







大数据平台 CDP 中如何配置 hive 作业的 YARN 队列以确保SLA?
大家知道,在生产环境的大数据集群中,在向资源管理器YARN提交作业时,我们一般会将作业提交到管理员指定的队列去执行,以利用 YARN 队列的资源隔离性确保作业能够获得足够的资源进行执行,从而确保SLA。
1 CDH 中如何指定 HIVE 作业执行时的 YARN 队列?
在以往的的大数据平台 CDH中:
- YARN 默认使用的资源调度器是公平调度器
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler; - HIVE 作业一般也是使用 hive on mr或hive on spark 执行引擎;
- 处于安全考量,一般推荐HIVE使用kerberos认证和sentry授权,此时要求关闭hive 代理功能,即hive.server2.enable.doAs=false;
此时为确保不同业务用户的 HIVE 作业提交到不同的 YARN 队列中,一般有两种选择:
- 在提交作业前手动指定队列,一般是通过 set mapreduce.job.queuename/mapred.job.queue.name/mapred.job.queuename = xxx 手工指定;(mapreduce.job.queuename is the new parameter name; mapred.job.queuename is changed to mapred.job.queue.name in hive-3.0.0 by HIVE-17584, and picked up by cdh in 2.1.1-cdh6.3.2)
- 在 CDH 服务端"动态资源池配置"中配置"放置规则",指定使用基于用户名匹配到的指定队列(一般是 root.users.[username]);
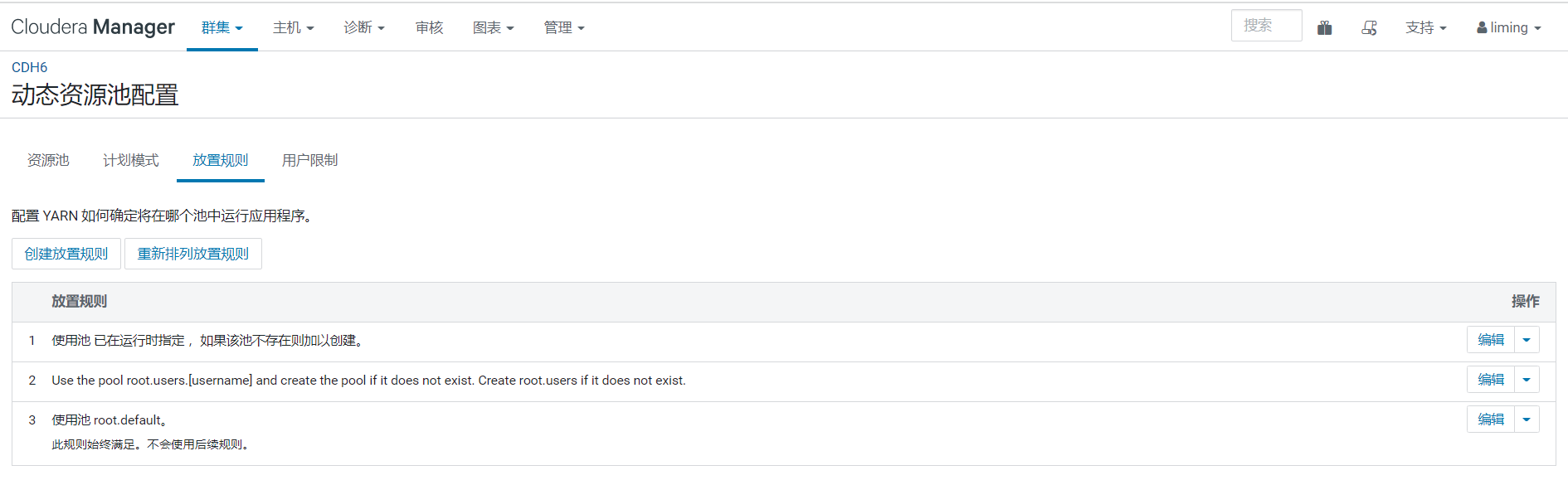
比如某业务用户dap提交的 hive 作业,在没有手动指定队列时,其使用的队列是 root.users.dap,达到了资源隔离的目的:(此时 HIVE 使用 kerberos 认证和 sentry 授权,关闭了 hive 代理功能,即 hive.server2.enable.doAs=false):
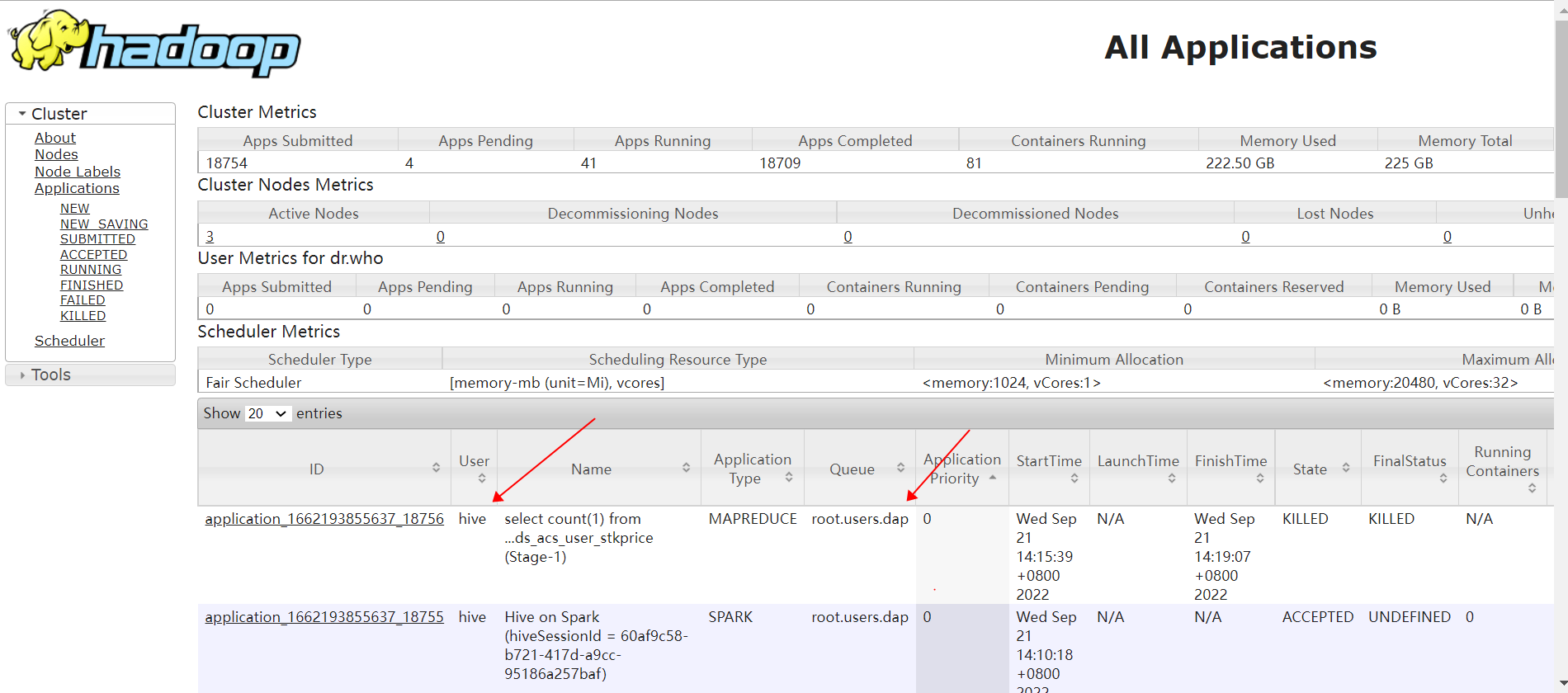
2 CDP 中默认配置下 HIVE 作业执行时的 YARN 队列?
在大数据平台 CDP 中:
- YARN 默认使用的资源调度器是容量调度器
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler; - HIVE 作业使用 hive on tez 执行引擎,不再支持 hive on mr/spark;
- 处于安全考量,一般推荐HIVE使用kerberos认证和ranger授权(cdp不再支持sentry),并要求关闭hive 代理功能,即hive.server2.enable.doAs=false;
此时在没有手动指定队列时,所有 HIVE 作业执行时的 YARN 队列,是 default 或 root.users.hive,并不能达到资源隔离的目的:
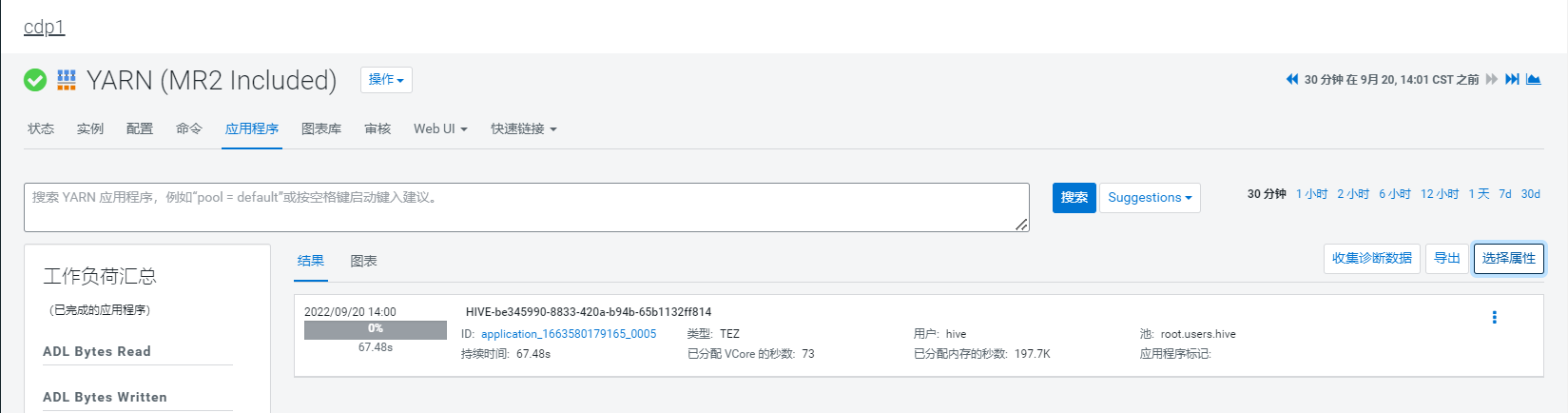
此时有以下几点需要注意:
- 当没有配置放置规则时,hive作业使用的是default 队列;
- 当如下配置放置规则时,hive作业使用的是root.users.hive;
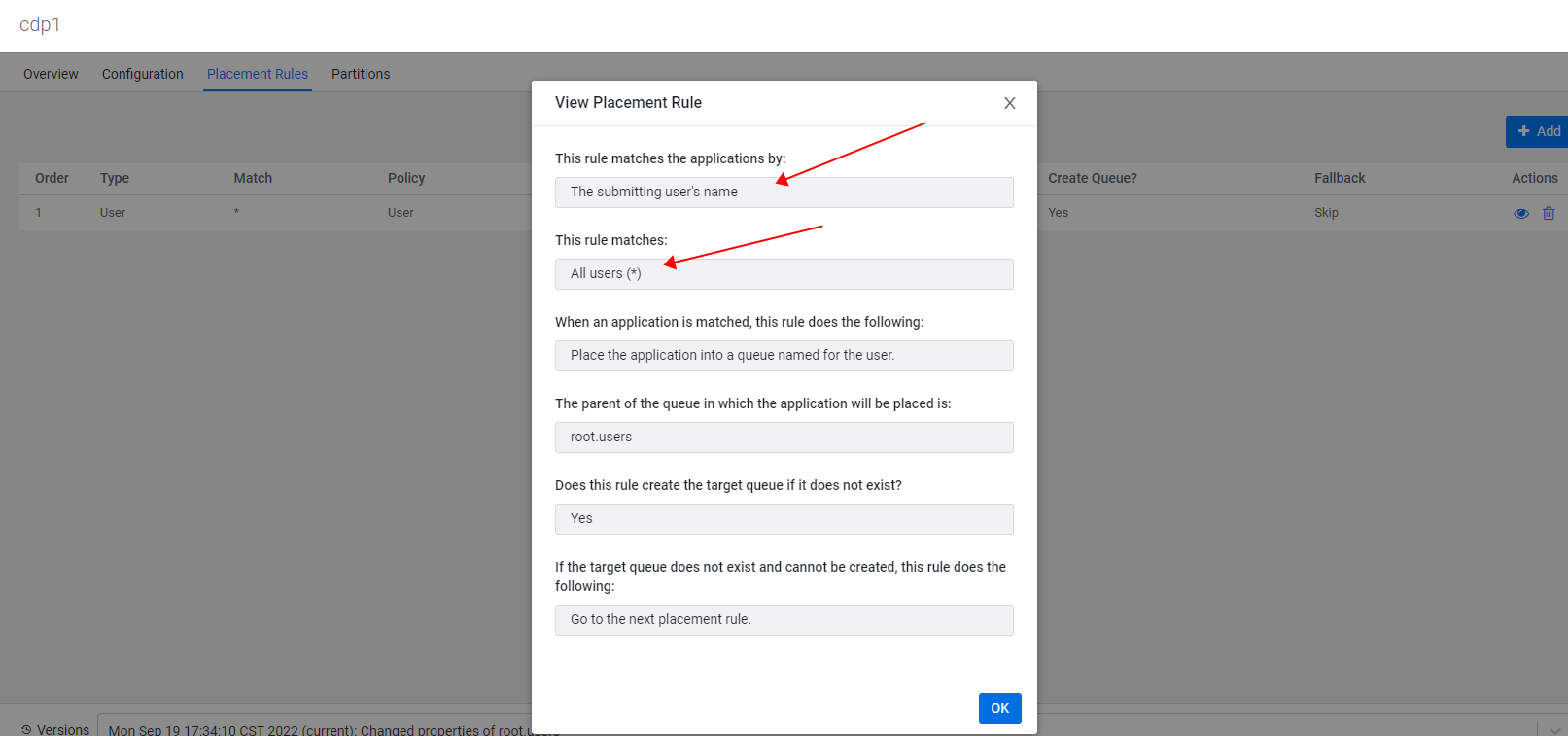
- 此时CDP中一些相关的参数的默认值如下:
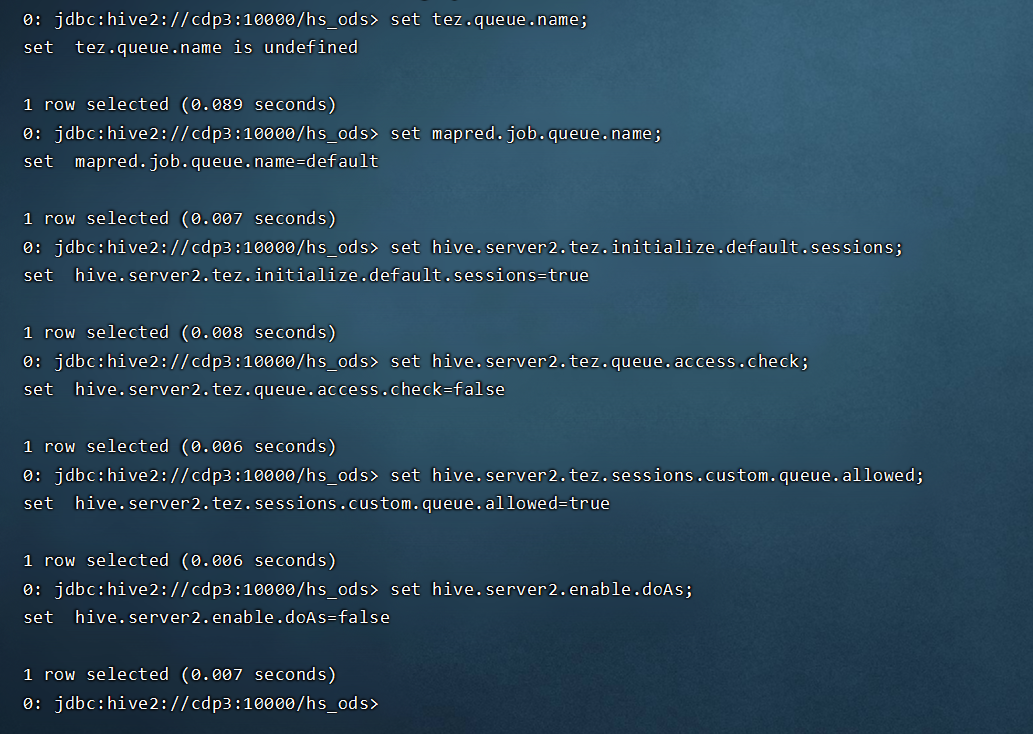
那么如何达到不同业务用户的 HIVE 作业提交到不同的 YARN 队列,以达到资源隔离的目的呢?请继续看。
3 CDP 中如何手动指定 HIVE 作业执行时的 YARN 队列?
CDP中要达到不同业务用户的 HIVE 作业提交到不同的 YARN 队列,以达到资源隔离的目的,一种方法是手动指定YARN 队列。
由于CDP使用的是容量调度器而不是公平调度器,且只支持HIVE ON TEZ 而不是 hive on mr/spark,所以指定方式略有不同:
- 手动指定队列名时,由于hive on tez 背后有 tez session pool 和 tez default sessions 的概念,其指定方式略有不同,推荐使用参数 tez.queue.name 而不是 mapreduce.job.queuename/mapred.job.queue.name 指定队列名;
- 可以登录时指定队列名:比如 beeline -u “jdbc:hive2://cdp3:10000/hs_ods;principal=hive/_HOST@HUNDSUN.COM;” --hiveconf tez.queue.name=root.dap2 或者 beeline -u “jdbc:hive2://cdp3:10000/hs_ods;principal=hive/_HOST@HUNDSUN.COM?tez.queue.name=root.dap2”;
- 可以登录后提交SQL前指定队列名,比如 set tez.queue.name=root.users.dap;
- 为确保客户端手动指定的YARN 队列不会被覆盖,需要确保 CDP 服务端容量调度器的参数 yarn.scheduler.capacity.queue-mappings-override.enable 为 false,该参数默认值即为 false;

不过很多管理员倾向于将参数 yarn.scheduler.capacity.queue-mappings-override.enable 改为 true,以禁止用户在客户端随意指定队列,所以此时用户通过 set tez.queue.name=root.users.dap 手动指定的队列,会被服务端的队列放置规则等配置覆盖:
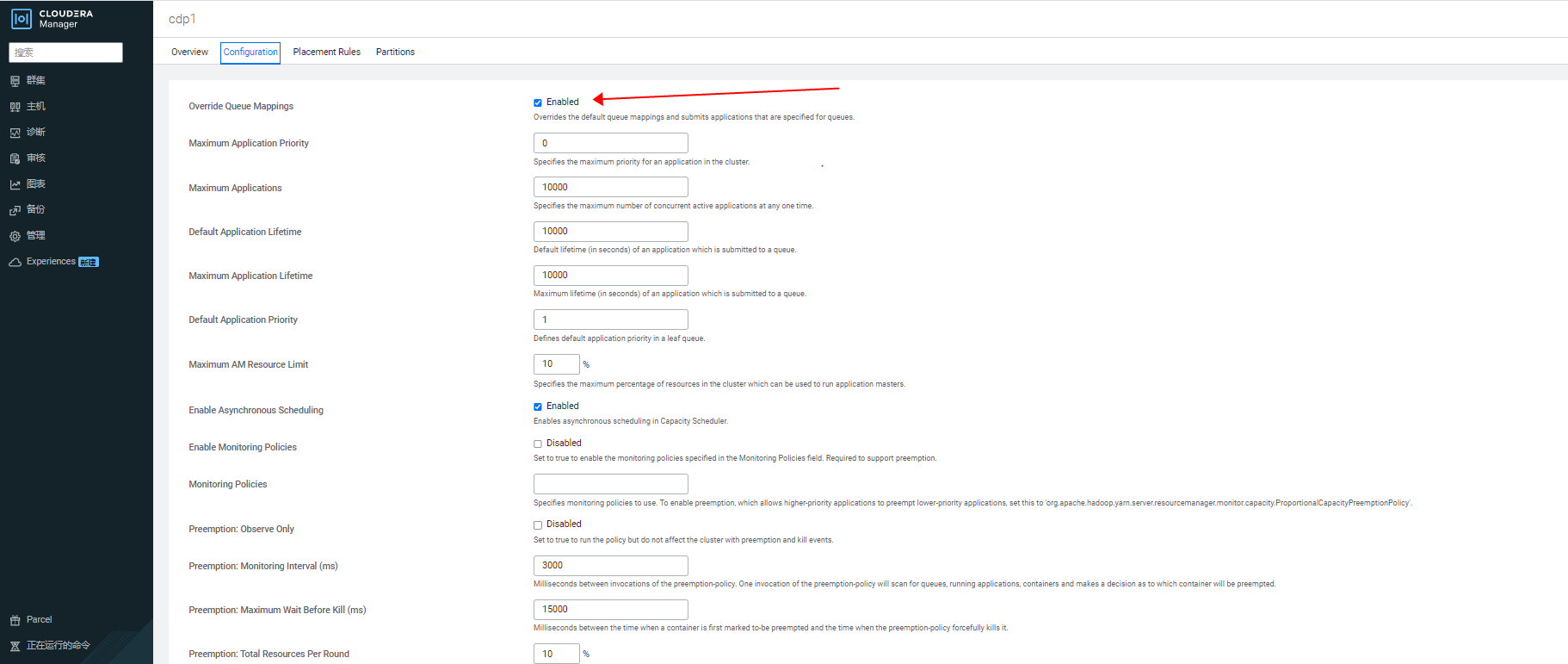
#用户在客户端指定的yarn 队列,会被服务端的放置规则覆盖,YARN RM 相关日志:
2022-09-21 09:39:01,306 INFO org.apache.hadoop.yarn.server.resourcemanager.RMAppManager: Placed application with ID application_1663663279733_0012 in queue: dap, original submission queue was: root.dap2
#用户在客户端指定的yarn 队列,会被服务端的放置规则覆盖,yarn 相关源码
org.apache.hadoop.yarn.server.resourcemanager.RMAppManager#copyPlacementQueueToSubmissionContext:
private void copyPlacementQueueToSubmissionContext(
ApplicationPlacementContext placementContext,
ApplicationSubmissionContext context) {
// Set the queue from the placement in the ApplicationSubmissionContext
// Placement rule are only considered for new applications
if (placementContext != null && !StringUtils.equalsIgnoreCase(
context.getQueue(), placementContext.getQueue())) {
LOG.info("Placed application with ID " + context.getApplicationId() +
" in queue: " + placementContext.getQueue() +
", original submission queue was: " 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1025
1025











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











