







MP算法
MP算法是一种贪心算法(greedy),每次迭代选取与当前样本残差最接近的原子,直至残差满足一定条件。
求解方法
首先解决两个问题,怎么定义“最接近原子”,怎么计算残差?
选择最接近残差的原子:MP里定义用向量内积原子与残差的距离,我们用R表示残差,di表示原子,则:
Max[Dist(R,di)]=max[<R,di>];
残差更新:R=R-<R,di>I;继续选择下一个,直至收敛;
需要注意的是,MP算法中要求字典原子||di||=1,上面的公式才成立。
我们用二维空间上的向量来表示,用如下的图来表述上面的过程:
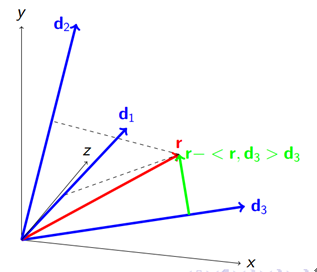
上图中d1,d2,d3表示归一化的原子,红色向量r表示当前残差;
进过内积计算,<r,d3>最大,于是r分解为d3方向以及垂直于d3方向的两个向量(<r,d3>d3及r-<r,d3>d3),把d3方向的分量(<r,d3>d3)加入到已经求得的重构项中,那么绿色向量(r-<r,d3>d3)变为新的残差。
再一轮迭代得到如下:
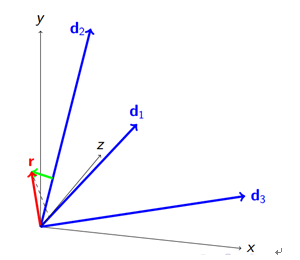
R往d1方向投影分解,绿色向量成为新的残差。
具体算法:

收敛性
从上面的向量图我们可以清楚地看出,k+1的残差Rk+1是k步残差Rk的分量。根据直角三角形斜边大于直角边,|Rk+1|<=|Rk|,则算法收敛。
注意事项:
1.上面也讲过,字典的原子是归一化的,也就是||di||=1,因为我们选取max<R,di>时,如果di长度不统一,不能得出最好的投影。
2.如果我们的字典只有两个向量d1,d2,那么MP算法会在这两个向量间交叉迭代投影,也就是f=a1d1+a2d2+a3d1+a4d2+…..;也就是之前投影过的原子方向,之后还有可能投影。换句话说,MP的方向选择不是最优的,是次优的。
如下图:

这也是其改进版本OMP要改进的地方。
下面采用MP算法进行信号重构,也可以进一步用于图像重构
%基于MP算法
clc;
clear;
%观测向量y的长度M=80,即采样率M/N=0.3
N=256;
K=15; %信号稀疏度为15
M=80; %观测向量y的长度
x = zeros(N,1);
q = randperm(N);
x(q(1:K)) =randn(K,1); %原始信号
%构造高斯测量矩阵,用以随机采样
Phi = randn(M,N)*sqrt(1/M);
for i = 1:N
Phi(:,i) = Phi(:,i)/norm(Phi(:,i));
end
y=Phi*x ; %获得线性测量
%用MP算法开始迭代重构
m=2*K; %总的迭代次数
r_n=y; % 残差值初始值
x_find=zeros(N,1); %x_find为MP算法恢复的信号
for times=1:m
for col=1:N
neiji(col)=Phi(:,col)'*r_n; %计算当前残差和感知矩阵每一列的内积
end
[val,pos]=max(abs(neiji)); %找出内积中绝对值最大的元素和它的对应的感知矩阵的列pos
x_find(pos)=x_find(pos)+neiji(pos); %计算新的近似x_find
r_n=r_n-neiji(pos)*Phi(:,pos); %更新残差
end
subplot(3,1,1);plot(x);title('target');
subplot(3,1,2);plot(x_find);title('reconstruct');
subplot(3,1,3);plot(r_n);title('残差');














 9387
9387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









