






引言
在本教程中,我们将使用 JavaScript 和 Transformers 库来实现图像对象检测的功能。图像对象检测是计算机视觉领域中的重要任务,它可以识别图像中的不同对象并标注它们的位置。我们将使用一个预训练的对象检测模型,将其集成到网页中,通过上传图片来进行对象检测,并在图片上绘制边界框以标识检测到的对象。
一. 准备工作
首先,我们需要引入 Transformers 库,这是一个用于自然语言处理和计算机视觉任务的强大工具。我们将使用其中的对象检测模块来完成我们的任务。在代码中,我们通过 import {pipeline, env} from "https://cdn.jsdelivr.net/npm/@xenova/transformers@2.6.0"; 引入了所需的模块,pipeline和env模块来自于@xenova/transformers软件包的版本2.6.0。(注意:在导入pipeline和env模块时需要确保网络成功连接上了魔法)
二. HTML 结构
我们的 HTML 结构非常简单,只有一个文件上传 input 元素和一个用于显示图片和边界框的容器。文件上传 input 元素用于选择要检测的图片,而图片和边界框则会显示在 imageContainer 容器中,p标签将会显示交互信息提示用户图片读取状态。代码如下:
<main class="container">
<label for="file-upload" class="custom-file-upload">
上传图片
<input type="file" accept="image/*" id="file-upload">
</label>
<!-- #image-container div 标签不需要加前缀-->
<div id="image-container"></div>
<!-- p#status -->
<p id="status"></p>
</main>
三. JavaScript 实现
我们通过 JavaScript 实现了以下功能:
- 当用户选择了要检测的图片后,我们使用
FileReader对象读取图片文件,将图片解析成base64编码的字符串形式,并将该字符串赋值给img元素的src属性,这样读取到的文件就能显示在页面上。 - 然后,我们调用
detect函数,这个函数会启动 AI 任务,使用预训练的对象检测模型来检测图片中的对象。 - 在
detect函数中,我们使用pipeline函数初始化了一个对象检测器,并传入了我们选择的模型xenova/detr-resnet-50。其中,threshold参数设置了对象检测的置信度阈值,低于该阈值的检测结果将被忽略;percentage参数设置为true表示输出的边界框的坐标将以百分比形式返回。 - 检测完成后,我们会得到一个包含边界框和标签的输出,然后通过
renderBox函数将边界框绘制在图片上,并显示对象的标签。首先,它从传入的参数中获取边界框的坐标信息,并创建相应的<div>和<span>元素来表示边界框和标签。然后,它动态计算并设置边界框元素的样式,包括边框颜色、宽度、位置和尺寸等属性。最后,它将标签元素作为子元素添加到边界框元素中,并将边界框元素添加到页面上用于显示。 - 代码如下:
<script type="module">
// transformers nlp 任务
import {pipeline,env} from "https://cdn.jsdelivr.net/npm/@xenova/transformers@2.6.0";
env.allowLocalModels = false;
const fileUpload = document.getElementById('file-upload');
const imageContainer = document.getElementById('image-container')
fileUpload.addEventListener('change',function(e){
console.log(e.target.files[0]);
const file = e.target.files[0];
// 新建一个FileReader 对象 01 序列
// 图片比较大
const reader = new FileReader();
reader.onload = function(e2){
// 读完了 , 加载完成
const image = document.createElement('img'); // 图片对象
console.log(e2.target.result);
image.src = e2.target.result;
imageContainer.appendChild(image);
detect(image); // 启动ai任务 功能模块化,封装出去
}
reader.readAsDataURL(file);
})
const status = document.getElementById('status');
// 检测图片的AI任务
const detect = async (image) => {
status.textContent = "分析中...";
const detector = await pipeline("object-detection",
"xenova/detr-resnet-50"); // model 实例化了detector对象
const output = await detector(image.src,{
threshold : 0.1,
percentage : true
})
console.log(output);
output.forEach(renderBox);
}
function renderBox({box,label}){
console.log(box,label);
const {xmax,xmin,ymax,ymin} = box;
const boxElement = document.createElement("div");
boxElement.className = "bounding-box";
Object.assign(boxElement.style,{
borderColor : '#123123',
borderWidth : '1px',
borderStyle : 'solid',
left : 100 * xmin + '%',
top : 100 * ymin + '%',
width : 100 * (xmax - xmin) + '%',
height : 100 * (ymax - ymin) + '%'
})
const labelElement = document.createElement('span');
labelElement.textContent = label;
labelElement.className = "bounding-box-label";
labelElement.style.backgroundColor = '#000000';
boxElement.appendChild(labelElement);
imageContainer.appendChild(boxElement);
}
四. 总结
通过本教程,我们学习了如何使用 JavaScript 和 Transformers 库来实现图像对象检测的功能。我们使用了一个预训练的对象检测模型,并将其集成到网页中,通过简单的上传图片操作就能实现对象检测,并在图片上标注检测到的对象。这个示例展示了如何利用现有的工具和库来快速实现复杂的计算机视觉任务,为开发者提供了一种简单而有效的方法来处理图像数据。
五.运行效果


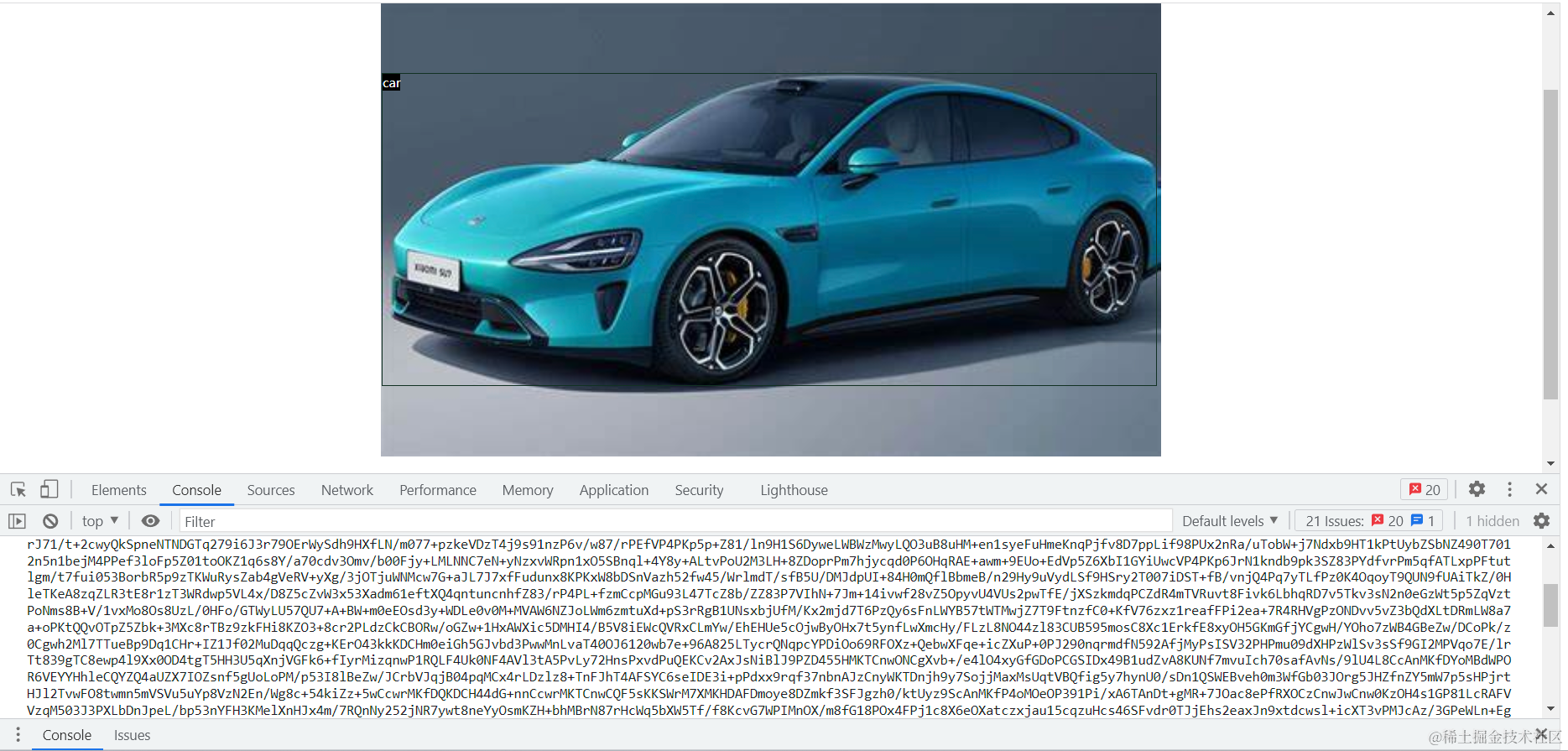
六.完整代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>nlp之图片识别,两种语言</title>
<style>
.container {
margin: 40px auto;
width: max(50vw, 400px);
display: flex;
flex-direction: column;
align-items: center;
}
.custom-file-upload {
display: flex;
align-items: center;
cursor: pointer;
gap:10px;
border: 2px solid black;
padding: 8px 16px;
border-radius: 6px;
}
#file-upload {
display: none;
}
#image-container {
width: 100%;
margin-top:20px;
position: relative;
}
#image-container>img {
width: 100%;
}
.bounding-box {
position: absolute;
box-sizing: border-box;
}
.bounding-box-label {
position: absolute;
color: white;
font-size: 12px;
}
</style>
</head>
<body>
<!-- 语义化 main就比div 更好 页面中的主体内容 -->
<!-- css 选择器 -->
<!-- main.container>label.custom-file-upload>input#file-upload -->
<main class="container">
<label for="file-upload" class="custom-file-upload">
上传图片
<input type="file" accept="image/*" id="file-upload">
</label>
<!-- #image-container div 标签不需要加前缀-->
<div id="image-container"></div>
<!-- p#status -->
<p id="status"></p>
</main>
<script type="module">
// transformers nlp 任务
import {pipeline,env} from "https://cdn.jsdelivr.net/npm/@xenova/transformers@2.6.0";
env.allowLocalModels = false;
const fileUpload = document.getElementById('file-upload');
const imageContainer = document.getElementById('image-container')
fileUpload.addEventListener('change',function(e){
console.log(e.target.files[0]);
const file = e.target.files[0];
// 新建一个FileReader 对象 01 序列
// 图片比较大
const reader = new FileReader();
reader.onload = function(e2){
// 读完了 , 加载完成
const image = document.createElement('img'); // 图片对象
console.log(e2.target.result);
image.src = e2.target.result;
imageContainer.appendChild(image);
detect(image); // 启动ai任务 功能模块化,封装出去
}
reader.readAsDataURL(file);
})
const status = document.getElementById('status');
// 检测图片的AI任务
const detect = async (image) => {
status.textContent = "分析中...";
const detector = await pipeline("object-detection",
"xenova/detr-resnet-50"); // model 实例化了detector对象
const output = await detector(image.src,{
threshold : 0.1,
percentage : true
})
console.log(output);
output.forEach(renderBox);
}
function renderBox({box,label}){
console.log(box,label);
const {xmax,xmin,ymax,ymin} = box;
const boxElement = document.createElement("div");
boxElement.className = "bounding-box";
Object.assign(boxElement.style,{
borderColor : '#123123',
borderWidth : '1px',
borderStyle : 'solid',
left : 100 * xmin + '%',
top : 100 * ymin + '%',
width : 100 * (xmax - xmin) + '%',
height : 100 * (ymax - ymin) + '%'
})
const labelElement = document.createElement('span');
labelElement.textContent = label;
labelElement.className = "bounding-box-label";
labelElement.style.backgroundColor = '#000000';
boxElement.appendChild(labelElement);
imageContainer.appendChild(boxElement);
}
</script>
</body>
</html>

















 299
299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











