






**总结性观点:**首先在我看来vector更像一个高级数组,其数组中可以放各种类型的数,而且带有插入等等强大的功能。
到了这里有了前面string的基础我们不妨换个学法,我先把重要的类中的函数进行复刻,然后在教大家如何使用,最后在总结一些会出现的问题。
1.功能代码实现
1.成员变量
private:
iterator _start; //相当于迭代器begin的位置
iterator _finish;//相当于迭代器end的位置
iterator _endofstorage;//容量的最后一个位置的后一个
2.构造函数
//构造函数
template<class InputIterator> //这样first可以带地址,也可以带下标了
vector(InputIterator first, InputIterator last)
:_start(nullptr)
,_finish(nullptr)
,_endofstorage(nullptr)
{
while (first != last)
{
push_back(*first);
first++;
}
}
3.析构函数
void swap(vector<T>& v) //这里可以看出为什么一开始要把3个参数都设置成nullptr
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_endofstorage, v._endofstorage);
}
vector(const vector<T>& v)
:_start(nullptr);
, _finish(nullptr);
, _endofstorage(nullptr)
{
vector<T> tmp(v.begin, v.end);
swap(tmp);
}
4.赋值运算符重载
vector<T>& operator=(vector<T> v) // 推荐
{
swap(v);
return *this;
}
5.析构函数
//析构函数
~vector()
{
delete[]_start;
_start = _finish = _endofstorage;
}
6.[]运算符重载
T& operator[](size_t i)
{
assert(i < size());
return _start[i];
}
7.reserve复现
// 测试vector的默认扩容机制结论如下
// vs:按照1.5倍方式扩容
// linux:按照2倍方式扩容
void reserve(size_t n)
{
if (n > capacity())
{
size_t sz = size();
T* tmp = new T[n];
if (_start)
{
memcpy(tmp, _start, sizeof(T*) * sizeof());
delete _start;
}
_start = tmp;
_finish = _start + sz;
_endofstorage = _start + n;//没出错,应该是已有n个空间的后一个
}
}
8.resize复现
void resize(size_t n, const T& val = T())
{
if (n <= capacity())
{
_finish = _start + n;
}
else
{
if (n > capacity())
{
reserve(n);
}
while (finish != _start + n)
{
*_finish = val;
++_finish;
}
}
}
9.insert实现
iterator insert(iterator pos, const T& x)
{
assert(pos >= _start);
assert(pos <= _finish);
if (_finish == endofstorage)
{
//这里注意一个pos失效问题就是当我扩容开新空间的话我的pos会失效,这是原库的缺陷,这里我们选择自己解决
size_t len = pos - _start;
reserve(capacity() == 0 ?4 :capacity() * 2);
pos = _start + len;
}
iterator end = _finish - 1; //直接用end当判断条件更为直观
while (end >= pos)
{
*(end + 1) = *end;
end--;
}
*pos = x;
_finish++; //reserve已经改了endofstorage的数值了,这边finish其实已经改过一次了,但是因为插入了一个数,所以选择++
return pos;
}
10.erase实现
iterator erase(iterator pos)
{
assert(pos >= _start);
assert(pos <= _finish);
iterator begin = pos + 1;
while (begin != _finish) //还是仿照insert那样的步骤就行
{
*(begin - 1) = *begin;
begin++;
}
_finish--;
return pos;
}
11.尾插实现
void push_back(const T& x)
{
if (_finish == _endofstorage)
{
// 扩容
reserve(capacity() == 0 ? 4 : capacity() * 2);
}
*_finish = x;
++_finish;
}
12.尾删实现
void pop_back()
{
assert(_finish > _start);
--_finish;
}
2.实际使用
1.初始化的常用案例
int main()
{
int arr[] = { 1,2,3,4 };
vector<int> v{ 1, 2, 3, 4 };// 使用列表方式初始化,C++11新语法
vector<int> myself(arr, arr + sizeof(arr) / sizeof(int));//相当于给个begin初始化
vector<int> a();//空int()
vector<int> b(4, 100);//放入4个100
vector<int> c(myself);//拷贝构造myself
for (vector<int>::iterator it = myself.begin(); it != myself.end(); ++it)//迭代器循坏打印一下拷贝后的myself
cout<<*it;
return 0;
}
2.有关find的一些事情
首先在vector中是不提供find的,这里我们使用的find是stl提供的全局查找的find,而我们之前学的string提供了find,这个find和我们的全局find是不一样的,我们可以对此进行参考对比。
下面的代码是全局find的使用案例
int main()
{
vector<int> v{ 1, 2, 3, 4 };
auto pos = find(v.begin(), v.end(), 3); //先给个范围然后去找3,这里返回的其实是迭代器所以用auto接收省得写
}
3.有关一些其他使用的唠嗑
其实在我看来常用的一些使用方式和string没多大区别,无非vector在insert或者erase里面传的是地址,而string里面可以用数组下标和地址,其他用法基本没区别,所以便不在一一展示这些。
4.重难点双vector的使用(其实本质上来说就是二位数组的创建)
这里我们以杨辉三角为例子带大家好好理解一下这个动态二位数组:
// 以杨慧三角的前n行为例:假设n为5
void test2vector(size_t n) {
// 使用vector定义二维数组vv,vv中的每个元素都是vector<int>,vv总共有n个元素
vector<vector<int>> vv(n);
// 将二维数组每一行中的vecotr<int>中的元素全部设置为1
for (size_t i = 0; i < n; ++i)
{
vv[i].resize(i + 1, 1);
}
// 给杨慧三角出第一列和对角线的所有元素赋值
for (int i = 2; i < n; ++i)
{
for (int j = 1; j < i; ++j)
{
vv[i][j] = vv[i - 1][j] + vv[i - 1][j - 1];
}
}
}
当n为5时,就为下图这种情况:
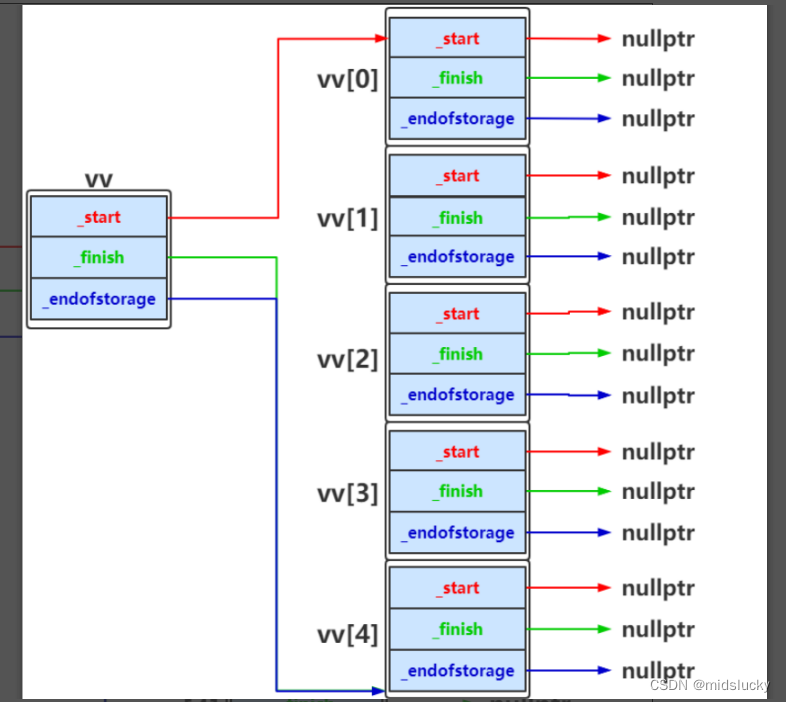
3.一些有关迭代器失效问题的碎碎念
1.插入数据问题
此类问题发生在扩容的时候,当我想插入一个数,假设我插入的这个地址为pos,但是若是此时发生扩容,便开了一块新的空间,那么这个时候我的pos指向的空间便被系统释放掉了,因此造成运行时的奔溃。
2.erase删除问题
假设我的pos删除的是数组最后一个位置,那么此时后面已经没有数字往前挪动了,因此pos的位置一直为空。
还有当我们删除奇函数和偶函数的时候,别忘记每删除一个数字都会往前挪动去补坑。
3.memcpy
memcpy实质上来讲是浅拷贝的一种方式,而当我拷贝的对象如果发生动态内存管理,比如vector扩容,那我地址就丢失了,系统就会报错,所以解决方法是我在拷贝是用人为优化过后迭代器遍历的方式去代替。















 141
141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









