







本节开始介绍搜索漏斗架构中的粗排阶段,粗排阶段的目标是从约上万级别的候选中筛选出合规、相关且成交效率高的topN商品,这里N通常是上千量级。而在粗排架构下,排序分可以简化为以下表达:
本节开始介绍搜索漏斗架构中的粗排阶段,粗排阶段的目标是从约上万级别的候选中筛选出合规、相关且成交效率高的topN商品,这里N通常是上千量级。而在粗排架构下,排序分可以简化为以下表达:
其中 为业务规则分,如运营圈品提权、低信誉商家降权等规则; 为相关性分,如类目匹配分、关键词匹配分等; 为成交效率相关的排序分,如静态商品/卖家分、CTR、CVR等; 为各项权重。
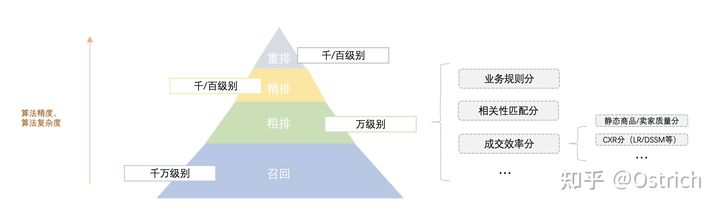
以上规则分、相关性分往往可以看作是搜索排序的约束项,真正选出高成交效率的商品则主要依赖排序模型 ,该部分也是本节讨论的重点。由于候选量级较大,相对精排排序模型,这部分策略常无法回避的两个问题:1、模型需要兼顾计算性能和效果;2、打分样本空间分布与精排不一致(精排对粗排返回的样本做排序,粗排则要对召回的样本打分)。
粗排模型
对于模型而言,出于计算性能考虑,粗排模型的选择有限,最简单经典的有商品静态分、线性回归LR、DSSM双塔模型,另有很多典型的进阶优化模型,以下将分别介绍。
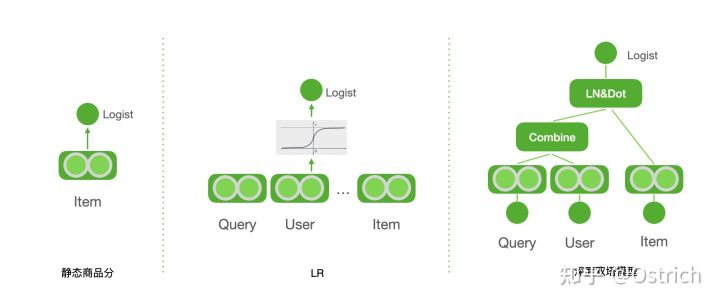
静态排序分
静态分是最简单的效率排序分,如1)静态商品质量分(标题质量、图片质量、价格分等),通常基于内容理解、历史统计信息等得到;2)商品/卖家效率分,仅考虑商品和卖家等维度特征的CTR/CVR预估分,可以使用如LR、DNN等模型预估,亦可以直接统计候选历史CXR表现;3)其他商品粒度分,如新品、需扶持商品分等等。静态分的算分表达式可表示为:
静态排序分通常可以离线计算,极大节省线上预测开销,但却伴随着时效性差、预估分不够精准的问题,尤其对非标品/孤品排序场景十分不友好。
LR
逻辑回归模型天然具有预测效率高的优势,因此
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 671
671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









