






目录
方法三(赶时间只要代码的到这里)
场景描述:
当含有多个list,通过对比,将所有list中,重复出现的元素只保留在一个list中。
例如:
list1: [2, 3, 4, 5]
list2: [2, 6]
list3: [4, 7, 6, 8]
list3: [4, 8]
最后得到
result1=[2, 3, 4, 5]
result2= [6]
result3= [7, 8],
result4=[]
解决办法
下列方法由代码量多到少的排列,想要最少代码解决的看最后一个方法。
主要思想:通过集合的思想,交集、并集、差集来计算。这里考虑最复杂的情况,四个集合,也就是四个list中都含有重复的元素,如图
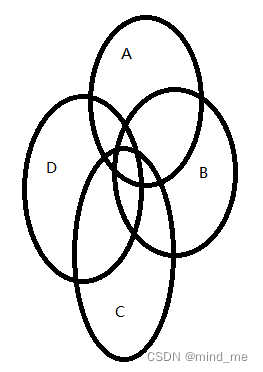
方法1
解决逻辑
先将A取出,剩下的三个集合都去掉与A的交集,保证A的元素保留一份重复的,如图
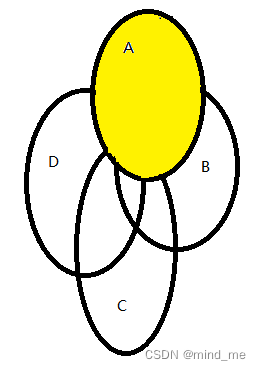
重复这个步骤,取出集合B,将集合C、D去掉与集合B的交集:
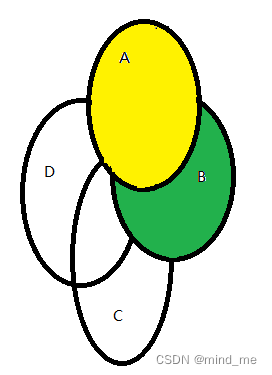
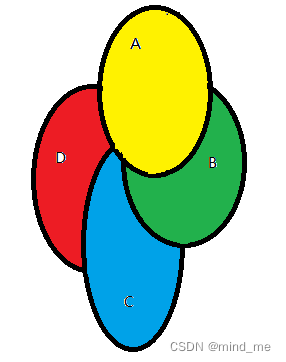
如此,最后保证所有的集合中不再有重复的元素,且保留在某一个集合中。
实现
初始数据
Integer[] l1={2,3,4,5};
Integer[] l2={2,6};
Integer[] l3={4,7,6,8};
Integer[] l4={4,8};
List<Integer> list1=new ArrayList<>(Arrays.asList(l1));
List<Integer> list2=new ArrayList<>(Arrays.asList(l2));
List<Integer> list3=new ArrayList<>(Arrays.asList(l3));
List<Integer> list4=new ArrayList<>(Arrays.asList(l4));// 取1与2、3、4的交集
Collection<Integer> interList12 = CollectionUtil.intersection(list1, list2);
Collection<Integer> interList13 = CollectionUtil.intersection(list1, list3);
Collection<Integer> interList14 = CollectionUtil.intersection(list1, list4);
//取2、3、4与1有交集的差集
ArrayList<Integer> result2 = new ArrayList<>(CollectionUtil.disjunction(list2, interList12));
ArrayList<Integer> result3 = new ArrayList<>(CollectionUtil.disjunction(list3, interList13));
ArrayList<Integer> result4 = new ArrayList<>(CollectionUtil.disjunction(list4, interList14));
// 取2与3、4的交集
Collection<Integer> interList23 = CollectionUtil.intersection(result2, result3);
Collection<Integer> interList24 = CollectionUtil.intersection(result2, result4);
//取3、4与2有交集的差集
result3 = new ArrayList<>(CollectionUtil.disjunction(result3, interList23));
result4 = new ArrayList<>(CollectionUtil.disjunction(result4, interList24));
Collection<Integer> interList34 = CollectionUtil.intersection(result3, result4);
result4 = new ArrayList<>(CollectionUtil.disjunction(result4, interList34));最后的结果分别是result1、result2、result3、result4;
需要注意:这里的CollectionUtil来自hutool工具的依赖
导入语句如下
import cn.hutool.core.collection.CollectionUtil;
添加的依赖语句如下:
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
</dependency>方法二
解决逻辑
与方法1类似,这里优化了去重的操作。初始化一个set,将要取出的集合放入set,set会自动去重,得到两个集合的并集。
将集合A的元素全部放入set,再通过set去重。此时set为空集和集合A的并集等于A的所有非重复元素
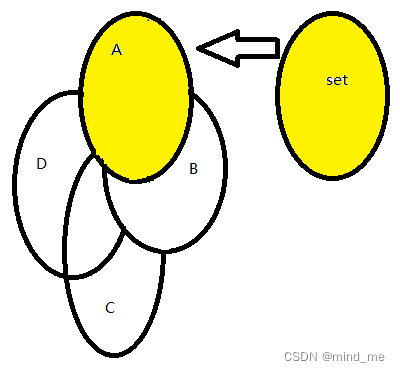
上一步将集合A取出了,接下来取出集合B,将集合B与set取交集,集合B与交集取差集,得到取出的集合B,将集合B中的元素也放入set中
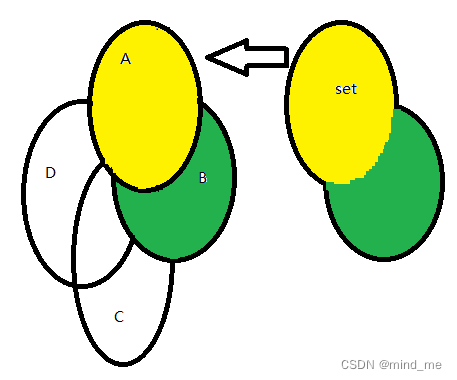
上一步将集合B取出了,接下来取出集合C,将集合C与set取交集,集合C与交集取差集,得到取出的集合C,将集合C中的元素也放入set中
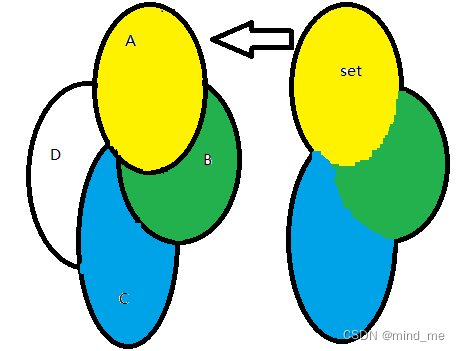
最后将集合D也取出。
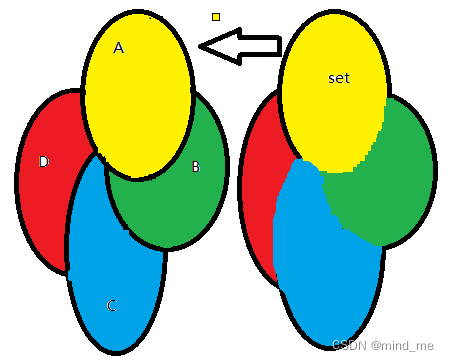
实现
Collection<Integer> intersection12 = CollectionUtil.intersection(hashSet, list2);
list2=new ArrayList<>(CollectionUtil.disjunction(list2,intersection12));
hashSet.addAll(list2);
Collection<Integer> intersection3set = CollectionUtil.intersection(hashSet, list3);
list3=new ArrayList<>(CollectionUtil.disjunction(list3,intersection3set));
hashSet.addAll(list3);
Collection<Integer> intersection4set = CollectionUtil.intersection(hashSet, list4);
list4=new ArrayList<>(CollectionUtil.disjunction(list4,intersection4set));
hashSet.addAll(list4);最终的结果为list1、list2、list3、list4
方法三
解决逻辑
在方法二的基础上,通过一个容器list将所有原始数据添加进去,对这个容器进行循环,最终的结果也保存在这个容器list中
关键代码
Set<Integer> hashSet = new HashSet<>(list1);
List<List<Integer>> ito=new ArrayList<>();
ito.add(list1);
ito.add(list2);
ito.add(list3);
ito.add(list4);
for (int i = 1; i < ito.size(); i++) {
Collection<Integer> intersection = CollectionUtil.intersection(hashSet, ito.get(i));
ito.set(i,new ArrayList<>(CollectionUtil.disjunction(ito.get(i),intersection)));
hashSet.addAll(ito.get(i));
}完整代码
Integer[] l1={2,3,4,5};
Integer[] l2={2,6};
Integer[] l3={4,7,6,8};
Integer[] l4={4,8};
List<Integer> list1=new ArrayList<>(Arrays.asList(l1));
List<Integer> list2=new ArrayList<>(Arrays.asList(l2));
List<Integer> list3=new ArrayList<>(Arrays.asList(l3));
List<Integer> list4=new ArrayList<>(Arrays.asList(l4));
Set<Integer> hashSet = new HashSet<>(list1);
List<List<Integer>> ito=new ArrayList<>();
ito.add(list1);
ito.add(list2);
ito.add(list3);
ito.add(list4);
for (int i = 1; i < ito.size(); i++) {
Collection<Integer> intersection = CollectionUtil.intersection(hashSet, ito.get(i));
ito.set(i,new ArrayList<>(CollectionUtil.disjunction(ito.get(i),intersection)));
hashSet.addAll(ito.get(i));
}结果都存在ito中

















 495
495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









