










一文看懂推荐系统:排序06:粗排三塔模型,性能介于双塔模型和精排模型之间
提示:最近系统性地学习推荐系统的课程。我们以小红书的场景为例,讲工业界的推荐系统。
我只讲工业界实际有用的技术。说实话,工业界的技术远远领先学术界,在公开渠道看到的书、论文跟工业界的实践有很大的gap,
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
王树森娓娓道来**《小红书的推荐系统》**
GitHub资料连接:http://wangshusen.github.io/
B站视频合集:https://space.bilibili.com/1369507485/channel/seriesdetail?sid=2249610
基础知识:
【1】一文看懂推荐系统:概要01:推荐系统的基本概念
【2】一文看懂推荐系统:概要02:推荐系统的链路,从召回粗排,到精排,到重排,最终推荐展示给用户
【3】一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration Filter的核心思想与推荐过程
【4】一文看懂推荐系统:召回02:Swing 模型,和itemCF很相似,区别在于计算相似度的方法不一样
【5】一文看懂推荐系统:召回03:基于用户的协同过滤(UserCF),要计算用户之间的相似度
【6】一文看懂推荐系统:召回04:离散特征处理,one-hot编码和embedding特征嵌入
【7】一文看懂推荐系统:召回05:矩阵补充、最近邻查找,工业界基本不用了,但是有助于理解双塔模型
【8】一文看懂推荐系统:召回06:双塔模型——模型结构、训练方法,召回模型是后期融合特征,排序模型是前期融合特征
【9】一文看懂推荐系统:召回07:双塔模型——正负样本的选择,召回的目的是区分感兴趣和不感兴趣的,精排是区分感兴趣和非常感兴趣的
【10】一文看懂推荐系统:召回08:双塔模型——线上服务需要离线存物品向量、模型更新分为全量更新和增量更新
【11】一文看懂推荐系统:召回09:地理位置召回、作者召回、缓存召回
【12】一文看懂推荐系统:排序01:多目标模型
【13】一文看懂推荐系统:排序02:Multi-gate Mixture-of-Experts (MMoE)
【14】一文看懂推荐系统:排序03:预估分数融合
【15】一文看懂推荐系统:排序04:视频播放建模
【16】一文看懂推荐系统:排序05:排序模型的特征
提示:文章目录
粗排vs精排
之前介绍了多目标排序模型,没有具体区分粗排和精排。
其实前面介绍的模型主要是用于精排。
这节我们来看看粗排该怎么做。
首先对比一下粗排和精排,
在推荐系统的链路上,粗排在精排之前,粗排给几千篇笔记打分,而精排只给几百篇笔记打分,
每做一次推荐,粗排模型要给几千篇笔记打分,单次推理的代价必须很小,
而精排只给几百篇笔记打分,单次推理的代价很大也没有关系。

精排的模型规模可以很大,模型结构可以很复杂,
粗排预估的准确性不高,牺牲准确性是为了保证线上推理的速度足够快,准确性差一些没有关系。
粗排的目的是做初步筛选,从几千篇笔记中选出几百篇,而不是真正决定把哪些笔记曝光给用户。
精排的模型足够大,牺牲更多的计算确保预估的准确性足够高。
在讲粗排之前,我们先来回顾一下精排模型和双塔模型。
这是之前介绍的精排模型,
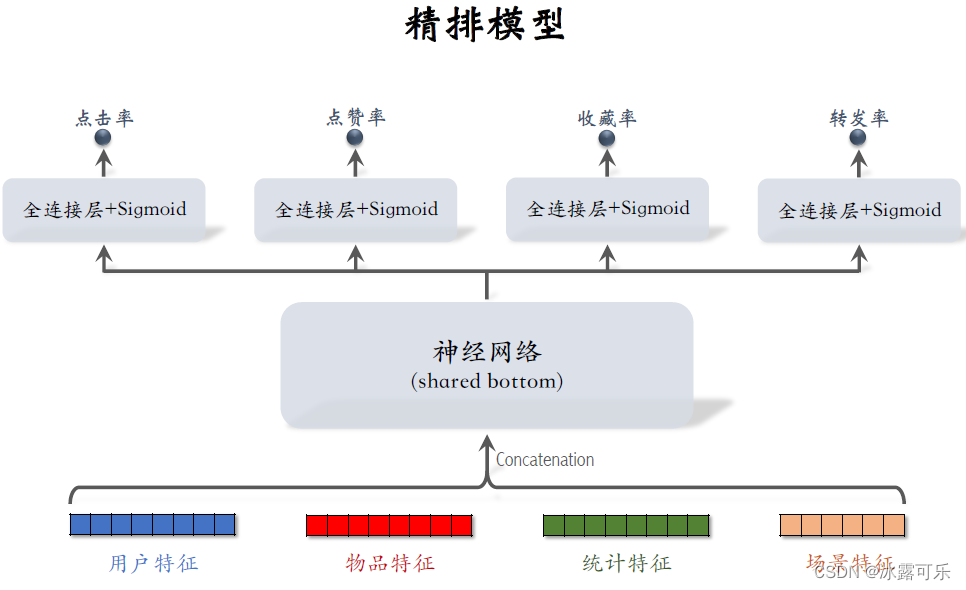
最下面是精排模型用到的特征,包括用户特征、物品特征、统计特征,还有场景特征,
直接对这些特征做concat,然后输入一个神经网络,这个神经网络叫做shared bottom,意思是它被多个任务共享,
把它输出的向量输入上面多个头,得到对点击率、点赞率等指标的预估
精排模型的代价主要是在shared bottom,这是因为它很大神经网络,结构也很复杂。

这样的精排模型属于前期融合,前期融合的意思是先对所有特征做congratulation,然后再输入神经网络,
这样的模型线上推理代价大。
如果给N篇笔记打分,那么整个大模型要做N次推理。
之前召回的课程中还介绍了双塔模型,
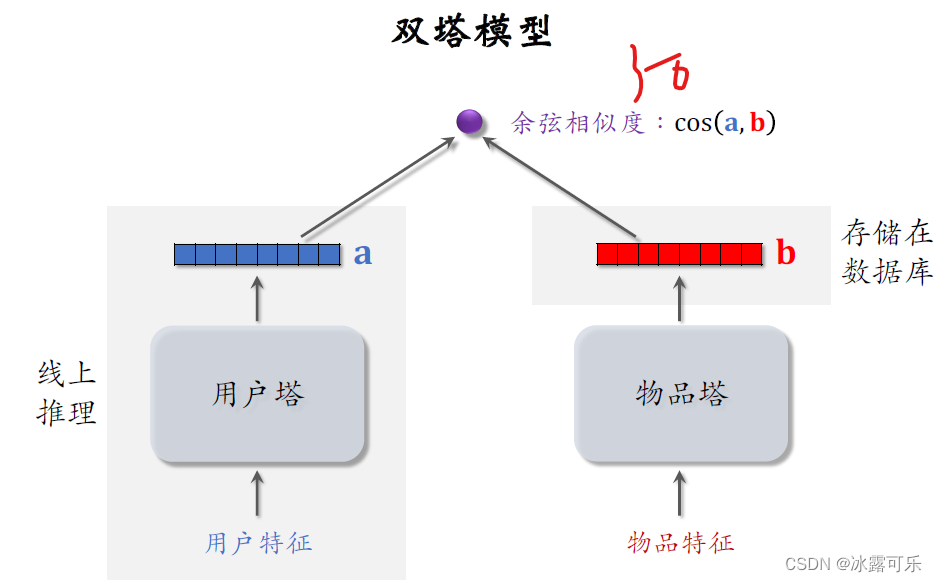
左边是用户塔,右边是物品塔。两个塔各输出一个向量,两个向量的余弦相似度,表示用户是否对物品感兴趣。
在训练好模型之后,把物品向量B存储在向量数据库在线上,不需要用物品塔做计算。
线上推理只需要用到用户塔,每做一次推荐,用户塔只做一次推理,计算出一个向量a,
所以双塔模型的计算代价很小,适合做召回
双塔模型是典型的后期融合,把用户和物品特征分别输入不同的神经网络,
不对用户和物品的特征做融合,
直到最后才计算向量a和B的相似度。

后期融合的好处是线上计算量小,
用户他只需要做一次线上推理计算用户表征a,而物品表征B事先存储在向量数据库中,物品塔在线上不需要做推理,
但是后期融合模型不如前期融合模型准确,
因此后期融合模型用于召回,而前期融合的模型可以作为精排。
粗排的三塔模型

我们小红书的粗排是三塔模型**,效果介于双塔和精排之间。**
我们的三塔模型主要借鉴了阿里妈妈2020年的论文,但是在细节上有很大区别,
细节上的优化有很大收益,但我不方便对外讲模型的细节,
这节只讲三塔模型的主要原理,不讲模型的细节。
三塔模型,顾名思义有三个塔,
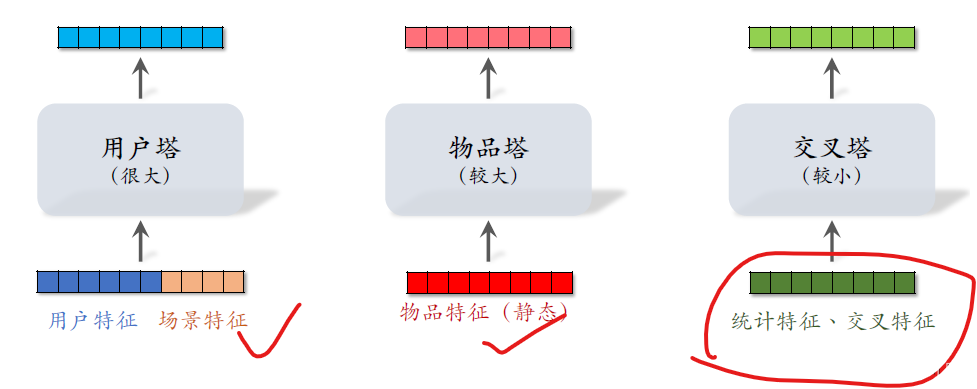
分别是用户塔、物品塔、交叉塔。
用户塔的输入是用户特征和场景特征。
物品塔的输入只有物品特征
交叉塔的输入包括统计特征和交叉特征,交叉特征是指用户特征与物品特征做交叉。
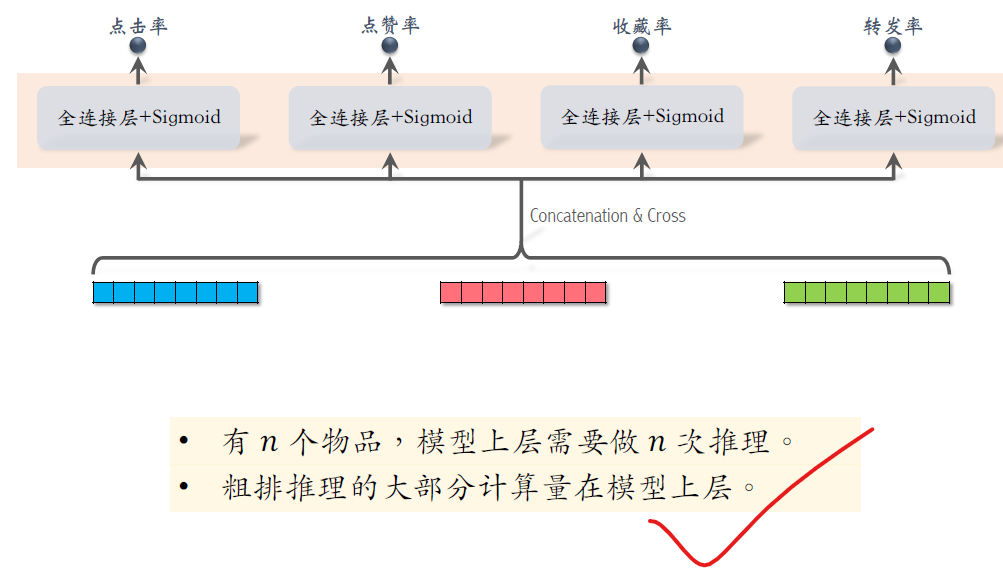
三个塔分别输出三个向量,这三个向量做concat后交叉,得到一个向量,
把这个向量送入多个头,他们输出点击率、点赞率等指标的预估。
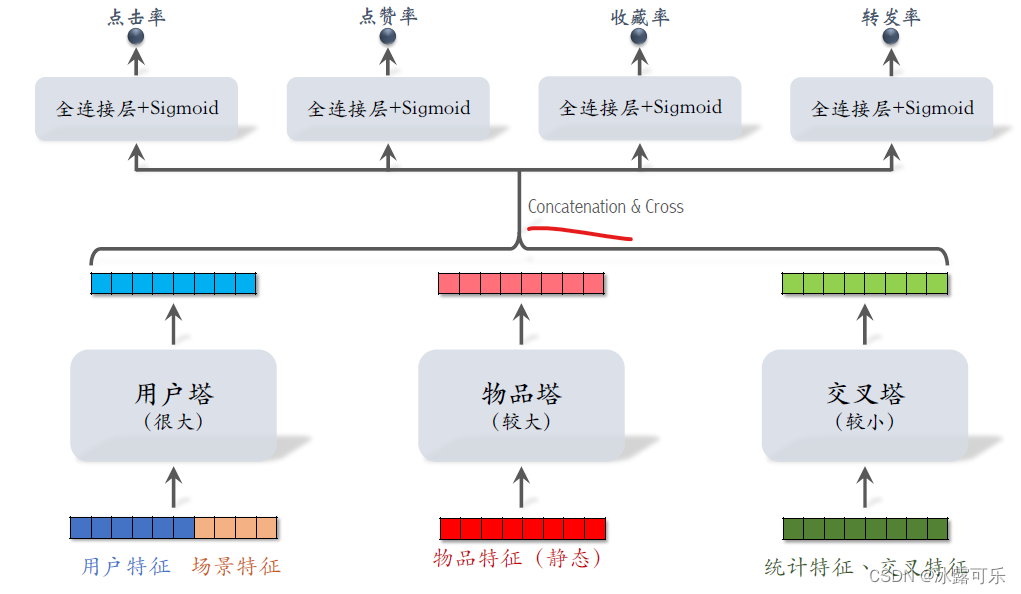
训练复盘模型的方法就是正常的端道端训练,跟精排完全一样。
这个模型看起来跟精排的区别不大,最主要的区别是下面的三个塔,
这个模型介于前期融合与后期融合之间,
前期融合就是把这些底层特征做concat。
而这里是把三个塔输出的向量做concat,
接下来我要解释为什么要这样设计模型??
我们来看下面的三个塔,用户塔可以很大很复杂,
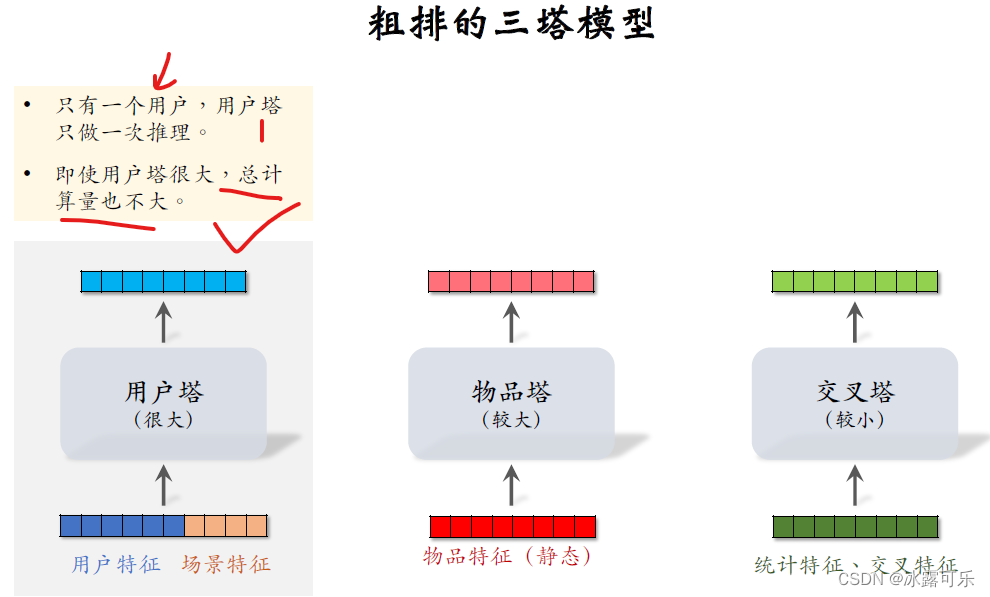
线上每次给一个用户做推荐,用户塔只需要做一次推理,
即使用户塔很大,推理很慢也没有关系,用户塔对粗排总的计算量影响很小。
再来看一下物品塔,每给用户做一次推荐出牌,需要给N个物品打分,N的大小是几千
理论上来说,物品塔需要做N次推理,给所有N个候选物品打分,
但好在物品的属性相对比较稳定,短期之内不会发生变化。
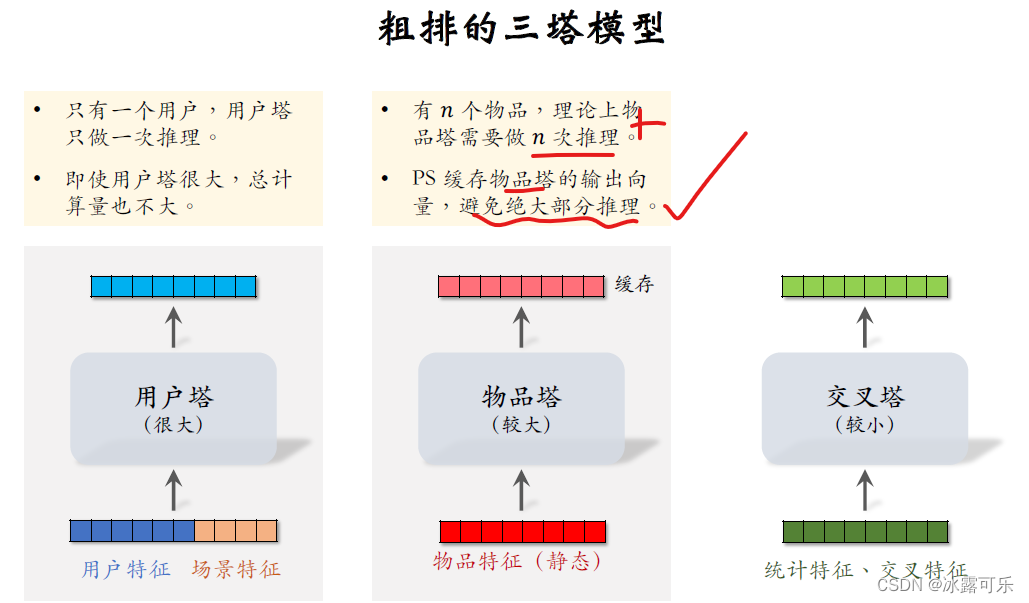
可以把物品塔输出向量缓存在server中,每隔一段时间刷新一次。
由于做了缓存,物品塔在线上几乎不用做推理,
只有遇到新物品的时候,物品塔才需要做推理,
粗排给几千物品打分,物品塔实际上只需要做几十次推理,计算量还好,所以物品塔的规模可以比较大。
最后研究交叉塔,它的输入是用户和物品的统计特征,还有用户和物品特征的交叉。
上节说过,统计特征会实时动态变化,每当一个用户发生点击等行为,它的统计特征就会发生变化,
每当一个物品获得曝光和交互,它的点击次数、点击率等指标就会发生变化。

由于交叉塔的输入会实时发生变化,我们不应该缓存交叉塔输出的向量
交叉塔在线上的推理避免不掉,粗排给N个物品打分,有N个物品的统计特征和交叉特征。
交叉塔要实实在在做N次推理,所以交叉塔必须足够小,计算够快。
通常来说交叉塔只有一层,宽度也比较小,
刚才我们讨论了粗排模型,底层的三个塔,
三个塔各输出一个向量,三个向量融合起来,作为上层多个头的输入,
最后我们来研究模型的上层结构,
粗排给N度平打分,模型上层需要做N次推理,无法用缓存的方式,避免不了N次计算

粗排推理的大部分计算量在模型上层。
模型上怎么做N次推理代价都会大
最后总结一下三塔模型的线上推理。
第一步是从多个数据源去特征,给一个用户做推荐
需要举它的用户画像和统计特征,每次有N个候选物品,需要取N个物品画像和N个物品的统计特征。

无论有多少个候选物品用户,他只需要做一次推理,物品塔输出的向量事先缓存在print server上。
只有当没有命中缓存时,才需要物品塔做推理。
最坏的情况下,物品塔需要做N次推理,
但实际上缓存的命中率非常高,99%的物品都会命中缓存,不需要做推理。
给几千个候选物品做初排物品塔,只需要做几十次推理。
交叉塔的输入都是动态特征,不能做缓存,必须做N次推理。
三个它各输出一个向量,把这三个向量融合起来,作为上层网络的输入。
上层网络必须做N次推理,给N度平打分,没有办法通过缓存减少推理次数,
粗排大部分的计算量都在上层网络。
这节介绍了粗排的三叉模型,它介于双塔模型和精排牌模型之间。
粗排模型的设计理念就是尽量减小推理的计算量,使得模型可以在线上给几千篇笔记打分。
总结
提示:如何系统地学习推荐系统,本系列文章可以帮到你
(1)找工作投简历的话,你要将招聘单位的岗位需求和你的研究方向和工作内容对应起来,这样才能契合公司招聘需求,否则它直接把简历给你挂了
(2)你到底是要进公司做推荐系统方向?还是纯cv方向?还是NLP方向?还是语音方向?还是深度学习机器学习技术中台?还是硬件?还是前端开发?后端开发?测试开发?产品?人力?行政?这些你不可能啥都会,你需要找准一个方向,自己有积累,才能去投递,否则面试官跟你聊什么呢?
(3)今日推荐系统学习经验:这节介绍了粗排的三叉模型,它介于双塔模型和精排牌模型之间。


















 1548
1548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











