







仅供骆老师及他的学生参考.
1. 机器学习的角度
1.1 结构化数据的矩阵表示法
在机器学习领域,数据描述最基础、最常用的方式是
n
×
m
n \times m
n×m 矩阵
X
\mathbf{X}
X, 其中
n
n
n 是对象数 (对象 object 也称实例 instance),
m
m
m 是特征数 (特征 feature 也称属性 attribute),
x
i
j
x_{ij}
xij 表示第
i
i
i 个对象的第
j
j
j 个特征值, 为一个实数. 例:
X
=
[
29.35
106.33
19.2
29.33
106.34
19.8
29.36
106.35
19.6
29.32
106.32
20.5
]
\mathbf{X} = \left[ \begin{array}{ccc} 29.35 & 106.33 & 19.2\\ 29.33 & 106.34 & 19.8\\ 29.36 & 106.35 & 19.6\\ 29.32 & 106.32 & 20.5\\ \end{array} \right]
X=
29.3529.3329.3629.32106.33106.34106.35106.3219.219.819.620.5
它有 4 行, 各表示重庆市的一个地块, 3 列依次表示经度、纬度、年平均气温.
本质上每行数据是独立, 而且无序的, 所以将不同的行进行交换, 并不改变数据本身.
这种描述方式的优点包括:
- 简洁;
- 支持矩阵运算;
- 与关系数据库的二维表对应, 每个特征均具有原子性, 即不可再分.
缺点包括: - 仅支持实型数据;
- 无法描述数据之间的关系.
1.2 结构化数据的元组表示法
在粒计算领域, 数据描述最常见的是二元组 S = ( U , A ) S = (\mathbf{U}, \mathbf{A}) S=(U,A), 其中 U = { x 1 , … , x n } \mathbf{U} = \{x_1, \dots, x_n\} U={x1,…,xn} 为对象集合, A = { a 1 , … , a m } \mathbf{A} = \{a_1, \dots, a_m\} A={a1,…,am} 为属性集合.
| U \mathbf{U} U | a 1 a_1 a1 (坐标) | a 2 a_2 a2 (气温) | a 3 a_3 a3 (农作物) |
|---|---|---|---|
| x 1 x_1 x1 | ( 29.35 , 106.33 ) (29.35, 106.33) (29.35,106.33) | 19.2 ± 3.6 19.2 \pm 3.6 19.2±3.6 | 水稻 |
| x 2 x_2 x2 | ( 29.33 , 106.34 ) (29.33, 106.34) (29.33,106.34) | 19.8 ± 3.2 19.8 \pm 3.2 19.8±3.2 | 玉米 |
| x 3 x_3 x3 | ( 29.36 , 106.35 ) (29.36, 106.35) (29.36,106.35) | 19.6 ± 4.5 19.6 \pm 4.5 19.6±4.5 | 甘蔗 |
| x 4 x_4 x4 | ( 29.32 , 106.32 ) (29.32, 106.32) (29.32,106.32) | 20.5 ± 3.3 20.5 \pm 3.3 20.5±3.3 | 玉米 |
相对于矩阵描述, 这种描述的优点包括:
- U \mathbf{U} U 为一个集合, 所以自然就表示了一个无序性. 如前所述, 这在矩阵表示法中仅仅是隐含的约定;
-
a
j
(
x
i
)
a_j(x_i)
aj(xi) 的取值可以是实数, 整数 (或枚举型), 布尔型 (其实也是枚举型), 区间型, 模糊型, 集合型等等. 表 1 中
a
1
(
x
1
)
=
(
29.35
,
106.33
)
a_1(x_1) = (29.35, 106.33)
a1(x1)=(29.35,106.33) 给出了该地块的经纬度. 注意
(
29.35
,
106.33
)
(29.35, 106.33)
(29.35,106.33) 在这里看作一个数据, 而不是两个.
这种描述的缺点包括: - a j a_j aj 既是属性, 又是函数, 不太优美;
- a j ( x i ) a_j(x_i) aj(xi) 并不一定具有原子性, 不能与传统关系数据库二维表对应, 只能被面向对象的数据库支持.
如果要克服缺点 1, 就需要写出其完整形式 S = ( U , A , V , I ) S = (\mathbf{U}, \mathbf{A}, \mathbf{V}, I) S=(U,A,V,I), 其中 V \mathbf{V} V 是所有属性值的集合, I : U × A I: \mathbf{U} \times \mathbf{A} I:U×A 是信息函数, 如 I ( x 1 , a 1 ) = ( 29.35 , 106.33 ) I(x_1, a_1) = (29.35, 106.33) I(x1,a1)=(29.35,106.33).
1.3 GIS 数据的结构化模型 (仅说明)
在 GIS 领域, 至少需要两个属性集合来描述一个地块. 可以将地块对象的坐标、形状、边界静态信息, 以及温度、光照、农作物等动态信息可以分开. 也可以简单的数据类型 (可以用整数或实数表示)与复杂的数据类型 (如带有边界的形状)分开. Definition 1 就是根据这种想法写的.
基于该数据模型, 机器学习主流的方法都可以直接使用.
1.4 GIS 数据的图模型 (仅说明)
地块之间的相邻关系可能非常重要, 因此 Definition 2 使用图模型来描述. 如果两个地块相邻, 那么对应节点有一条连边 (暂时不考虑这条边的权重). 每个节点有自己的静态与动态属性.
该数据模型实际上就是知识图谱, 可惜我自己并没有深入研究. 其常用领域是社交网络, 每个节点对应于一个人. 有一大堆方法可以处理.
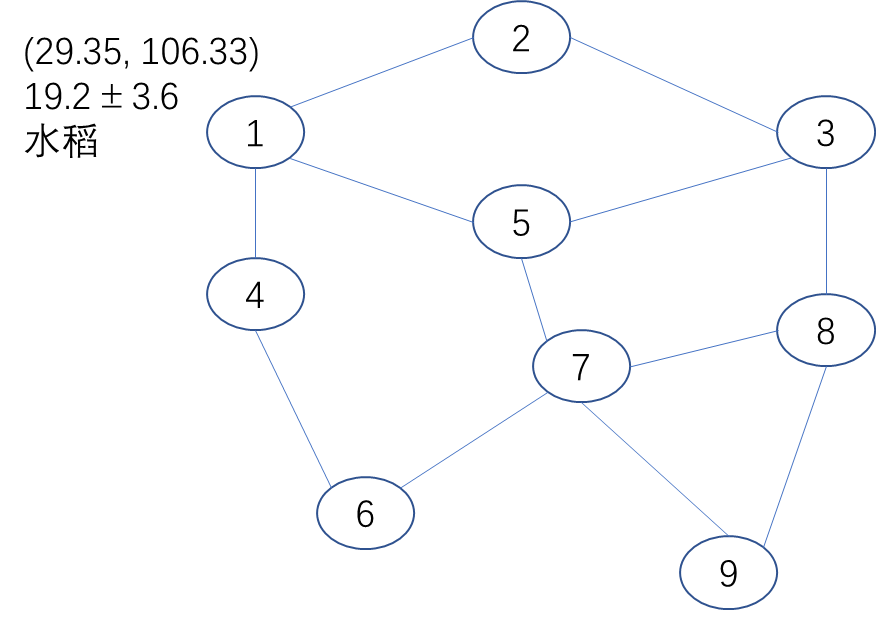
图 1. 图结构示例. 共有 V = { v 1 , v 2 , … , v 9 } \mathbf{V} = \{v_1, v_2, \dots, v_9\} V={v1,v2,…,v9}, 用数字表示. v 1 v_1 v1 与 v 2 v_2 v2 有连线, 表示这两个区域相邻. 每个节点上有自己的属性, 这里仅展示了 v 1 v_1 v1 的属性.
1.5 GIS 数据的层次化模型 (仅说明)
如果要表示大地块中包含若干小地块, 就需要层次化 (树状) 模型, 树根是整个的区域, 叶节点则是最小单元的地块.
1.6 机器学习任务的完成
以最简单的聚类问题为例,
- 在结构化模型之上, 可以定义对象之间的距离, 然后就可以用 kMeans 之类的算法进行聚类.
- 在知识图谱上, 有一系列的聚类算法.
- 层次化模型的各层, 可以由专家或用户指定, 其优点是具有很好的语义 (如市、区、县); 也可以从知识图谱, 以层次聚类的方式, 其优点是符合数据本身的特点. 但后一种情况最好固定叶节点的深度. 当前我认为层次化模型是图模型聚类的结果, 但在层次化模型上如何进一步做聚类, 我还没有想好.
图 2 展示了从图 1
注意: 从知识图谱或者基本结构化数据, 构建出一个树型的数据, 本身就是粒化的过程 (粒计算的思想).

2. GIS 的角度
地理专家的思维并不一定与机器学习的思维一致. 如何求同存异是关键.
2.1 不规则格网粒化表达的可靠计算问题
“格网”这个概念常用于描述平面区域, 在地理信息系统之外很少使用. 原因包括:
- 机器学习的数据可以看作是高维空间中的点 (1.1 节中的 X \mathbf{X} X 对应的是三维空间), 没有必要把高维空间划分成多个立方体的区域. 而且相应的很多区域可能没有任何数据点.
- 一般的思路是将这些点聚类为簇 cluster, 而不是划分空间本身.
- 格网仅能处理平面区域的信息, 表达能力有限. 其它信息 (如农作物种类) 都没法体现.
“不规则” 对于平面 (球面) 可能是一个问题, 但从图论的角度, 地块抽象为节点, 地块的形状是该节点上的一个属性 (可以用闭合曲线来表达). 如图 1 所示, 使用知识图谱表达相当自然.
“粒化” 至少有两个方面:
- 对于空间的节点, 进行粒化可以捋清它们的关系, 如图 2 所示.
- 对于节点的特征而言, 进行粒化可以支持不同的处理. 例如, 某节点的气温在一年范围内表示为一个时序, 粒化可以支持的单位包括小时、天、月、季等. 某节点的农作物也可以进行粒化.
“可靠计算” 应该与各属性的不确定性有关. 如某节点的油菜籽产量, 有可能介于 200-300 公斤. 进行估算的时候, 有些地块的估计值高了,有些低了, 但总和趋向于一个比较合适的值. 这类似于我估计自己的高考分数, 数学高了, 英语低了, 但最终误差只有 4 分 (涉嫌过度炫耀).
2.2 空间形态约束下时序特征重组的不确定分析问题
“空间形态” 可能与前面的“不规则”意思相近.
“约束” 可能表示的是闭合区域.
“时序特征”指的是一些动态的特征, 如气温、湿度. 实际上, 时序、动态性是 GIS 数据变得有意义的重要性质. 时序、多时序数据有一套自己的建模方式, 将它们与其它静态数据融合建模有很好的现实意义.
“特征重组”有可能是特征选择 (从 100 个特征中选择 10 个真正起作用的特征) 或特征提取 (从 100 个特征中提取 10 个新的特征, 它们可以是原始特征的线性组合, PCA 可以做; 也可以是非线性的, 深度学习最厉害.)
“不确定性”是机器学习的核心, 因为确定性的问题已经被科学计算、数据库系统搞完了.
“不确定性分析”或“不确定性建模”用于刻画不确定性, 便于进行定量的分析.
2.3 置信度控制下主动学习的可优化问题
“主动学习”本身是一个重要的研究方向, 它是指通过人机交互, 机器向专家咨询数据或标签, 以达到更少的数据 (标签) 也能获得较好结果的方法.
“置信度控制” 是指根据应用的具体需求, 设置一个置信度 (现实情况不需要 100% 准确), 以此来控制学习过程.
将两者联合起来, 控制主动学习查询的数据、标签的数量, 满足给定一个置信度即可.
以前我做的一些论文与这个关系:
- Yan-Xue Wu, Xue-Yang Min, Fan Min, Min Wang. Cost-sensitive active learning with a label uniform distribution model. International Journal of Approximate Reasoning. 105(2019)49-65. 用查询代价、误分类代价来控制主动学习过程.
- Fan Min, Qing-Hua Hu, William Zhu, Feature selection with test cost constraint, International Journal of Approximate Reasoning. 55(1)(2014)167–179. 用测试代价约束, 优化属性选择效果. 将属性选择问题归结为约束满足问题 (Constraint satisfaction problem, CSP).
更多论文参见 http://www.fansmale.com/publications.html. 特别是主动学习方面.
















 1351
1351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









