







前言
在计算机的世界中,数据计算和处理都是准确无误的,这在大多数人看来是理所当然的,确实也应该是这样的。但是在某些场景下完全的准确无误意味着很高的代价,不管是时间上还是空间上。
于是大家都在考虑,能不能有一些方法能在很小的错误率的前提下,能大幅度提高效率减少资源消耗,而对于小概率误判的场景,能通过容错机制将窟窿补上。显然有,在这种背景下,咱们本文的主角,一个“不靠谱”的二愣子Bloom Filter(布隆过滤器)登场了。
和偶像剧剧情不同,二愣子没有因为自身的“缺点”而两集就“领盒饭”了,反而通过自己的机智和勇敢,直接C位出道,获取众多美女的芳心,这妥妥的韦爵爷在世啊,下面我们就来说说大数据处理中的韦小宝是如何超神的。

今天的图片就不介绍了,想必大家也很了解了,鹿鼎记是金庸老先生的封笔之作,韦小宝也是金庸老先生最喜欢的角色。而我认为陈小春版的韦小宝是原著还原度最高的存在。他优缺点都很明显,不按套路出牌,经常另辟蹊径,有很多创造性思维,扬长避短,无限发挥自己的优势,正如今天我们文章的主角——布隆过滤器。
正文
What布隆过滤器?
先来说说今天主角的诞生记:
Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。基于一种概率数据结构来实现,是一个有趣且强大的算法
How布隆过滤器?
以人名来命名的算法一般都很牛,这个也不例外。他利用了位图的部分实现(如果不了解位图,可以参考下上一篇文章面试以及大数据处理中的常客BitMap到底是个什么样子的存在?),扬长避短,既发扬了位图的优势,又规避了位图的劣势,站在巨人的肩膀上,成就了自身的荣耀。下面先来看看位图的缺点:
-
数据密集时效率比较高:当数据分布均匀时,位图的效率很高,占用的空间也很理想;但是如果数据稀疏,比如大部分数据都分三段,1-1000,100000-500000,100000000-200000000,这时候的位图必须按照最大值进行初始化申请空间,这就造成了很多空间的浪费。
-
最大数据量要求已知:因为位图需要根据数据量来初始化位图存储数组,所以要求在设计之初知晓数据量,然后根据最大数据量进行数据初始化,如果后续数据量超出了预先的最大值,则位图很难处理。
-
适用范围有限:位图比较适合处理数值类型的数据,针对于字符串类的数据虽然可以使用hash函数将字符串映射到某一位,但缺点是单一哈希函数发生冲突的概率太高,造成错误率过高。若要降低冲突发生的概率到1%,有种办法就是就要将位图的长度设置为字符串个数的100倍。
所谓时势造英雄,韦小宝是这样,布隆过滤器也是如此。针对上述问题,布隆过滤器给出了自己的解决方案:首先,布隆过滤器打算在位图的基础上去解决刚才的三个问题,从而“基本”达到目的,此处的基本很重要,先卖个关子,大家记住即可,下面进行解释。
减少哈希冲突概率
上文说了单一hash函数的冲突概率太高,那么单一函数太高,那多个函数会不会好些呢?
答案是肯定的,于是布隆过滤器使用多个哈希函数来对字符串进行映射,生成多个位放到位图中存储。如下图所示:
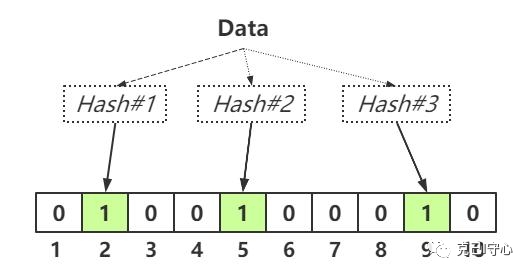
查询时,用同样的哈希函数对字符串进行处理,生成多个位,有一位如果是0,则说明该字符串肯定不存在;而如果所有位都是1,那说明该字符串大概率存在。下图展示的就是字符串肯定不存在,因为有一个哈希函数返回0:
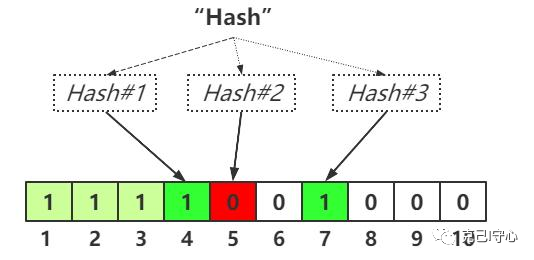
大概率存在于位图中?Excuse me?这种答案抛给用户,让用户如何是好?信你还是不信?Don't worry!车到山前必有路,这里有两个问题需要确认:
-
首先就是正确率的问题,如果正确率过低,那这个算法就没什么存在的意义了,但是如果正确率很高,仅有很少的错误率,那在容错成本很低的前提下总会有办法进行容错。那如何提高正确率呢?其实有两个因素,一个就是位图的位数与数据量的比值,其实就是数据冗余量;第二个就是哈希函数的个数。关系如下图所示:
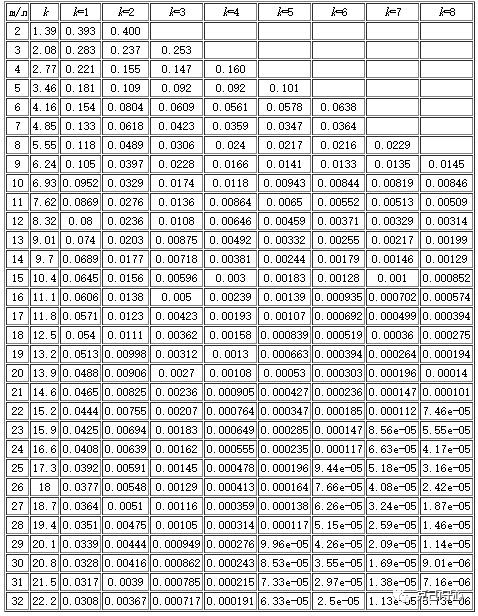
图中的字母代表意思如下:
-
m :BitSet 位数
-
n :插入字符串个数
-
k :hash函数个数
从上图可以看出,数据冗余量越大,哈希函数越多,错误率越低。但是总体来看,错误率控制在1%以内,相比于位图需要100倍的数据膨胀率,布隆过滤器的成本消耗就小得多,所以现实中使用场景就多了很多。
考虑到实现成本,每种组件或者场景在实现的时候会根据自身的具体情况选择具体的比例,从而达到最佳性价比,毕竟大数据处理说到底还是一门生意,成本是技术选型的重要因素之一。这也同样解释了上文的“基本”的含义。
-
确定了正确率的问题后,接下来就是关键的容错了,怎么容错才算完美,既能解决问题,又能照顾容错成本呢?这个就和具体的使用场景有关了,下面会结合业务场景来具体说明。
降低数据稀疏带来的影响
说完了减少哈希冲突概率后,问题就解决了一大半,剩下的问题就顺手解决了。由于布隆过滤器使用多个哈希函数进行处理,所以生成的值正常会均匀分布,数据不均衡从而造成数据稀疏时成本较高的问题就彻底解决了。
对数据量已知的要求降低
虽然说数据量增大超过预先设计的最大值也会对布隆过滤器造成影响,但是影响并不是很严重,除非差别过于巨大。因为实际数据量增大后,只会影响到上图m/n的值,带来的影响只是略微影响到布隆过滤器的正确率,而不像位图那样几乎无法处理。
就这样,一个大数据世界中的韦小宝已经呼之欲出了,剩下就是找到属于他发挥的舞台,然后找到7个美女老婆了。
Where布隆过滤器
说完布隆过滤器的特点以及实现原理,下面看看布隆过滤器的使用场景。
通过不同场景中使用,我们可以看到布隆过滤器是如何发挥重要作用,以及如何扬长避短进行容错的。也就同时知道了布隆过滤器是如何赢得“美女”芳心,从而抱得美人归的。
URL或者Email去重
这其实是布隆过滤器初次亮相的场景,布隆过滤器在这个场景中崭露头角,迅速被大家所认知。
场景
假设我们要写一个爬虫程序。由于网络间的链接错综复杂,蜘蛛在网络间爬行很可能会形成“环”,爬虫就会进入一个无限怪圈,找不到出路,程序出现崩溃。所以为了避免形成“环”,就需要知道蜘蛛已经访问过那些URL,也就是如何判重。
同样的,如果我们需要给很多人发邮件从而通知或者确认某些事情,为了不重复给同一个人发多次而引发大规模的不满,我们要如何知道已经发过邮件的那些Email,同样也是如何判重。
实现
这时布隆过滤器就登场了,将爬取过的URL以及发过邮件的Email放入到布隆过滤器中,下次发现新的URL或者Email就去布隆过滤器中问问,就知道是不是处理过了。
防止缓存穿透
上面的场景的小试牛刀后,布隆过滤器决定乘胜追击,再接再厉,扩大自己的知名度。
场景
在数据库访问中,一般都会有缓存层来减少数据库的直接访问。一来提升查询效率;二来也可以保护数据库不会在高并发的场景下被搞崩溃。
所以正常的查询流程是client先访问缓存层,如果命中直接返回;如果未命中,则认为可能是缓存与数据库不一致或者不是热数据,会去查询数据库。
这本来是很正常的业务逻辑,在缓存命中率很高的情况下效果很好效率很高,但是有一种恶意攻击行为,使用一个完全不可能存在的key频繁访问查询接口,由于key不存在,则缓存完全无法起到作用,直接频繁访问数据库,直到数据库被搞瘫痪或者始终处于高负载的情况影响正常的业务逻辑的开展。
实现
这时布隆过滤器又登场了,将数据库中对应缓存的所有key放入到布隆过滤器中,下次穿透缓存层的数据就去布隆过滤器中问问数据库中到底有没有这个值,有的话再去数据库查,没有的话就直接返回结果,避免无效的数据库查询。从而达到保护数据库,英雄救美的效果。
NOSQL数据库的索引过滤器
经过上述两次战役,已经使布隆过滤器名扬天下了,但是真正使布隆过滤器走上人生巅峰的是大数据时代的NOSQL数据库中的应用,在这个场景下,布隆过滤器真正的实现了超神之路,HBase、Cassandra、RocksDB以及LevelDB都是布隆过滤器的一众迷妹。
场景
在NOSQL数据库中,虽然经过无数次的shard以及index后,数据查询的效率得到了显著的提升,但是定位到最小粒度的索引文件后,还是需要遍历才能得知数据是否存在,如果存在,再去查询对应的数据。这对于NOSQL数据库来说是不可接受的,此时咱们的布隆过滤器再度登场。
实现
布隆过滤器存储目标索引对应的key,查询时先拿key查询布隆过滤器,如果存在后再去索引文件中遍历查询。这样能直接判断出索引中是否包含需要查询的数据,从而避免无用的遍历操作。达到提升效率的目的。
容错
最后根据上面的场景来统一说一下容错这个听起来很有技术含量又高大上的操作。我相信文章看到现在的小伙伴们可能已经猜到了布隆过滤器是怎么做容错的了。没错,布隆过滤器的容错操作就是不容错!!!
纳尼?不容错?有没有搞错?我没听错?是的,确实不容错,为什么不容错呢?因为容错的目的是消除错误带来的严重影响,但是大家回头看看如果布隆过滤器不容错会有什么影响?无非就是多爬取几个网页;多发几封邮件;多查几次数据库以及多遍历几次文件。
后果很严重吗?显然不是!!!由于布隆过滤器的正确率可控,所以相比于绝大多数正确的过滤,几次误判导致的消耗不值得一提,所以不容错就显得理所当然了,这个懒可以偷。诸如韦小宝时不时的偷奸耍滑,无伤大雅。
总结
上文总结了布隆过滤器的超神之路,相比于常规的处理方式,布隆过滤器算得上另辟蹊径,在尽量保证准确率的前提下,加速了大数据处理以及查询的速度,容错处理也“堪称经典”....在很多场景下发挥了奇效。
这正如韦小宝,在小说中的那种环境下如鱼得水,斩获了不世之功;获取了海量宝藏;实现了最终梦想。
这就是所谓的时势造英雄吧,技术如此,人也亦然。
最后,笔者长期关注大数据通用技术,通用原理以及NOSQL数据库的技术架构以及使用。如果大家感觉笔者写的还不错,麻烦大家多多点赞和分享转发,也许你的朋友也喜欢。
最后挂个公众号二维码,欢迎大家关注,谢谢大家支持。















 618
618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









