






最近因为工作需要,重新温习了消息队列,打算从它的设计原理开始梳理,再深入到实现方案和源码,最后再结合实际案例分析该使用哪种消息队列。该文章参考了很多大牛的文章,特别是李玥老师的消息队列高手课。
日志文件?
The Log: What every software engineer should know about real-time data’s unifying abstraction,对应的中文译稿在这里:《日志:每个软件工程师都应该知道的有关实时数据的统一抽象》。这篇博文被评为程序员史诗般必读文章,说实话,里面讲的东西在今天看来都是些看视无比简单和习以为常的东西,很惊讶他们的总结和抽象能力。下面我来截取一些文章的重点内容,让大家鸟瞰一下:
日志作为独立服务,能生成持久的、可重复播放的历史记录,核心是以确定的方式按照自己的速率让许多机器回放历史。(翻译成大白话就是,日志就是系统的所有信息流水,从它出生到消失,日志都记录得清清楚楚,所以我们就能利用日志做恢复,复制等一系列事情)
日志得格式没有固定,可用根据系统得需要生成定制化得格式,因为它不是给人读得,是给机器读的,用来快速完成我们想要的事情。
我们可以看下下面三种日志:
数据库日志
日志文件可以快速的持久化,然后再重放
副本之间数据的同步也通过日志文件的同步重放来实现
使用日志来进行数据订阅,这种抽象非常适合支持各种消息传递、数据流和数据处理
分布式系统的日志
状态机复制模型-主动-主动模型,主备模型(只记录结果)
可以看做是对共识问题建模的数据结构
变更日志101:表和事件是双重的
表支持静态数据
日志则捕获变化
源代码版本控制
消息模型:队列-主题-分区
首先,这些消息队列的术语没有统一的叫法,因为技术发展太快了,标准都跟不上了。(JMS\AMQP)下面我们从架构演进的角度来看看到底怎么回事。
最初的消息队列,就是一个严格意义上的队列。这就是最初的一种消息模型:队列模型。
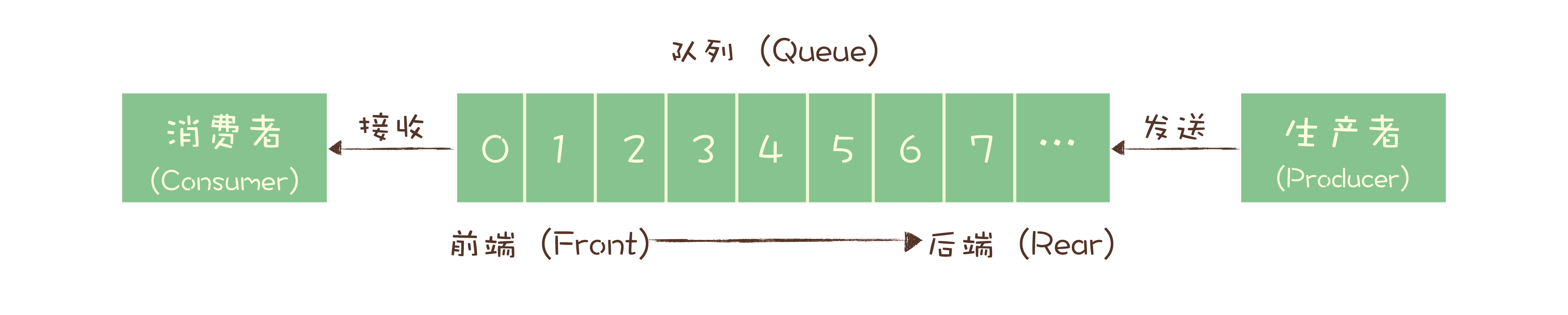
一个队列,生产者可以有多个,但消费的时候弹出队列的数据只能被一个消费者消费,且为了保证顺序,前一个没有弹出前后面的数据不能被消费。所以对于一份数据想同时被多个消费者消费的时候,这种模式肯定不行的。
为了解决这个问题,演化出了另外一种消息模型:“发布 - 订阅模型(Publish-Subscribe Pattern)”。
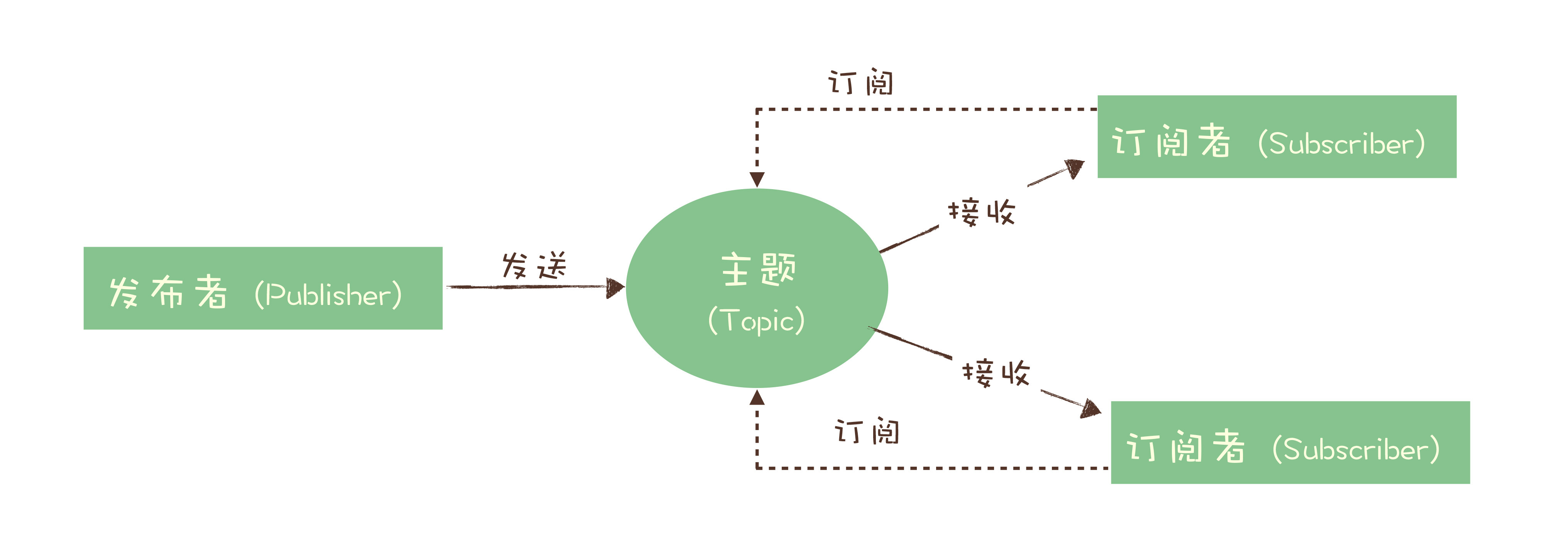
在消息领域的历史上很长的一段时间,队列模式和发布 - 订阅模式是并存的,有些消息队列同时支持这两种消息模型,比如 ActiveMQ。我们仔细对比一下这两种模型,生产者就是发布者,消费者就是订阅者,队列就是主题,并没有本质的区别。它们最大的区别其实就是,一份消息数据能不能被消费多次的问题。
实际上,在这种发布 - 订阅模型中,如果只有一个订阅者,那它和队列模型就基本是一样的了。也就是说,发布 - 订阅模型在功能层面上是可以兼容队列模型的。现代的消息队列产品使用的消息模型大多是这种发布 - 订阅模型,当然也有例外。
Exchange 位于生产者和队列之间,生产者并不关心将消息发送给哪个队列,而是将消息发送给 Exchange,由 Exchange 上配置的策略来决定将消息投递到哪些队列中。
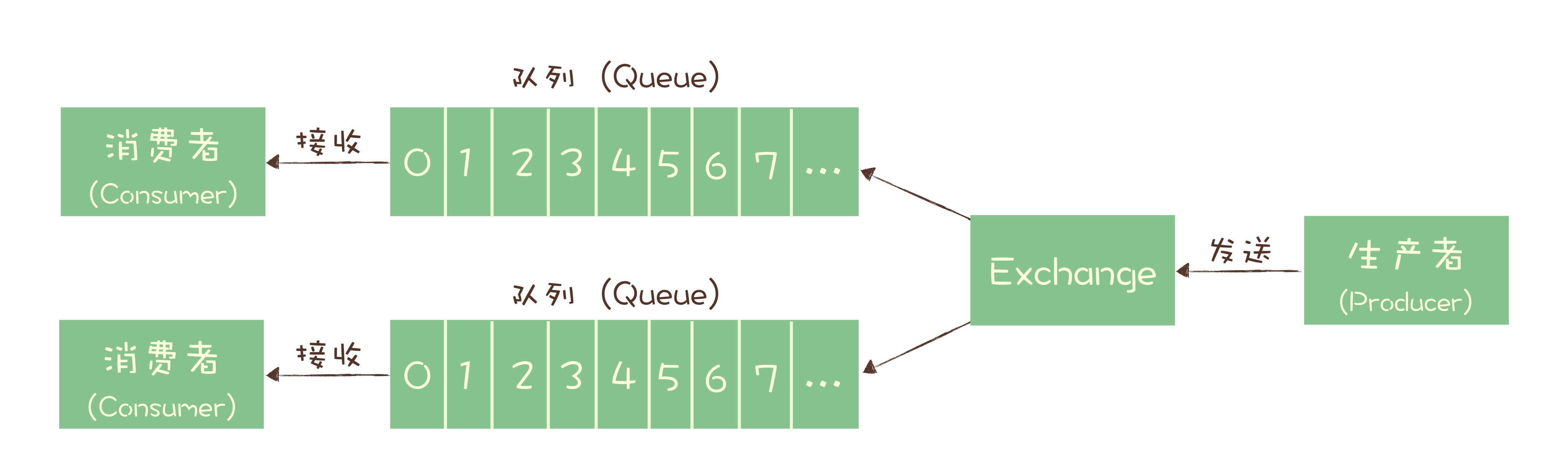
但为了保证消费者消费能力的提高,所以把一个topic分成了多个队列来存储数据,这样就能对应多个消费者消费,提高消费速度,同时也能保证数据在topic的某个队列里局部有序了。
如何利用事务消息实现分布式事务?
其实很多场景下,我们“发消息”这个过程,目的往往是通知另外一个系统或者模块去更新数据,消息队列中的“事务”,主要解决的是消息生产者和消息消费者的数据一致性问题。如下案例:
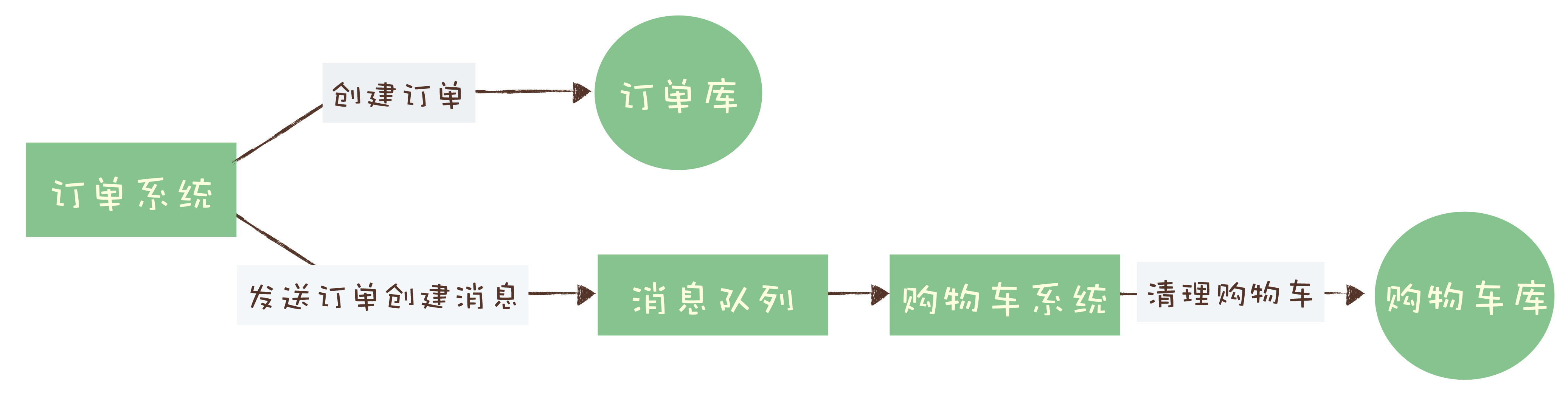
对于订单系统来说,它创建订单的过程中实际上执行了 2 个步骤的操作:
- 在订单库中插入一条订单数据,创建订单;
- 发消息给消息队列,消息的内容就是刚刚创建的订单。
购物车系统订阅相应的主题,接收订单创建的消息,然后清理购物车,在购物车中删除订单中的商品。
事务消息适用的场景主要是那些需要异步更新数据,并且对数据实时性要求不太高的场景。比如我们在开始时提到的那个例子,在创建订单后,如果出现短暂的几秒,购物车里的商品没有被及时清空,也不是完全不可接受的,只要最终购物车的数据和订单数据保持一致就可以了。
回到订单和购物车这个例子,我们一起来看下如何用消息队列来实现分布式事务。
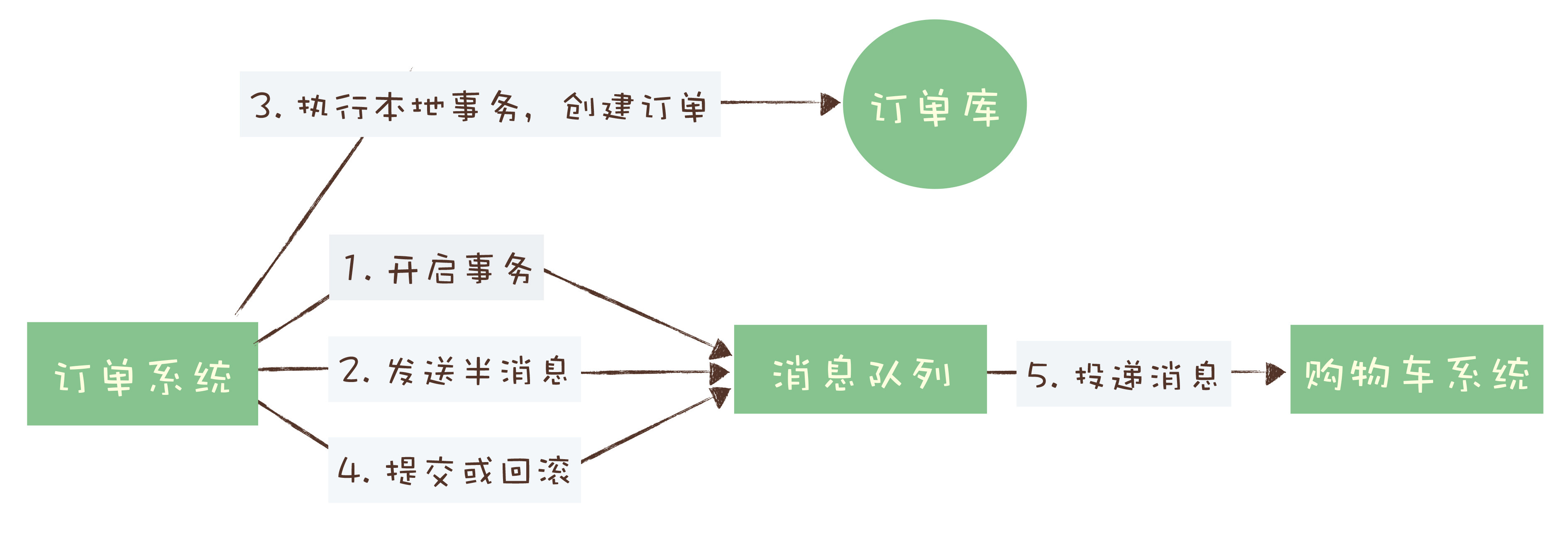
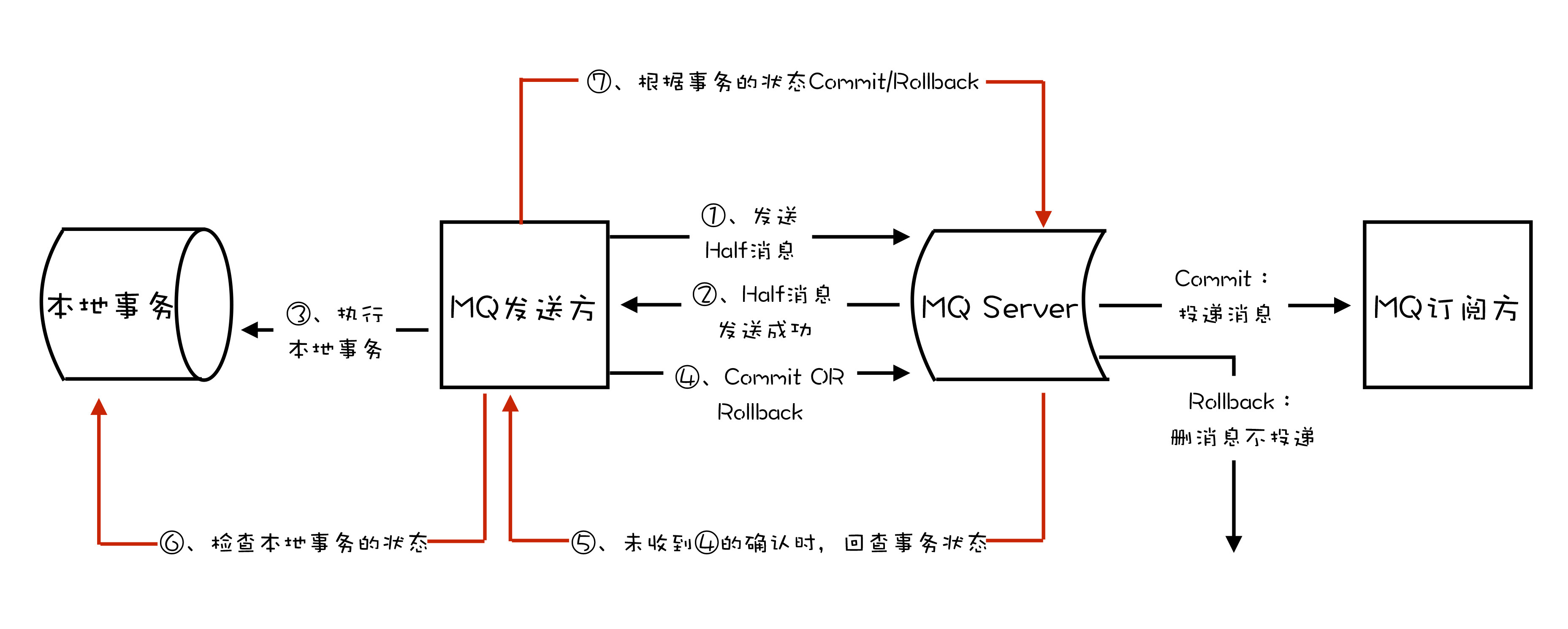
如果你足够细心,可能已经发现了,这个实现过程中,有一个问题是没有解决的。如果在第四步提交事务消息时失败了怎么办?对于这个问题,Kafka 和 RocketMQ 给出了 2 种不同的解决方案。Kafka 的解决方案比较简单粗暴,直接抛出异常,让用户自行处理。我们可以在业务代码中反复重试提交,直到提交成功,或者删除之前创建的订单进行补偿。RocketMQ 则给出了另外一种解决方案。增加了事务反查的机制来解决事务消息提交失败的问题。如果 Producer 也就是订单系统,在提交或者回滚事务消息时发生网络异常,RocketMQ 的 Broker 没有收到提交或者回滚的请求,Broker 会定期去 Producer 上反查这个事务对应的本地事务的状态,然后根据反查结果决定提交或者回滚这个事务。
使用 RocketMQ 事务消息功能实现分布式事务的流程如下图:
如何确保消息不会丢失?
首先生产者生产消息后接收ack响应这个肯定要做的,但是我们还是担心消息会不会丢失了,所以需要设计消息的丢失检查机制,下面讲讲如何利用消息队列本来的功能如何实现。
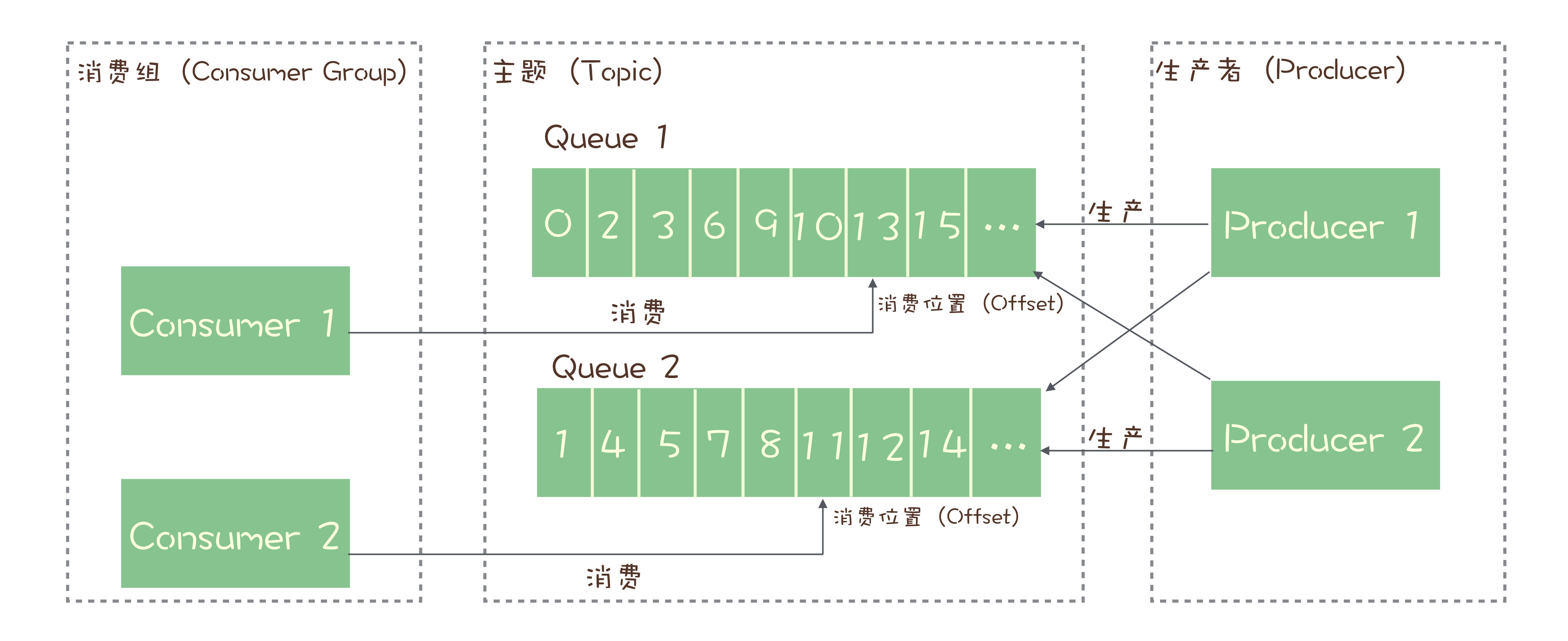
我们可以利用消息队列的有序性来验证是否有消息丢失。原理非常简单,在 Producer 端,我们给每个发出的消息附加一个连续递增的序号,然后在 Consumer 端来检查这个序号的连续性。
当然如何在分布式环境里面,有多个队列多个消费者的情况,那这个序号就要根据队列来限制的了,指定的队列由指定的消费者消费并按照指定的规则来校验。
如下是确保消息可靠性的图

生产阶段: 在这个阶段,从消息在 Producer 创建出来,经过网络传输发送到 Broker 端。
存储阶段: 在这个阶段,消息在 Broker 端存储,如果是集群,消息会在这个阶段被复制到其他的副本上。
消费阶段: 在这个阶段,Consumer 从 Broker 上拉取消息,经过网络传输发送到 Consumer 上。
如何处理消费过程中的重复消息?
上面说的如何确保消息不会丢失的方案,会导致消息至少被消费一次,如果要确保消费过程中不重复消费消息,就需要使用者做些特殊处理,幂等消费。
下面我给你介绍几种常用的设计幂等操作的方法:
1. 利用数据库的唯一约束实现幂等;
2. 为更新的数据设置前置条件,其实就是数据版本号的概念;
3. 记录并检查操作,这种方式比较复杂,在发送消息时,给每条消息指定一个全局唯一的 ID,消费时,先根据这个 ID 检查这条消息是否有被消费过,如果没有消费过,才更新数据,然后将消费状态置为已消费。在“检查消费状态,然后更新数据并且设置消费状态”中,三个操作必须作为一组操作保证原子性,才能真正实现幂等,否则就会出现 Bug。这里就需要用到全局唯一id生成算法+分布式锁+上面说到的分布式事务解决方案。















 188
188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









