









目录
第一部分
全球城市计算AI挑战赛总决赛
这个部分是自己在看决赛视频时,觉得印象深刻 值得学习借鉴的点。
1. 赛题背景
- 分析地铁站的历史刷卡数据,预测站点未来客流量变化,挖掘出行规律
- 提供2019.1.1-2019.1.25共81个站点的刷卡数据记录,以及路网地图(邻接关系),预测未来一天各站点的逐十分钟累积进出站人次
- A榜测试集:增加28日为训练集,预测29日;B榜测试集:增加26日为训练集,预测27日;C榜测试集:增加30日为训练集,预测31日;
2. EDA
答辩人2:(25min左右)
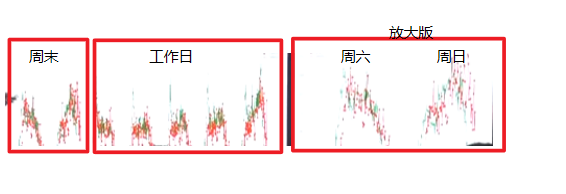
- 周末(图中前两簇)与工作日(图中后五簇)的流量差异,与站点类型有关 ,办公属性站点差异较大,旅游属性站点差异较小。所以纯粹以周末或非周末作为区分,可能不太合理

- 城际客流的“潮汐效应”,火车站站点的周六和周日流量会存在镜像分布的特点,就比如周六到火车站乘火车,周日乘火车返回再经过地铁回家。(注:周一和周五也存在类似特点)
答辩人5:(90min左右)
- 根据各站点在工作日早晚高峰的出站入站数,判断站点类型。如(1)工作日晚高峰入站形成波峰的站点被判定为工作地;(2)工作日早高峰入站形成波峰的站点被判定为居住地;(3)周末出入站人流远超于工作日人流的站点被判定为休闲娱乐地
3. 特征工程
答辩人1:
- 时间特征:星期/小时/分钟;是否周末;距离春节还有几天
- 流量特征(历史信息):前两天同时段流量;前两天同时段前后两小时逐十分钟流量;历史所有星期 x x x (要预测的星期 x x x)同时段逐小时流量均值;历史同时段逐十分钟流量均值
- 站点特征:站点id;站点闸机数;站点连接数;站点位置(类似POI 点,结果表示比较有效)
注:有一个未用的特征值得学习,作者可视化了入站出站的时间对应关系,比如7点入站的人对应出站时间的概率分布(结果显示比较集中);12点入站的人对应出站时间的概率分布(结果显示比较分散);18点入站的人对应出站时间的概率分布(结果显示比较集中)。
这个怎么用,作者说比如要预测今天早上7点的入站人次,将昨天晚上18点的出站特征加到现有的特征集中。
答辩人2:

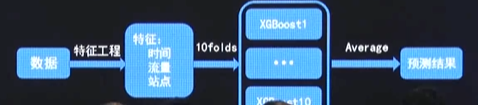
4. 模型训练
答辩人1: 重特征工程,轻模型。
第二部分
TIANCHI-全球城市计算挑战赛-完整方案及关键代码分享(季军)
本部分是季军团队的思路笔记和代码笔记
1. 前言
An AI compute of cities based on Distributed-Platform and Distributed-Databases(天池地铁流量预测)
大框架的赛题背景不再赘述,见前一部分的第1节,本节主要是细节分析。
1.1 训练数据
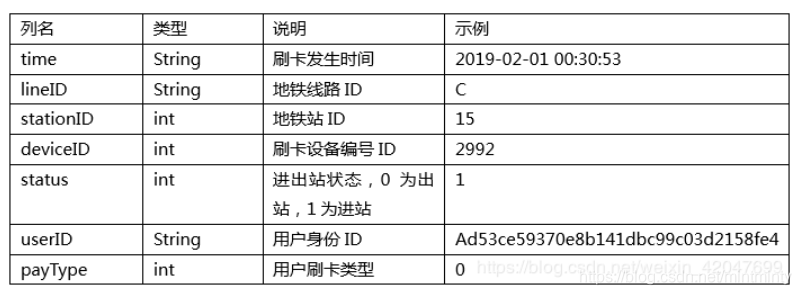
- 训练数据(Metro_train.zip)解压后可以得到25个csv文件,每天的刷卡数据均单独存在一个csv文件中。
- 具体数据包含:
1.2 预测数据
三种预测模式:
- A:提供2019年1月28日(周一)的刷卡数据,需对2019年1月29日(周二)全天各地铁站以10分钟为单位的人流量进行预测。
- B:提供2019年1月26日(周六)的刷卡数据,需对2019年1月27日(周日)全天各地铁站以10分钟为单位的人流量进行预测。
- C:提供2019年1月30日(周三)的刷卡数据,需对2019年1月31日(周四)全天各地铁站以10分钟为单位的人流量进行预测。
2. 特征工程
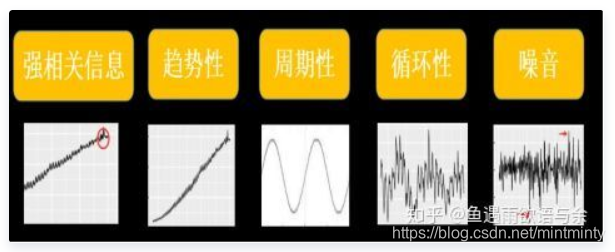
2.1 强相关性信息

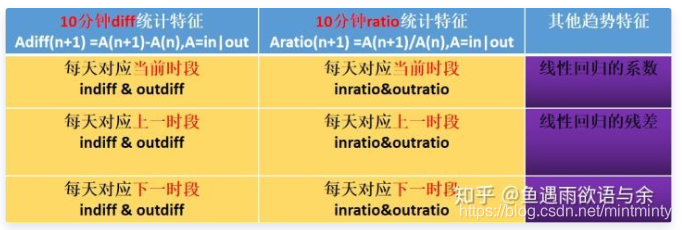
2.2 趋势性
- 前后时段的差值 A − d i f f ( n + 1 ) = A ( n + 1 ) − A ( n ) , A = i n ∣ o u t A_{-} d i f f(n+1)=A(n+1)-A(n), A=i n \mid out A−diff(n+1)=A(n+1)−A(n),A=in∣out 在这里既可以是出站流量,也可以是入站流量
- 前后时段的差比
A
−
ratio
(
n
+
1
)
=
A
(
n
+
1
)
/
A
(
n
)
,
A
=
in
∣
out
A_{-} \text {ratio}(n+1)=A(n+1) / A(n), A=\text {in } \mid \text { out }
A−ratio(n+1)=A(n+1)/A(n),A=in ∣ out
2.3 周期性

2.4 stationID 相关特征
挖掘不同站点及站点与其他特征组合的热度
(待更新)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









