







一. 软件安装
官网下载地址: https://redis.io/download
Redis版本: 5.0.8
系统: mac os
1.1 编译和安装
- 如果是Linux系统,需要预先安装GCC编译器
yum install -y gcc-c++
- 解压
tar -zxvf redis-5.0.8.tar.gz
- 新建redis安装目录
mkdir /app/redis-5.0.8/redis-install
- 切换至redis解压根目录:
cd /app/redis-5.0.8
- 编译与安装Redis至指定目录(PREFIX参数用于指定安装目录的路径,如果不指定目录,则默认安装在/usr/local目录)
make && make install PREFIX=/app/redis-5.0.8/redis-install
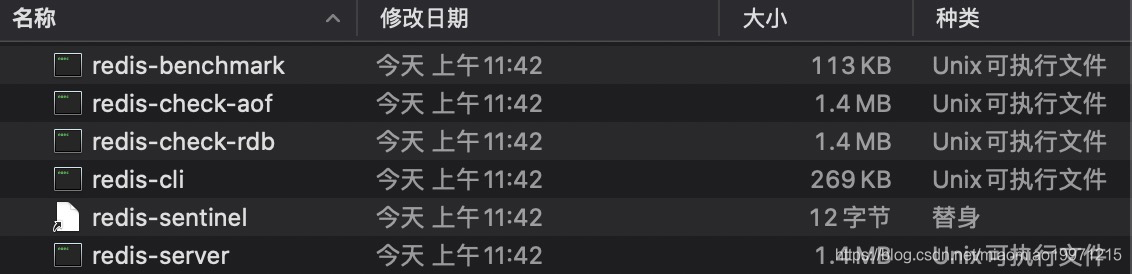
执行完毕后会在指定目录下自动生成bin目录,内含6份文件:
可能出现的异常:
- 执行make命令时报错: zmalloc.h:50:31: fatal error: jemalloc/jemalloc.h: No such file or directory
原因是jemalloc重载了Linux下的ANSI C的malloc和free函数。解决办法:make时添加参数。
make MALLOC=libc
1.2 redis.conf简单配置
- 新建自定义配置文件
我们可以将Redis解压后得到的目录中现有的redis.conf复制一份放到redis-install目录
cp /app/redis-5.0.8/redis.conf /app/redis-5.0.8/redis-install/redis.conf
- redis.conf的简单配置
# 是否为精灵进程,默认非精灵进程启动。修改成yes即可。
# 精灵启动就是通过后台守护进程的方式启动
daemonize yes
# 端口号 默认为6379,可以自行配置
port 6379
# redis中的schema数量。schema可以看成数据库。
# schema只有编号,从0开始,到数据库数量-1为止 默认提供16个库
database 16
# 持久化规则 Redis的默认持久化规则是RDB 将数据集的内存快照dump(转存)到dump.rdb文件中。
# 我们可以通过添加配置来修改Redis服务器转存内存快照的频率,如下:
# 在900秒(15分钟)之内,如果至少有一个key发生变化,则dump(转存)内存快照
save 900 1
# 在300秒(5分钟)之内,如果至少有10个key发生变化,则dump(转存)内存快照
save 300 10
# 在60秒(1分钟)之内,如果至少有10000个key发生变化,则dump(转存)内存快照
save 60 10000
# RDB持久化文件的名称
dbfilename dump.rdb
# 存放数据的路径 默认dir ./
dir ./
# 是否启用append of file持久化方式 默认关闭
# append of file: 以追加的方式,持久化数据到文件(否则使用覆盖的方式)
appendonly no
# aof持久化方式的文件名称
appendfilename “appendonly.aof”
1.3 启动
- 启动Redis (指定配置文件)
/app/redis-5.0.8/redis-install/redis-server …/redis.conf
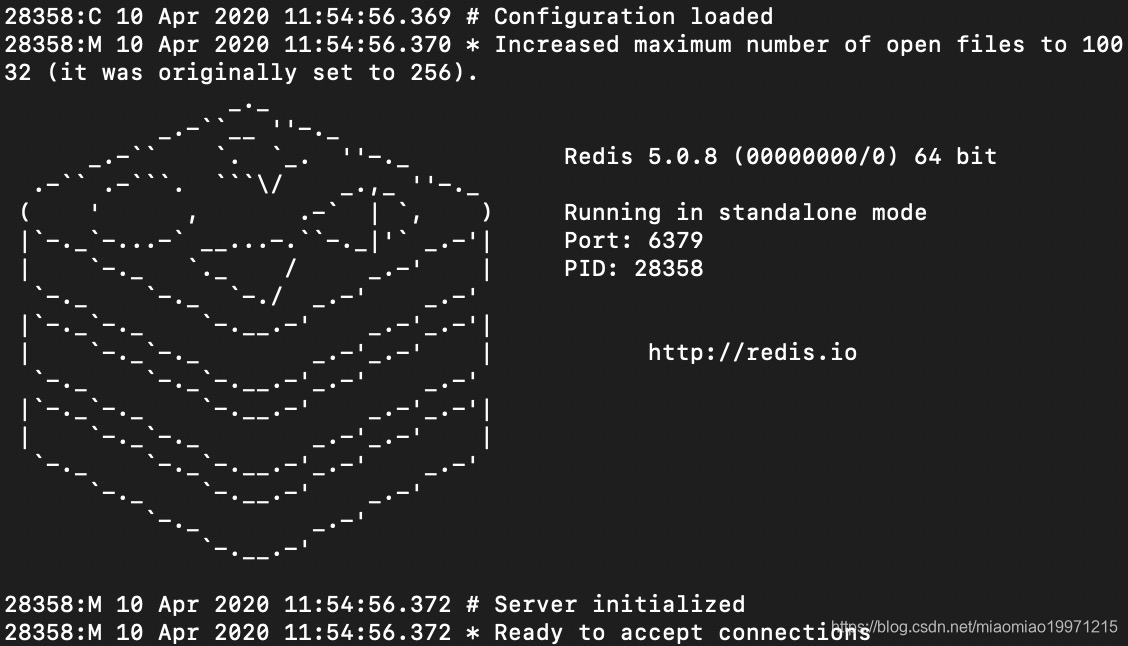
执行完毕后,控制台会输出以下内容:
1.4 客户端连接
客户端连接Redis服务端时,需要使用redis-cli,此程序在安装后自动生成于bin目录之下。
执行命令如下:
redis-cli [-h ip -p port]
-h与-p参数可选填,默认连接localhost 6379端口的Redis应用。
二. 数据类型
Redis中的数据都是以键值对(key-value)的形式存储,其中key只能填写字符串类型,所以讨论Redis的数据类型,实际上就是在讨论value能存储的数据类型。
Redis总共支持5种数据类型,分别是: string(字符串)、hash(哈希)、list(链表)、set(集合)以及zSet(sorted set: 有序集合)。
2.1 字符串
谈到Redis中的字符串,就不得不先引入SDS的概念。SDS又叫简单动态字符串,是Redis构建的用来表示字符串的一种数据结构,它在Redis底层中实际上保存的是byte数组。
由于Redis为SDS提供的API都是二进制安全的(在传输数据时,保证二进制数据不被篡改、破译,就算被攻击,也能够及时检测出来。由于二进制数据实际上存放在byte数组中,程序不会对数据做任何的限制、过滤,也即数据在写入的时候是什么样子的,那么在读取的时候就会是什么样子。有些特殊的数据类型会以某些特殊字符做分隔或者终止符号,比如\0),因此字符串类型的value中可以存储任何种类的数据,比如jpg图片、音频、视频、压缩文件或者序列化后的对象。
此外,Redis中一个key-value中,字符串类型的value部分最多保存512MB的数据。
数据结构: Map<String, String>
字符串数据类型所涉及到的操作就是最简单的set和get,做简单的key/value缓存。
set board JD
get board JD
输出: “JD”
2.2 哈希
value部分相当于Map,可以再次保存若干键值对,没有数据容量的限制。
数据结构: Map<String, Map<String, String>>
hash一般用于存储结构化的数据,比如一个对象(前提是这个对象没有嵌套别的对象)给缓存在redis里,然后在每次读写缓存时,就可以操作缓存里的某个hash字段。
hset person name zhangsan
hset person age 26
hset person id 1
hget person
2.3 链表
value部分相当于List,有存储顺序,底层使用链表实现。相当于一个key对应多个数据,数据可以重复。
数据结构: Map<String, List<String>>
rpush: 从右向左添加元素
lpush: 从左向右添加元素
rpop: 从右向左弹出元素
lpop: 从左向右弹出元素
rpush mylist 1 2
rpush mylist 3
lpush mylist 4 5
lpush mylist 6
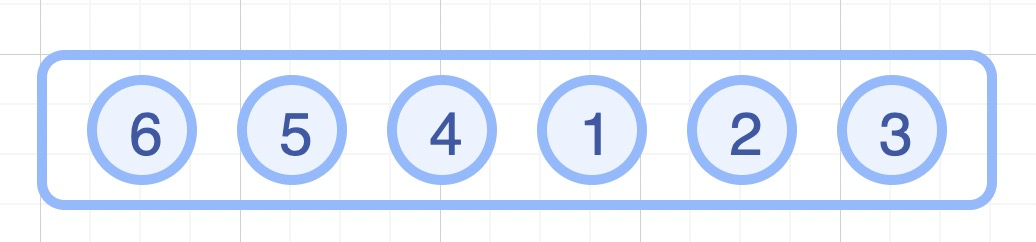
rpop mylist
输出: 3
lpop mylist
输出: 6
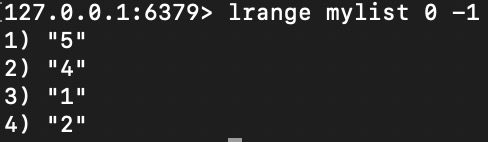
lrange mylist 0 -1
输出:
正是因为拥有list这种有序的数据结构,所以有些时候,我们可以利用Redis做一个简单的消息队列。
2.4 集合
有些时候,我们为了对一批数据进行快速的去重,会使用基于jvm的hashSet,但如果你的某个系统部署在多台服务器上呢?此时就得使用Redis提供的set了。
value部分相当于Set,底层使用Hash算法保证数据的唯一性。相当于一个key对应多个数据,数据不能重复,且无序。基于set,我们可以做各种各样的操作,比如取两个集合的交集、并集、差集等等。比如查微博,查看两个人好友列表中相同的好友有哪些人,这就是在求交集。
数据结构: Map<String, Set<String>>
比如我们把两个大 V 的粉丝都放在两个 set 中,对两个 set 做交集。
#-------操作一个set-------
# 添加元素
sadd mySet 1
# 查看全部元素
smembers mySet
# 判断是否包含某个值
sismember mySet 3
# 删除某个/些元素
srem mySet 1
srem mySet 2 4
# 查看元素个数
scard mySet
# 随机删除一个元素
spop  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 834
834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









