







chapter.3 – 表、栈、队列
这一章讨论了最基本的三种数据结构,实际上,每一个有意义的程序都将显式的至少使用一种这样的数据结构,而不管我们在程序中声明与否,栈在程序中总是被间接地用到。
抽象数据类型(abstract data structure ,ADT) :是一些自带操作功能的对象的集合,而在其定义中并未说明这些操作是如何实现的,对于我们来说并不知道这些操作功能的实现细节。这些操作功能有添加(add)、移除(remove)、包含(contains),也可以只有并(union)、查找(find)这两种操作,这两种操作定义了一种不同的ADT。
用简单数组实现表结构,代码如下
int[] arr = new int[10]; // 数组的初始长度默认为10
...
// 下面我们扩大数组为原来的2倍大小
int[] newArr = new int[arr.length * 2];
...
for ( int i = 0; i < arr.length; i++ ) {
newArr[i] = arr[i];
}
arr = newArr;
我们知道,Java中当创建一个数组的时候,我们需要为数组指定初始长度,但是在现代编码中,数组创建时并不需要就为其指定一个大小,因为在需要的时候完全可以按照以上的方式进行扩充。
链表实现
在数组中进行插入、删除操作时,最坏的情况我们考虑删除数组的第一个元素,那么后面的所有元素都要前移一位;而在数组的最前端插入,则所有元素均需后移一位,这两种情况对应的时间是O(N) ,所以平均情形的时间复杂度也要O(N/2) 。对于这个问题,链表就提供了很好地解决。
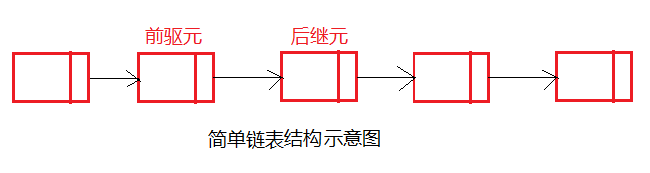
链表有一系列的节点组成,每个节点包含两部分,本身存储的数据和下一个节点的地址值,前面相邻节点后后面节点的前驱元,后面相邻节点是前面节点的后继元,示意图如下
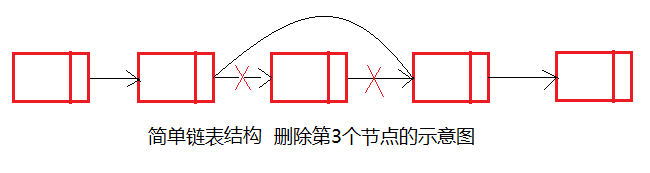
remove()方法可以通过修改对下一个节点地址值的引用来删除节点,下图说明删除链表删除索引为3的元素的情形
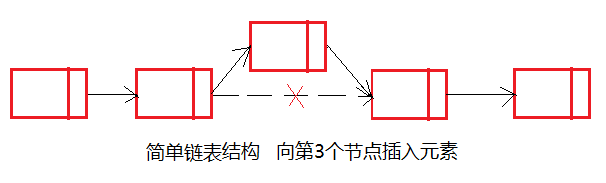
insert()方法则可以从系统取得一个新节点,再通过对地址值的两次新引用来实现新节点的插入,示意图如下
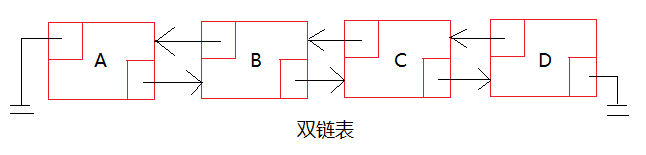
让每个节点持有一个指向它在表中的前驱节点的地址值,这样的链表叫做“双链表”,示意图如下
Java Collections API 也实现了表结构,Collections API 在java.util包中,集合的概念在Collection中得以抽象,用来存储一组类型相同的对象,Java集合框架的主要方法及其功能如下所示
int size()---->返回集合大小,也即集合中的项数
boolean isEmpty()---->判断集合是否为空集合,返回true表示空集合,返回false表示集合非空
void clear()---->清空所有的集合元素
boolean contains(AnyType x)---->判断集合中是否存在元素x
boolean add(AnyType x)---->向集合中添加元素x
boolean remove(AnyType x)---->移除集合元素x
java.util.Iterator<AnyType> iterator()---->构造集合元素迭代器对象
另外,如果想用增强for来遍历集合所有的元素,则该集合独享需要实现Iterator接口,Iterator接口有三个比较重要而方法,如下
boolean hasNext();---->判断集合是否有下一个元素
AnyType next();---->返回集合的下移一位元素
void remove();---->移除由next()返回的元素
实现Iterator接口的思路很简单,因为Collection集合类是默认实现Iterator接口的,只要调用iterator()方法,就会返回一个Iterator接口的对象,在对象内部可以存储当前位置,所以通过该对象就可以遍历集合元素并把他们打印出来,代码如下
public static <AnyType> void print(Collection<AnyType> coll) {
for (AnyType item : coll) {
System.out.println(item);
}
}
当编译器发现一个用于Iterator对象的for循环后,会创建一个Iterator对象来代替增强for循环对iterator方法的调用,然后再调用next()和hasNext() ,因此上面的循环遍历被编译器重写后代码如下所示
public static <AnyType> void print(Collection<AnyType> coll) {
Iterator<AnyType> itr = coll.iterator();
while (itr.hasNext()) {
AnyType item = itr.next();
System.out.println(item);
}
}
由于Iterator接口包含的方法极为有限,因此只能堆积和做简单的遍历工作,但是使用Iterator遍历集合的效率会更高。另外,Iterator接口的remove()方法不同于Collection接口的remove()方法,当我们使用Collection接口的remove()方法删除元素时需要先找到被删除元素的精确位置,而Iterator接口的remove()方法删除的是next()方法返回的集合元素,不需要给被删除元素定位。当直接使用Iterator接口时需要记住一个重要的法则:如果正在被迭代的集合在结构上发生改变,这种改变包括山春元素、插入元素等操作,那么迭代器就不再合法。如果继续使用将会抛出ConcurrentModificationException异常。这意味着,只有在我们需要立即使用迭代器的时候才去获取一个迭代器的对象。
Java中表(list) 由java.util包中的List接口指定,List接口继承了Collection接口,因此包含Collection接口的所有方法,另外既然是Collection接口的实现接口,那么它就肯定有自己独有的方法,下面列出了List接口独有的方法,代码如下
AnyType get(int idx);访问并返回索引为idx的项
AnyType set(int idx, AnyType newVal);将索引为idx位置的项替换为newVal
void add(int idx, AnyType x);在索引为idx的位置插入一个新元素x ,并把后面的所有元素后移一位
void remove(int idx);删除指定索引位置的元素
ArrayList集合类和LinkedList集合类是List接口最常用的两个实现类。ArrayList类提供了List接口的一种可增长数组实现,使用ArrayList的优点在于调用其get()、set()只需要花费乘数时间,这也就是说对ArrayList集合进行查询很快,相反,对其进行现有项的删除或者新项的插入却代价昂贵,在ArrayList的末端插入、删除还好,如果在ArrayList的前端插入、删除则需要变动后面的所有项;LinkedList类提供了List接口的双链表实现,使用LinkedList的优点在于现有项的删除或者新项的插入开销很小,但这意味着在表的前端插入、删除操作都是常数时间,因此LinkedList类提供了addFirst()、removeFirst()、addLast()、removeLast()、以及getFirst()、getLast()等方法可以很方便的对表的前端和后端进行相应的操作,其缺点是不容易作索引,因此get()、set()方法的使用代价是昂贵的。下面我们通过在末端添加一些项来构造一个List , 代码如下
public static void makeList1(List<Integer> lst, int n) {
lst.clear();
for (int i = 0; i<n; i++) {
lst.add(i);
}
}
对比上面在表的末端添加一些项来构造List , 不管接收的参数是ArrayList也好,还是LinkedList也好,运行时间都是常数时间。下面的代码是从表的前端添加一些项来构造一个List,看如下代码
public static void makeList2(List<Integer> lst, int n) {
lst.clear();
for (int i = 0; i<n; i++) {
lst.add(0, i);
}
}
当从表前端添加一些项来构造一个List的时候,对于LinkedList是常数时间O(N) 。而对于ArrayList运行时间则是O(N^2) ,因为在ArrayList前端添加操作占用一个O(N) ,而后面所有项的后移也是一个O(N) 。
对搜索而言,ArrayList和LinkedList都是低效的。它们重写的Collection的contains()方法都需要占用线性时间。ArrayList基础数组的大小表示它的容量,在需要的时候,ArrayList可以自动增加容量以保证它至少具有表的大小。如果该表大小在创建ArayList的时候可以预估,就可以用ensureCapacity设置一个足够大的ArrayList容量以避免数组容量以后的扩展。再有,trimToSize可以在所有的ArrayList添加操作完成之后使用,避免浪费空间。
一个简单的例子,删除一张随机表中所有的偶数项。一个最佳的方案代码如下
public static void removeEvensVer(List<Integer> lst) {
Iterator<Integer> itr = lst.iterator();
while (itr.hasNext()) {
if (itr.next() % 2 == 0) {
itr.remove();
}
}
}
如果我们传入一个LinkedList参数,则花费线性时间;如果传入的是一个ArrayList参数,则花费的是二次时间。
ArrayList的迭代器实现细节如下
public class MyArrayList<AnyType> implements Itertor<AnyType> {
private int theSize;
private AnyType[] theItems;
...
public java.util.Iterator<AnyType> iterator() {
return new ArrayLiastIterator();
}
private class ArrayListIterator implements java.util.Iterator<AnyType> {
private int current = 0;
public boolean hasNext() {
return current < size();
}
public AnyType next() {
return theItems[current++];
}
public void remove() {
MyArrayList.this.remove(--current);
}
}
}
LinkedList的迭代器的实现细节如下
private class LinkedListIterator implements java.util.Iterator<AnyType> {
private Node<AnyType> current = beginMarker.next();
private int exceptedModCount = modCount;
private boolean okToRemove = false;
public boolean hasNext() {
return current != endMarker;
}
public AnyType next() {
if (modCount != exceptedModCount) {
throw new java.util.ConcurrentModficationException();
}
if (!hasNext()) {
throw new java.util.NoSuchElementException();
}
AnyType nextItem = current.data;
current = current.next();
okToRemove = true;
return nextItem;
}
public void remove() {
if (modCount != exceptedModCount) {
throw new java.util.ConcurrentModficationException();
}
if (!okToRemove) {
throw new IllegalStateException();
}
MyLinkedList.this.remove(current.prev);
okToRemove = false;
exceptedModCount++;
}
}
栈ADT,限制插入、删除操作只能在一个位置上进行的表,该位置是表的末端,叫做栈顶(stack top),有时又叫做后进先出表。栈的基本操作有入栈(push),相当于插入;出栈(pop),相当于删除最后入栈的元素。对空栈进行pop或者top操作被认为是栈ADT的一个错误,另一方面,当push时栈空间用尽是一个实现限制,但不是ADT错误。一般栈的抽象模型是存在某个元素位于栈顶并且该元素是栈中唯一可见的元素。下面是一个栈应用的实例。
编译器检验程序的语法错误。实现思路是做一个空栈,读入字符直到文件结尾,如果一个字符是开放符号(例如左括号)则将其推入栈中,如果字符是一个封闭符号(例如右括号)则当栈空时报错,否则将元素弹出,如果弹出的符号不是对应的开放符号则报错,在文件结尾如果栈非空则报错。
队列(queue)ADT,也是一种表结构,然而与栈ADT不同,队列的插入在一端进行而删除在另一端进行。队列的基本操作是入队(enqueue),在队尾(rear)即表的末端插入一个元素;出队(dequeue),即删除并返回在队头(front)即表开头的元素。
写到这第三张终于学完啦!看看弟弟寒假作业上的一首好诗,我贴在这里当做结语吧!
荷尽已无擎雨盖,菊残犹有傲霜枝。一年好景君须记,正是橙黄橘绿时。















 415
415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









