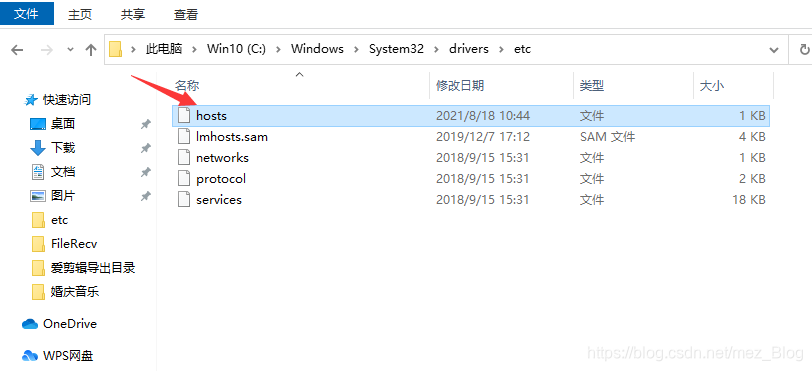
在hosts文件最后新增两行内容:120.226.55.254 kyfw.12306.cn
120.226.48.102 kyfw.12306.cn
但是由于本人电脑的hosts内容为空,我们可以进行编辑:
# Copyright (c) 1993-1999 Microsoft Corp.
#
# This is a sample HOSTS file used by Microsoft TCP/IP for Windows.
#
# This file contains the mappings of IP addresses to host names. Each
# entry should be kept on an individual line. The IP address should
# be placed in the first column followed by the corresponding host name.
# The IP address and the host name should be separated by at least one
# space.
#
# Additionally, comments (such as these) may be inserted on individual
# lines or following the machine name denoted by a '#' symbol.
#
# For example:
#
# 102.54.94.97 rhino.acme.com # source server
# 38.25.63.10 x.acme.com # x client host
127.0.0.1 localhost这里可以直接进行复制,因为所有的hosts文件都是上面都是一样的,然后我们在最后添加刚才的地址和域名。完整的代码如下:
# Copyright (c) 1993-1999 Microsoft Corp.
#
# This is a sample HOSTS file used by Microsoft TCP/IP for Windows.
#
# This file contains the mappings of IP addresses to host names. Each
# entry should be kept on an individual line. The IP address should
# be placed in the first column followed by the corresponding host name.
# The IP address and the host name should be separated by at least one
# space.
#
# Additionally, comments (such as these) may be inserted on individual
# lines or following the machine name denoted by a '#' symbol.
#
# For example:
#
# 102.54.94.97 rhino.acme.com # source server
# 38.25.63.10 x.acme.com # x client host
127.0.0.1 localhost
120.226.55.254 kyfw.12306.cn
120.226.48.102 kyfw.12306.cn 然后Ctrl+s保存,此时发现不能直接保存,那我们就先存为text文件到桌面。然后从桌面复制或剪切到该目录,进行文件替换。注意:要删去文件后缀名,因为系统文件是没有后缀名的。
个人尝试,这种方法不行。
3.requests_url不正确
使用浏览器中的网址作为url是不太规范的,所以我们尽量找到request_url中url部分的生成机制,构造出正确的request_url吧!从网页的源代码中,找到了url的生成机制。【意思就是不能直接用复制导航栏url的方式,而是在网页源码中使用真正的url】
错误url:
正确URL:
 这就需要慢慢看url代码找到对应的真正的url,我实在是看不下去了,就没有采用此种方法,至于可行性,大家可以自行验证。
这就需要慢慢看url代码找到对应的真正的url,我实在是看不下去了,就没有采用此种方法,至于可行性,大家可以自行验证。
4.添加header【本人尝试,可行,直接贴代码关键部分】
def getStation():
# 发送请求获取所有车站名称,通过输入的站名称转化查询地址的参数
# url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9006'
url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9201'
headers={
'Referer':'https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc&fs=%E5%8C%97%E4%BA%AC,BJP&ts=%E4%B8%8A%E6%B5%B7,SHH&date=2021-08-19&flag=N,N,Y',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:91.0) Gecko/20100101 Firefox/91.0'
}
response = requests.get(url, heraders=headers,verify=True) # 请求并进行验证
response.content.decode("utf-8")
#response.content.decode("unicode_escape")这里因为用到的url是两部分,这里增加了header后,另一个也需要添加。
def query(date, from_station, to_station):
data.clear() # 清空数据
# 查询请求地址
cookie='''_uab_collina=162924939911126111496577; JSESSIONID=CEEECF63AAAFADCE84C14B125B0BAF33; BIGipServerotn=569377290.38945.0000; RAIL_EXPIRATION=1629515371138; RAIL_DEVICEID=WFdNvPKASOeg84FkzqmTwo2V9HOZ6PCi13Lo07y6AhvsDwxtH1RABivB_bw-vQMlxSMsGwtFKOTfbxEc62F2DgkmiF_j_Hlgro1ClJXVYItFRoWurt7-HkK3S634C9mkoLsQfZk9xvy_Y1_-sbJCQvt8VE1XIoU1; BIGipServerpool_passport=199492106.50215.0000; route=9036359bb8a8a461c164a04f8f50b252; _jc_save_fromStation=%u5317%u4EAC%2CBJP; _jc_save_toStation=%u4E0A%u6D77%2CSHH; _jc_save_fromDate=2021-08-19; _jc_save_toDate=2021-08-18; _jc_save_wfdc_flag=dc'''
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:91.0) Gecko/20100101 Firefox/91.0',
'Connection':'keep-alive',
'accept':'*/*',
'Cookie':cookie
}
url = 'https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date={}&leftTicketDTO.from_station={}&leftTicketDTO.to_station={}&purpose_codes=ADULT'.format(
date, from_station, to_station)
# 发送查询请求
response = requests.get(url,headers=header)
# # 将json数据转换为字典类型,通过键值对取数据
result = response.json()
result = result['data']['result']header的参数哪里找?当然还是网络监控器那里了!
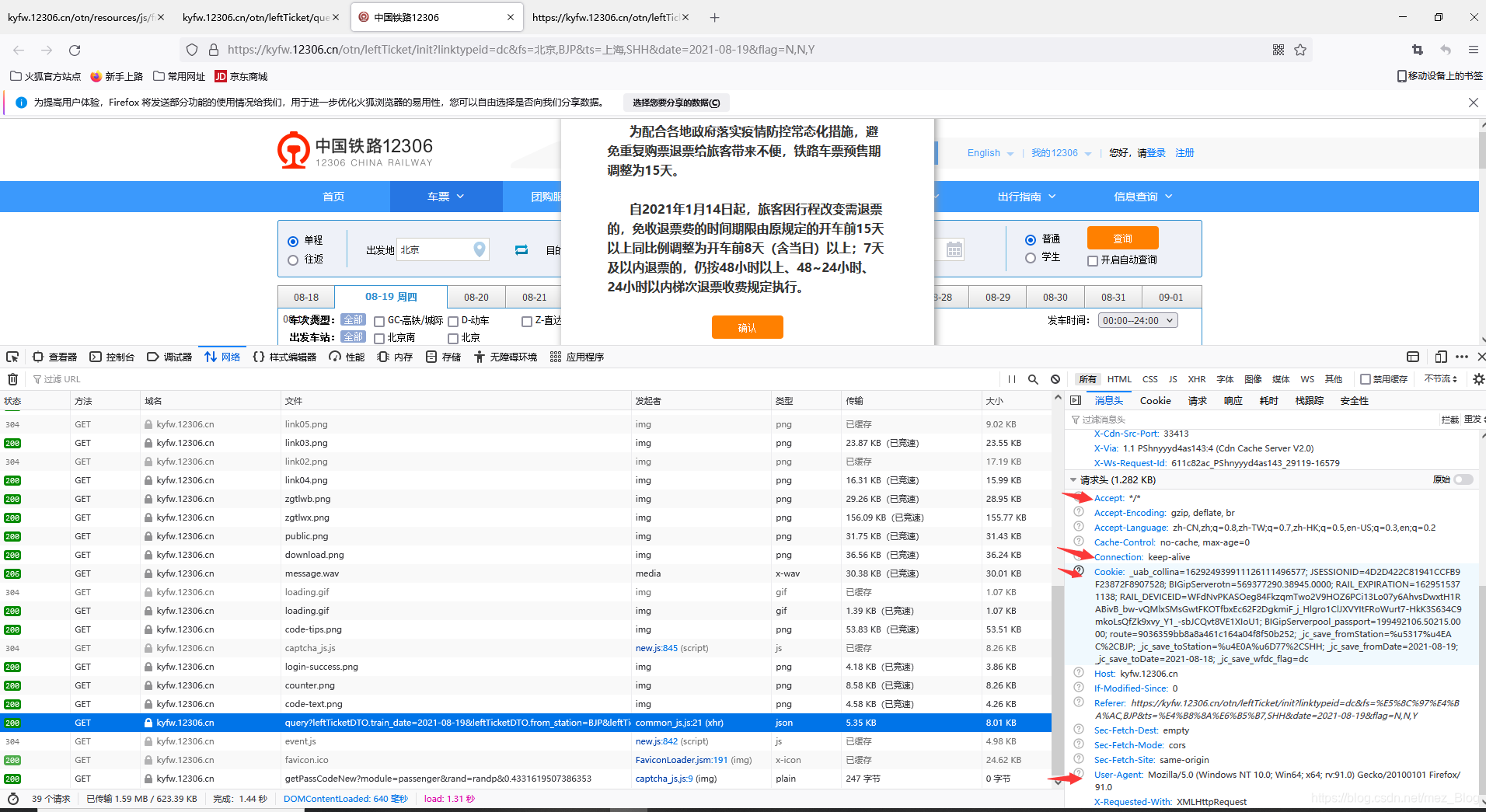
都设置好后,就能正常运行并显示了。这些就是我这此次程序设计中遇到的问题和解决方式,希望可以给大家做个参考^_^。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











