







pcolor是matlab里绘制矩阵的函数,它可以把数据通过颜色表示出来。
但是它的使用,特别对于初学者来说,有点晦涩难懂。
我们通过几个问题来认识一下这个函数的使用
pcolor绘制的颜色从哪里来?
通过网上任意一些代码样例,可以使用pcolor绘制出颜色方格出来。但是它的颜色是怎么来的?
比如下面这段
C=zeros(10);
pcolor(C);
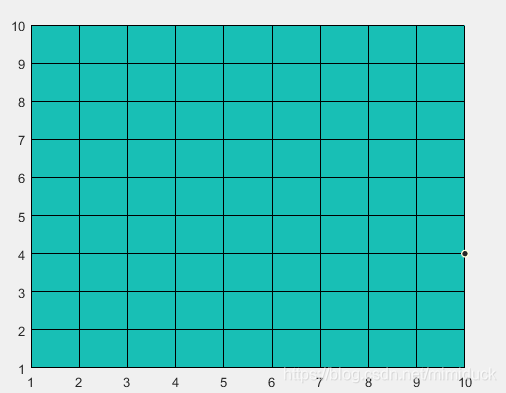
为什么是这种蓝绿色?
其实它的颜色由colormap来指定,matlab系统内部其实定义了一些色系,如下,
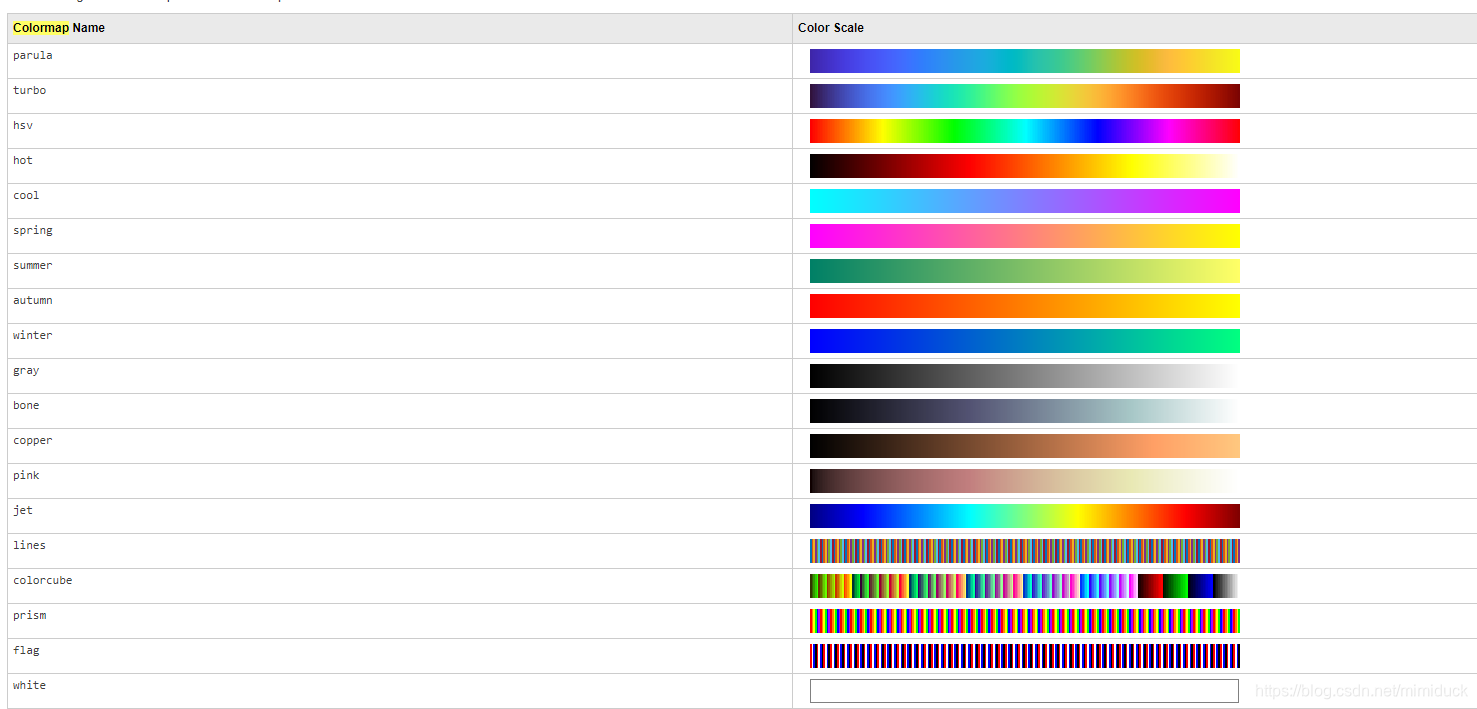
如果访问不了的官网的,我这里贴出来可以选择的类型
- parula
- turbo
- hsv
- hot
- cool
- spring
- summer
- autumn
- winter
- gray
- bone
- copper
- pink
- jet
- lines
- colorcube
- prism
- flag
- white
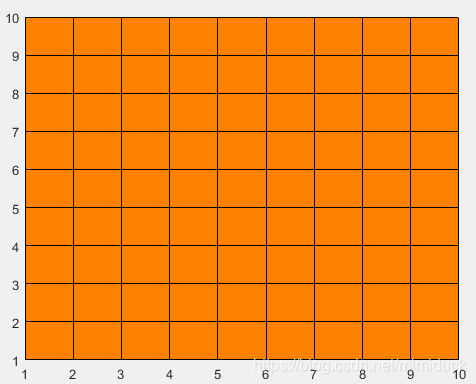
第一个色系名字叫parula,它是系统默认的,所以如果不指定的话,它就是使用的parula。
也相当于使用了colormap default
我们换一个色系试一下呢,比如colormap autumn。看,颜色变了吧
pcolor绘制单元跟入参矩阵是什么关系?
pcolor的每一个cell绘制的其实是相邻(左右上下)4个点的左下角(列需要反转),该值在colormap中的位置。值如果是0,则为色系开始的颜色。值越大,选择颜色越往后。
那么矩阵的shape(M,N)则会对应pcolor绘制的cell shape(M-1,N-1)
相邻两个点的最大值,会作为分割colormap的份数。在Figure图显示框里,可以点击colormap来查看。
如下面的例子,
C = [10 8 6 4 2;
1 4 0 1 1;
1 2 0 1 1;
1 1 1 1 10];
% C=zeros(10);
pcolor(C);
% colormap(mymap)
colormap autumn
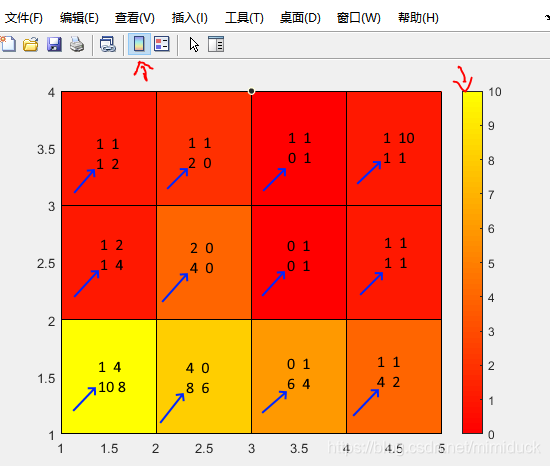
值得注意的时,这里的cell列的顺序跟矩阵中的顺序是相反的。
虽然矩阵是
10 8 6 4 2;
1 4 0 1 1;
1 2 0 1 1;
1 1 1 1 10
但是在pcolor中处理时,倒转为
1 1 1 1 10;
1 2 0 1 1;
1 4 0 1 1;
10 8 6 4 2;
所以上图中取左下角是倒转后的取值
pcolor三个参数中前两个参数是干什么的?
pcolor有一种入参是三个的,如下
pcolor(X,Y,C)
其中X和Y是坐标。
举个例子来看,如下图4个cell,有6个点,这六个点的坐标我标记在图中。
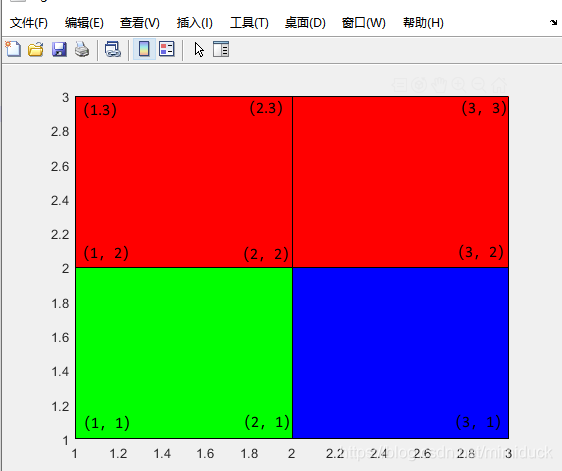
坐标值如下:
(1,3)(2,3) (3,3)
(1,2)(2,2) (3,2)
(1,1)(2,1) (3,1)
写成X,Y则为:
X= [1,2,3;
1,2,3;
1,2,3]
Y= [1,1,1;
2,2,2;
3,3,3]
注意: cell的y轴还是做了反转
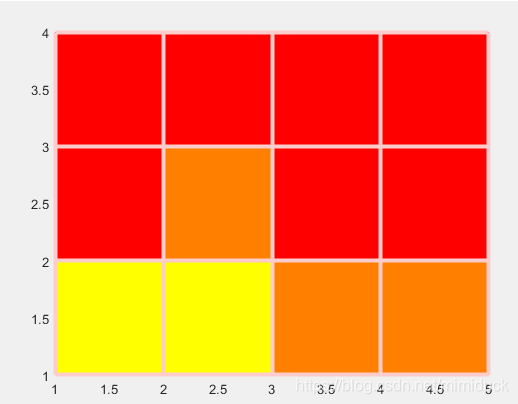
pcolor如何把cell描边?
可以通过EdgeColor 设置边的颜色,通过LineWidth设置边的宽度
通过下面的例子看一下,
C = [10 8 6 4 2;
1 4 0 1 1;
1 2 0 1 1;
1 1 1 1 10];
s = pcolor(C);
s.EdgeColor = [1 0.8 0.8];
s.LineWidth = 3;
colormap autumn
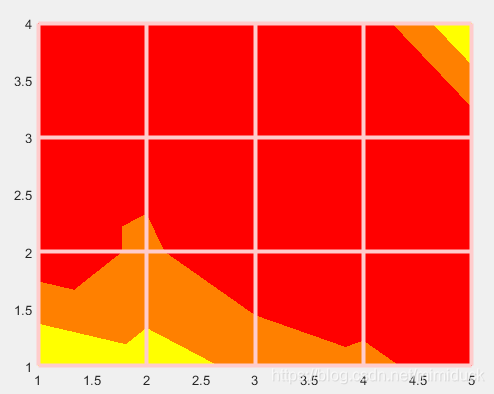
pcolor怎么实现渐变色
渐变实际上是通过差插值interpolate实现的,具体是通过**FaceColor = ‘interp’;**来设置
C = [10 8 6 4 2;
1 4 0 1 1;
1 2 0 1 1;
1 1 1 1 10];
s = pcolor(C);
s.EdgeColor = [1 0.8 0.8];
s.LineWidth = 3;
s.FaceColor = 'interp';
colormap autumn

















 4260
4260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









