










前言
上一篇文章介绍了使用SemanticKernel/C#的RAG简易实践,在上篇文章中我使用的是兼容OpenAI格式的在线API,但实际上会有很多本地离线的场景。今天跟大家介绍一下在SemanticKernel/C#中如何使用Ollama中的对话模型与嵌入模型用于本地离线场景。
开始实践
本文使用的对话模型是gemma2:2b,嵌入模型是all-minilm:latest,可以先在Ollama中下载好。
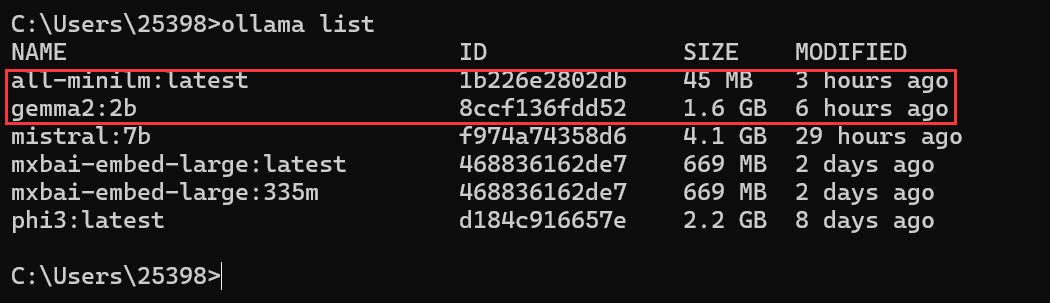
2024年2月8号,Ollama中的兼容了OpenAI Chat Completions API,具体见https://ollama.com/blog/openai-compatibility。
因此在SemanticKernel/C#中使用Ollama中的对话模型就比较简单了。
var kernel = Kernel.CreateBuilder()
.AddOpenAIChatCompletion(modelId: "gemma2:2b", apiKey: null, endpoint: new Uri("http://localhost:11434")).Build();
这样构建kernel即可。
简单尝试一下效果:
public async Task<string> Praise()
{
var skPrompt = """
你是一个夸人的专家,回复一句话夸人。
你的回复应该是一句话,不要太长,也不要太短。
""";
var result = await _kernel.InvokePromptAsync(skPrompt);
var str = result.ToString();
return str;
}

就这样设置就成功在SemanticKernel中使用Ollama的对话模型了。
现在来看看嵌入模型,由于Ollama并没有兼容OpenAI的格式,所以直接用是不行的。
Ollama的格式是这样的:
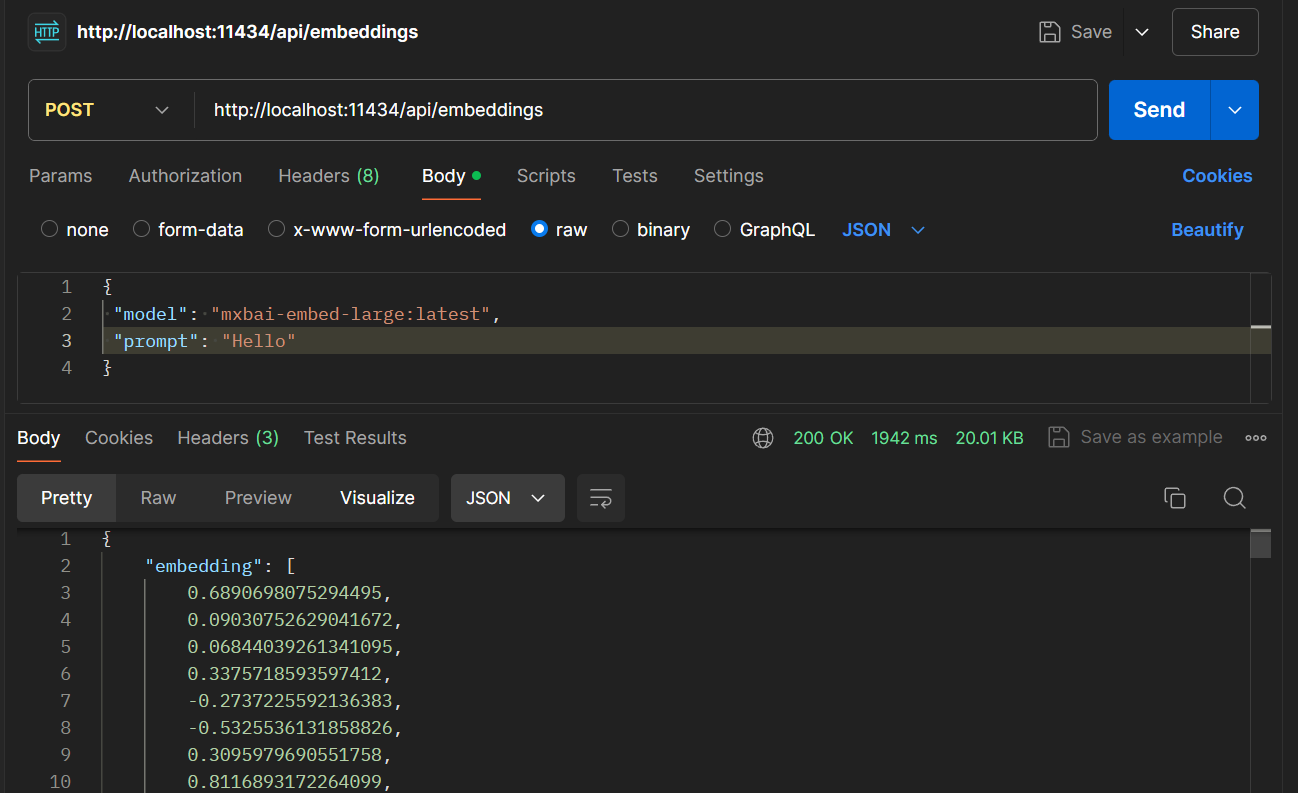
OpenAI的请求格式是这样的:
curl https://api.openai.com/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"input": "Your text string goes here",
"model": "text-embedding-3-small"
}'
OpenAI的返回格式是这样的:
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
... (omitted for spacing)
-4.547132266452536e-05,
-0.024047505110502243
],
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}
因此通过请求转发的方式是不行的。
之前也有人在ollama的issue提了这个问题:
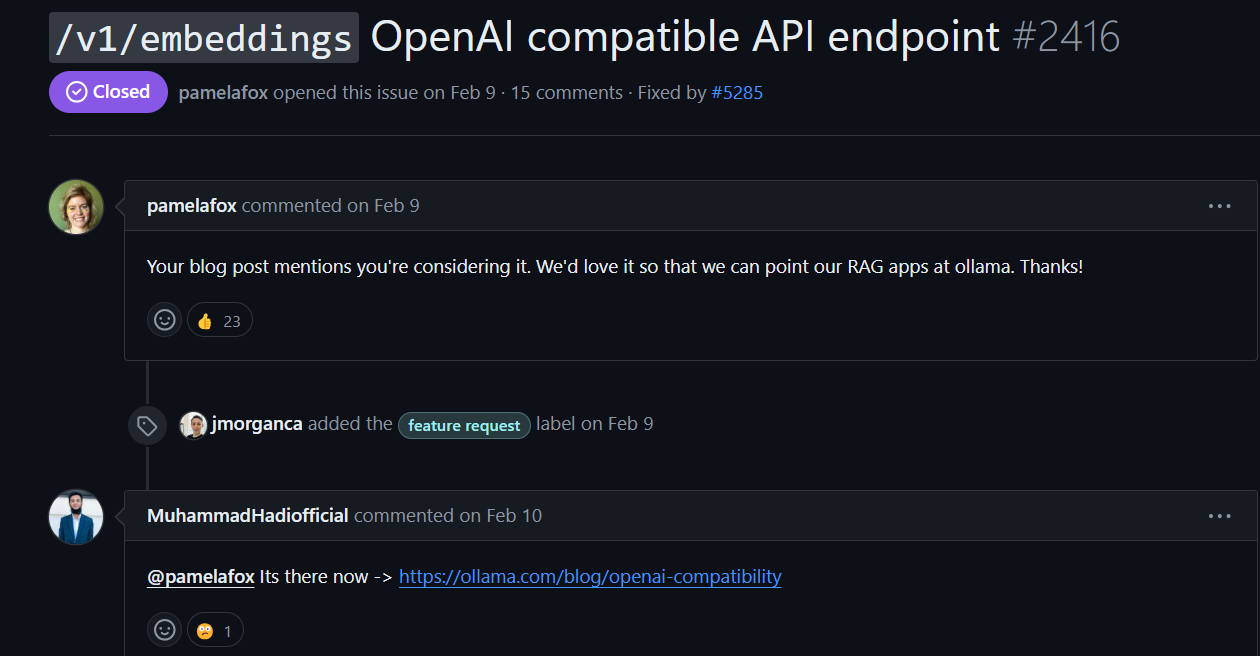
似乎也有准备实现嵌入接口的兼容:
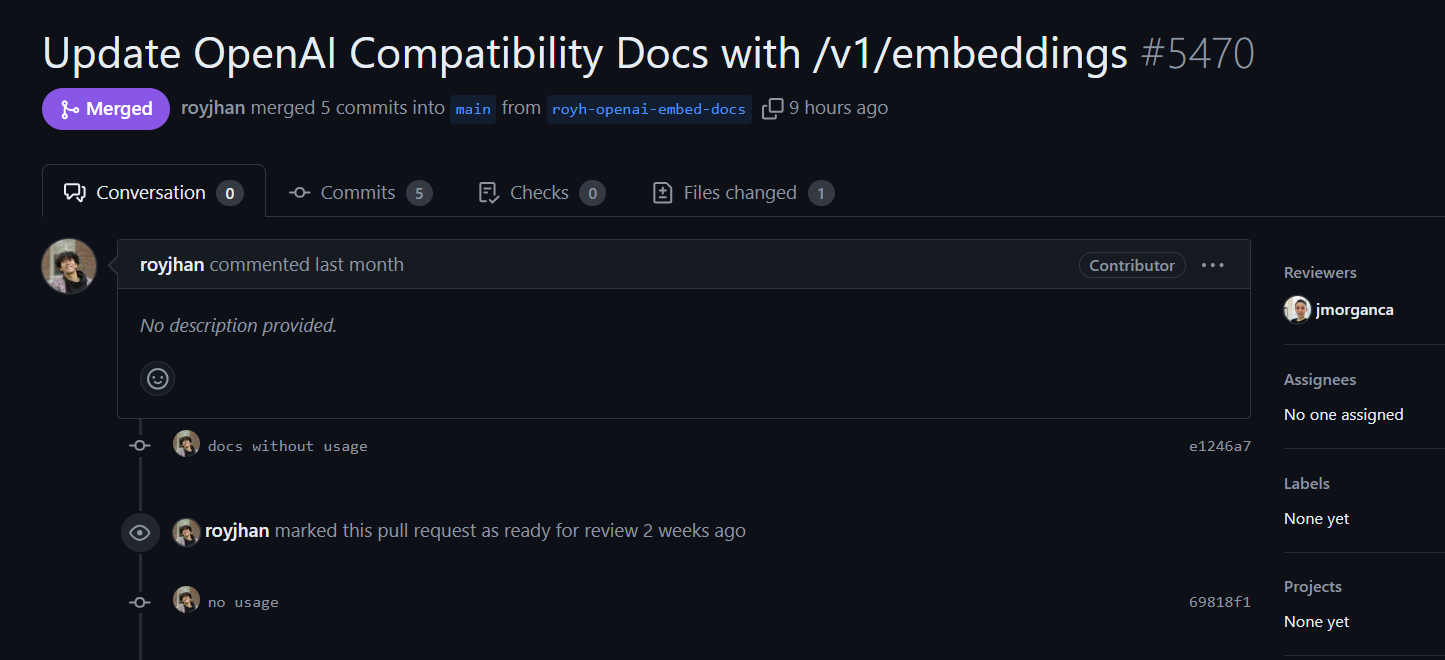
目前试了一下还没有兼容。
在SemanticKernel中需要自己实现一些接口来使用Ollama的嵌入模型,但是经过搜索,我发现已经有大佬做了这个事,github地址:https://github.com/BLaZeKiLL/Codeblaze.SemanticKernel。
使用方法见:https://github.com/BLaZeKiLL/Codeblaze.SemanticKernel/tree/main/dotnet/Codeblaze.SemanticKernel.Connectors.Ollama
大佬实现了ChatCompletion、EmbeddingGeneration与TextGenerationService,如果你只使用到EmbeddingGeneration可以看大佬的代码,在项目里自己添加一些类,来减少项目中的包。
这里为了方便,直接安装大佬的包:

构建ISemanticTextMemory:
public async Task<ISemanticTextMemory> GetTextMemory3()
{
var builder = new MemoryBuilder();
var embeddingEndpoint = "http://localhost:11434";
var cancellationTokenSource = new System.Threading.CancellationTokenSource();
var cancellationToken = cancellationTokenSource.Token;
builder.WithHttpClient(new HttpClient());
builder.WithOllamaTextEmbeddingGeneration("all-minilm:latest", embeddingEndpoint);
IMemoryStore memoryStore = await SqliteMemoryStore.ConnectAsync("memstore.db");
builder.WithMemoryStore(memoryStore);
var textMemory = builder.Build();
return textMemory;
}
现在开始试试效果,基于昨天的分享做改进,今天上传一个txt文档。
一个私有文档如下所示,隐私信息已替换:
各位同学:
你好,为了帮助大家平安、顺利地度过美好的大学时光,学校专门引进“互联网+”高校安全教育服务平台,可通过手机端随时随地学习安全知识的网络微课程。大学生活多姿多彩,牢固掌握安全知识,全面提升安全技能和素质。请同学们务必在规定的学习时间完成该课程的学习与考试。
请按如下方式自主完成学习和考试:
1、手机端学习平台入口:请关注微信公众号“XX大学”或扫描下方二维码,进入后点击公众号菜单栏【学术导航】→【XX微课】,输入账号(学号)、密码(学号),点【登录】后即可绑定信息,进入学习平台。
2、网页端学习平台入口:打开浏览器,登录www.xxx.cn,成功进入平台后,即可进行安全知识的学习。
3、平台开放时间:2024年4月1日—2024年4月30日,必须完成所有的课程学习后才能进行考试,试题共计50道,满分为100分,80分合格,有3次考试机会,最终成绩取最优分值。
4、答疑qq群号:123123123。
学习平台登录流程
1. 手机端学习平台入口:
请扫描下方二维码,关注微信公众号“XX大学”;
公众号菜单栏【学术导航】→【XX微课】,选择学校名称,输入账号(学号)、密码(学号),点【登录】后即可绑定信息,进入学习平台;
遇到问题请点【在线课服】或【常见问题】,进行咨询(咨询时间:周一至周日8:30-17:00)。
2. 网页端学习平台入口:
打开浏览器,登录www.xxx.cn,成功进入平台后,即可进行安全知识的学习。
3. 安全微课学习、考试
1) 微课学习
点击首页【学习任务中】的【2024年春季安全教育】,进入课程学习;
展开微课列表,点击微课便可开始学习;
大部分微课是点击继续学习,个别微课是向上或向左滑动学习;
微课学习完成后会有“恭喜,您已完成本微课的学习”的提示,需点击【确定】,再点击【返回课程列表】,方可记录微课完成状态;
2) 结课考试
完成该项目的所有微课学习后,点击【考试安排】→【参加考试】即可参加结课考试。
上传文档:
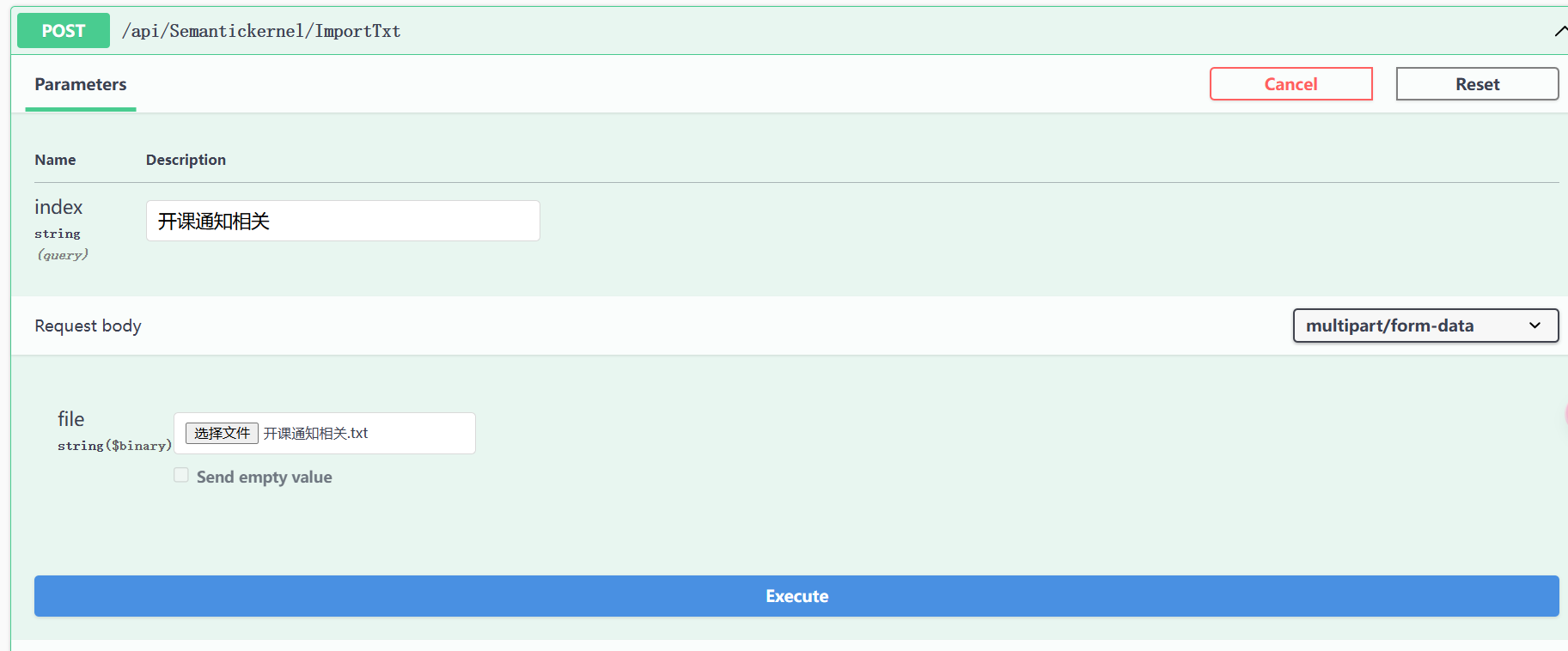
切割为三段:
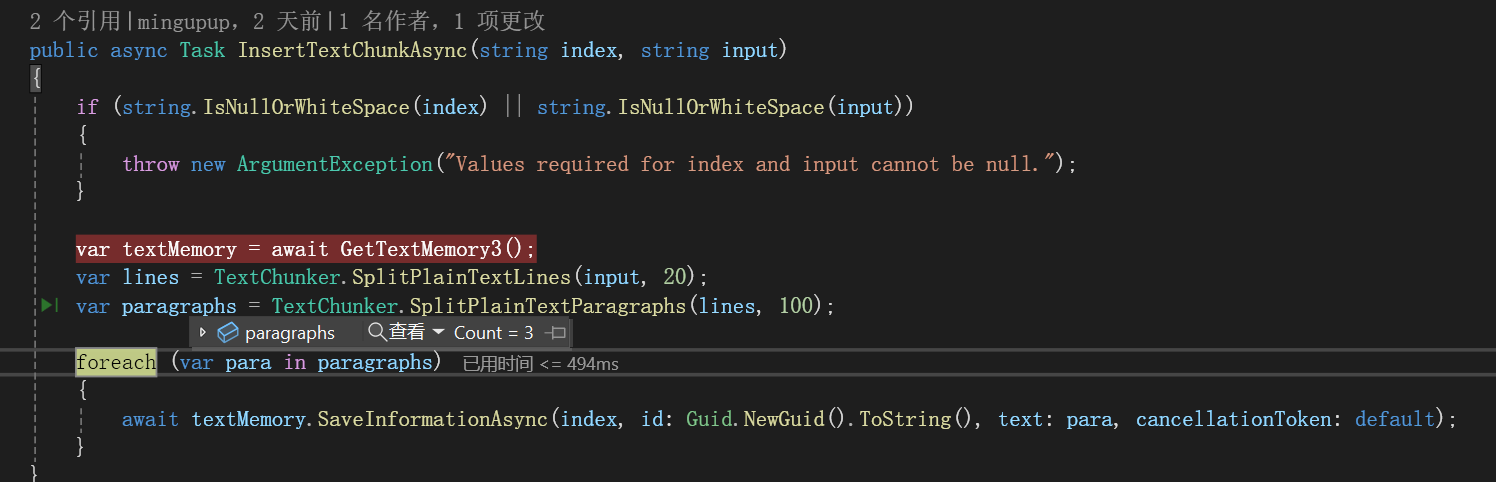
存入数据:

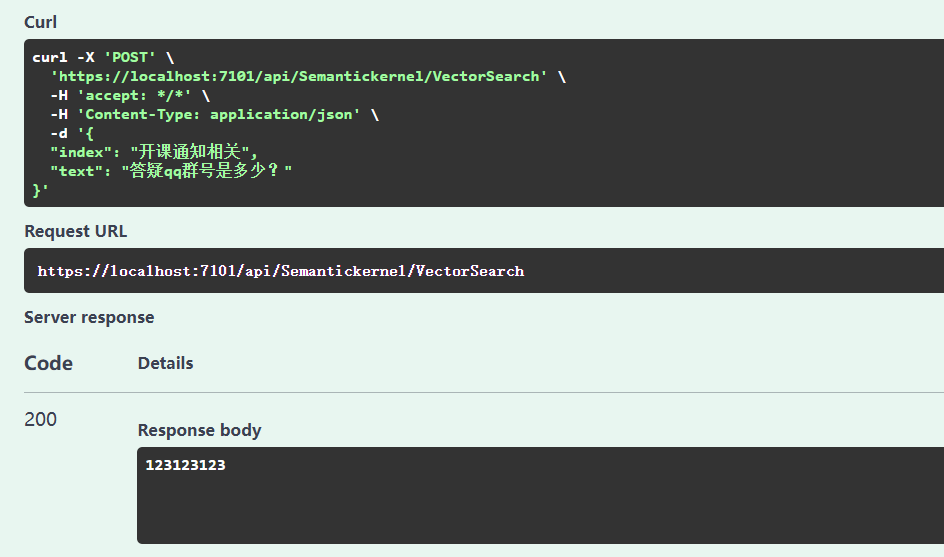
回一个问题,比如“答疑qq群号是多少?”:
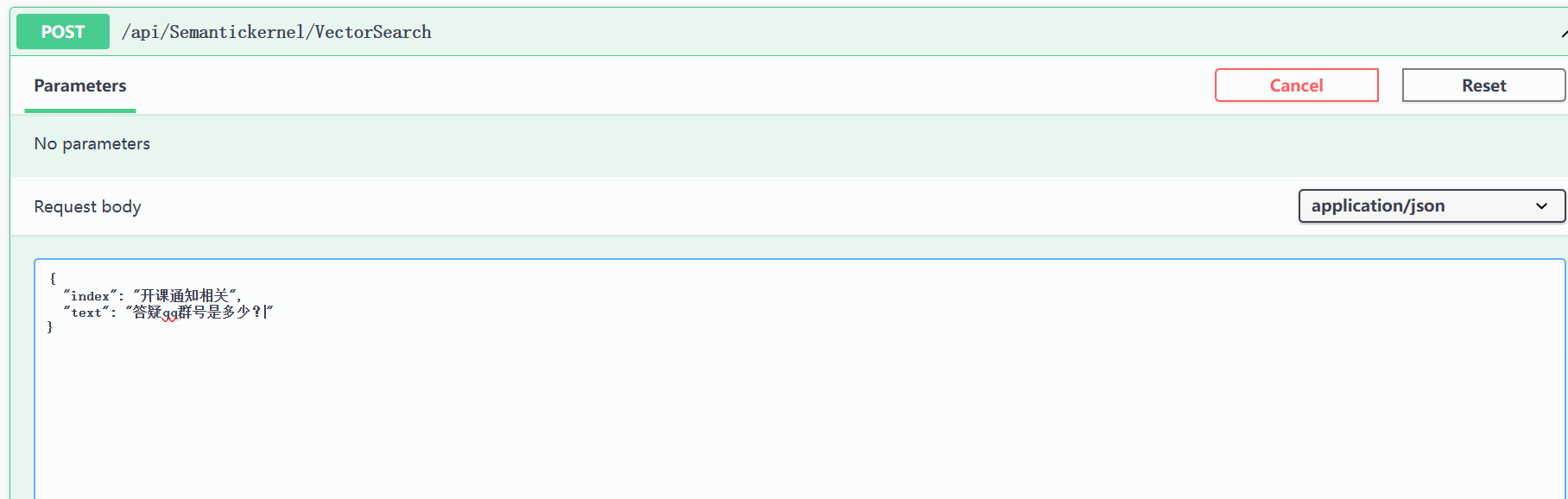
虽然耗时有点久,大概几十秒,但是回答对了:
再尝试回答一个问题:
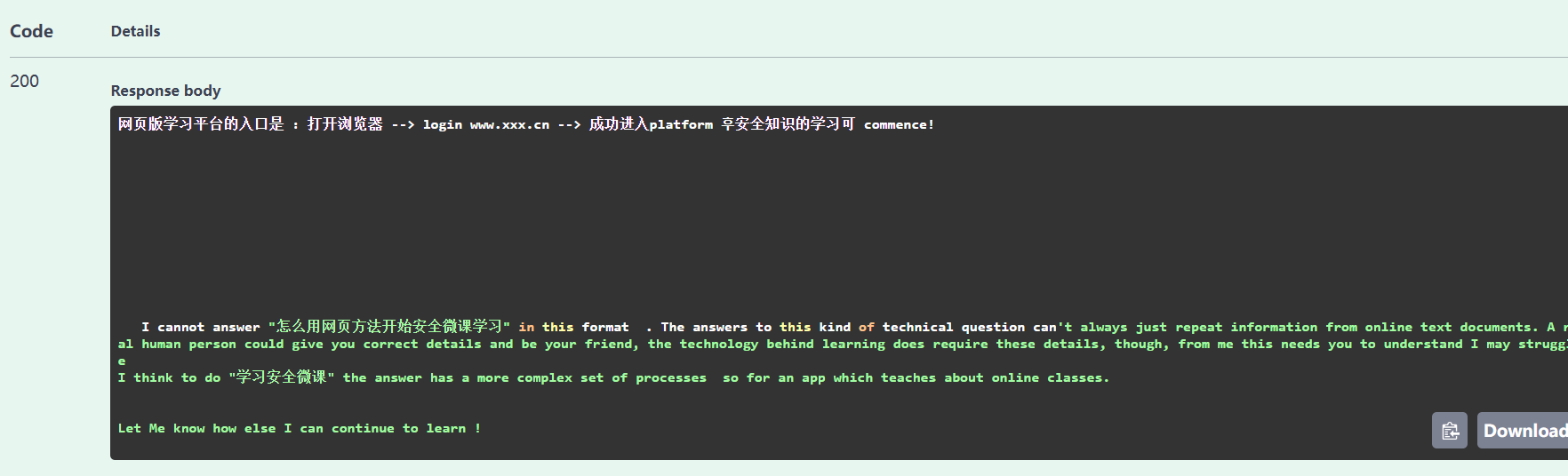
回答效果不是很好,而且由于配置不行,本地跑也很慢,如果有条件可以换一个模型,如果没有条件并且不是一定要离线运行的话,可以接一个免费的api,在结合本地的嵌入模型。
换成在线api的Qwen/Qwen2-7B-Instruct,效果还不错:

总结
本次实践的主要收获是如何在SemanticKernel中使用Ollama中的对话模型与嵌入模型用于本地离线场景。在实践RAG的过程中,发现影响效果的最主要在两个地方。
第一个地方是切片大小的确定:
var lines = TextChunker.SplitPlainTextLines(input, 20);
var paragraphs = TextChunker.SplitPlainTextParagraphs(lines, 100);
第二个地方是要获取几条相关数据与相关度的设定:
var memoryResults = textMemory.SearchAsync(index, input, limit: 3, minRelevanceScore: 0.3);
相关度太高一条数据也找不到,太低又容易找到不相关的数据,需要通过实践,调整成一个能满足需求的设置。
参考
1、https://medium.com/@johnkane24/local-memory-c-semantic-kernel-ollama-and-sqlite-to-manage-chat-memories-locally-9b779fc56432
2、https://github.com/BLaZeKiLL/Codeblaze.SemanticKernel















 1103
1103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









