







 本文档详细介绍了如何使用Ansible-playbook来部署ELFK(Elasticsearch, Logstash, Filebeat, Kibana)集群。首先,需要准备所有组件的旧版本并创建主机分组。然后,针对每个组件(如Java、Elasticsearch、Logstash、Filebeat、Kibana、Head和Nginx),创建入口文件,定义变量,创建模板文件,并配置相应的服务文件。最后,进行安装测试,确保集群部署成功。建议在部署前预先下载所需安装包,并保持ELFK组件的版本一致性。"
9751661,1425655,游戏与编程:最长连续序列,"['算法', '数据结构', '哈希表']
本文档详细介绍了如何使用Ansible-playbook来部署ELFK(Elasticsearch, Logstash, Filebeat, Kibana)集群。首先,需要准备所有组件的旧版本并创建主机分组。然后,针对每个组件(如Java、Elasticsearch、Logstash、Filebeat、Kibana、Head和Nginx),创建入口文件,定义变量,创建模板文件,并配置相应的服务文件。最后,进行安装测试,确保集群部署成功。建议在部署前预先下载所需安装包,并保持ELFK组件的版本一致性。"
9751661,1425655,游戏与编程:最长连续序列,"['算法', '数据结构', '哈希表']
通过ansible-playbook,部署ELFK集群。
java安装目录: /usr/local/jdk
elasticsearch安装目录: /home/elfk/elasticsearch
logstash安装目录: /home/elfk/logstash
filebeat安装目录: /home/elfk/filebeat
kibana安装目录: /home/elfk/kibana
elasticsearch-head安装目录: /home/elfk/head
nginx安装目录: /usr/local/nginx
下载elfk各组件的旧版本:
https://www.elastic.co/downloads/past-releases
准备
- 将所有部署elfk的主机分组:
# vim /etc/ansible/hosts
[elasticsearch]
192.168.30.128
192.168.30.129
192.168.30.130
[logstash]
192.168.30.131
192.168.30.132
192.168.30.133
[filebeat]
192.168.30.131
192.168.30.132
[kibana]
192.168.30.133
- 创建管理目录:
# mkdir -p elfk/roles/{java_install,elasticsearch_install,logstash_install,filebeat_install,kibana_install,head_install,nginx_install}/{files,handlers,meta,tasks,templates,vars}
# cd elfk/
说明:
files:存放需要同步到异地服务器的源码文件及配置文件;
handlers:当资源发生变化时需要进行的操作,若没有此目录可以不建或为空;
meta:存放说明信息、说明角色依赖等信息,可留空;
tasks:ELFK 安装过程中需要进行执行的任务;
templates:用于执行 ELFK 安装的模板文件,一般为脚本;
vars:本次安装定义的变量
提前下载好elfk各个tar包,放至对应的files目录下。
# tree .
.
├── elfk.yml
└── roles
├── elasticsearch_install
│ ├── files
│ │ └── elasticsearch-6.7.1.tar.gz
│ ├── handlers
│ ├── meta
│ ├── tasks
│ │ ├── copy.yml
│ │ └── main.yml
│ ├── templates
│ │ ├── elasticsearch
│ │ ├── elasticsearch.conf
│ │ └── elasticsearch.service
│ └── vars
│ └── main.yml
├── filebeat_install
│ ├── files
│ │ └── filebeat-6.7.1-linux-x86_64.tar.gz
│ ├── handlers
│ ├── meta
│ ├── tasks
│ │ ├── copy.yml
│ │ ├── main.yml
│ │ └── prepare.yml
│ ├── templates
│ │ └── filebeat.service
│ └── vars
│ └── main.yml
├── head_install
│ ├── files
│ ├── handlers
│ ├── meta
│ ├── tasks
│ │ ├── copy.yml
│ │ ├── install.yml
│ │ └── main.yml
│ ├── templates
│ │ ├── elasticsearch-head
│ │ └── node_PATH
│ └── vars
│ └── main.yml
├── java_install
│ ├── files
│ │ └── jdk-8u191-linux-x64.tar.gz
│ ├── handlers
│ ├── meta
│ ├── tasks
│ │ ├── copy.yml
│ │ ├── main.yml
│ │ └── prepare.yml
│ ├── templates
│ │ ├── java_PATH
│ │ └── limits.conf
│ └── vars
│ └── main.yml
├── kibana_install
│ ├── files
│ │ ├── kibana-6.7.1-linux-x86_64.tar.gz
│ │ └── Kibana_Hanization-master.zip
│ ├── handlers
│ ├── meta
│ ├── tasks
│ │ ├── chinesization.yml
│ │ ├── copy.yml
│ │ ├── main.yml
│ │ └── prepare.yml
│ ├── templates
│ │ ├── kibana
│ │ ├── kibana.conf
│ │ └── kibana.service
│ └── vars
│ └── main.yml
├── logstash_install
│ ├── files
│ │ └── logstash-6.7.1.tar.gz
│ ├── handlers
│ ├── meta
│ ├── tasks
│ │ ├── copy.yml
│ │ ├── main.yml
│ │ └── prepare.yml
│ ├── templates
│ │ ├── logstash
│ │ ├── logstash.conf
│ │ └── logstash.service
│ └── vars
│ └── main.yml
└── nginx_install
├── files
├── handlers
├── meta
├── tasks
│ ├── copy.yml
│ ├── install.yml
│ ├── main.yml
│ └── prepare.yml
├── templates
│ ├── fastcgi_params
│ ├── kibana.conf
│ ├── nginx.conf
│ └── nginx.service
└── vars
└── main.yml
50 directories, 54 files
- 创建安装入口文件,用来调用roles:
# vim elfk.yml
---
- hosts: elasticsearch
remote_user: root
gather_facts: True
roles:
- java_install
- elasticsearch_install
- hosts: logstash
remote_user: root
gather_facts: True
roles:
- java_install
- logstash_install
- hosts: filebeat
remote_user: root
gather_facts: True
roles:
- filebeat_install
- hosts: kibana
remote_user: root
gather_facts: True
roles:
- kibana_install
- head_install
- nginx_install
java部分
- 创建java入口文件,用来调用java_install:
# vim java.yml
#用于批量安装Java
- hosts: elasticsearch
remote_user: root
gather_facts: True
roles:
- java_install
- 创建变量:
# vim roles/java_install/vars/main.yml
#定义java安装中的变量
JAVA_VER: 191
SOURCE_DIR: /software
JAVA_DIR: /usr/local/jdk
- 创建模板文件:
环境变量java_PATH
# vim roles/java_install/templates/java_PATH
JAVA_HOME={{ JAVA_DIR }}
PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib
export JAVA_HOME PATH CLASSPATH
系统环境limits.conf
# vim roles/java_install/templates/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
- 环境准备prepare.yml:
# vim roles/java_install/tasks/prepare.yml
- name: 关闭firewalld
service: name=firewalld state=stopped enabled=no
- name: 临时关闭 selinux
shell: "setenforce 0"
failed_when: false
- name: 永久关闭 selinux
lineinfile:
dest: /etc/selinux/config
regexp: "^SELINUX="
line: "SELINUX=disabled"
- name: 添加EPEL仓库
yum: name=epel-release state=latest
- name: 安装常用软件包
yum:
name:
- vim
- lrzsz
- net-tools
- wget
- curl
- bash-completion
- rsync
- gcc
- unzip
- git
state: latest
- name: 更新系统
shell: "yum update -y"
ignore_errors: yes
args:
warn: False
- 文件拷贝copy.yml:
# vim roles/java_install/tasks/copy.yml
- name: 拷贝系统环境limits.conf
template: src=limits.conf dest={{ SOURCE_DIR }} owner=root group=root
- name: 配置系统环境limits.conf
shell: "if [ `grep '* soft nofile 65536' /etc/security/limits.conf |wc -l` -eq 0 ]; then cat {{ SOURCE_DIR }}/limits.conf >> /etc/security/limits.conf; fi"
- name: 配置系统环境
shell: "if [ `grep 'vm.max_map_count' /etc/sysctl.conf |wc -l` -eq 0 ]; then echo 'vm.max_map_count=655360' >> /etc/sysctl.conf && sysctl -p; fi"
- name: 创建software目录
file: name={{ SOURCE_DIR }} state=directory recurse=yes
#当前主机files目录下要准备好jdk包
- name: 拷贝jdk包
copy: src=jdk-8u{{ JAVA_VER }}-linux-x64.tar.gz dest={{ SOURCE_DIR }} owner=root group=root
- name: 解压jdk包
shell: "tar zxf jdk-8u{{ JAVA_VER }}-linux-x64.tar.gz"
args:
chdir: "{{ SOURCE_DIR }}"
warn: False
- name: 目录重命名
shell: "if [ ! -d {{ JAVA_DIR }} ]; then mv {{ SOURCE_DIR }}/jdk1.8.0_{{ JAVA_VER }}/ {{ JAVA_DIR }}; fi"
- name: 拷贝环境变量java_PATH
template: src=java_PATH dest={{ SOURCE_DIR }} owner=root group=root
- name: 加入java_PATH到~/.bashrc
shell: "if [ `grep {{ JAVA_DIR }} ~/.bashrc |wc -l` -eq 0 ]; then cat {{ SOURCE_DIR }}/java_PATH >> ~/.bashrc && source ~/.bashrc; fi"
- name: 加入java_PATH到/etc/profile
shell: "if [ `grep {{ JAVA_DIR }} /etc/profile |wc -l` -eq 0 ]; then cat {{ SOURCE_DIR }}/java_PATH >> /etc/profile && source /etc/profile; fi"
- 引用文件main.yml:
# vim roles/java_install/tasks/main.yml
#引用prepare、copy模块
- include: prepare.yml
- include: copy.yml
elasticsearch部分
- 创建elasticsearch入口文件,用来调用elasticsearch_install:
# vim elasticsearch.yml
#用于批量安装Elasticsearch
- hosts: elasticsearch
remote_user: root
gather_facts: True
roles:
- elasticsearch_install
- 创建变量:
# vim roles/elasticsearch_install/vars/main.yml
#定义elasticsearch安装中的变量
ES_VER: 6.7.1
DOWNLOAD_URL: https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-{{ ES_VER }}.tar.gz
SOURCE_DIR: /software
JAVA_DIR: /usr/local/jdk
ELFK_USER: elk
ELFK_DIR: /home/elfk
ES_CLUSTER: elk
ES_PORT: 9200
TCP_PORT: 9300
- 创建模板文件:
配置文件elasticsearch.conf
# vim roles/elasticsearch_install/templates/elasticsearch.conf
cluster.name: {{ ES_CLUSTER }}
node.name: {{ ES_CLUSTER }}-{{ hostvars[inventory_hostname]['ansible_default_ipv4']['address'].split('.')[-1] }}
node.master: true
node.data: true
path.data: {{ ELFK_DIR }}/elasticsearch/data
path.logs: {{ ELFK_DIR }}/elasticsearch/logs
bootstrap.memory_lock: false
network.host: {{ hostvars[inventory_hostname]['ansible_default_ipv4']['address'] }}
http.port: {{ ES_PORT }}
transport.tcp.port: {{ TCP_PORT }}
http.enabled: true
http.cors.enabled: true
http.cors.allow-origin: "*"
服务配置文件elasticsearch
# vim roles/elasticsearch_install/templates/elasticsearch
################################
# Elasticsearch
################################
# Elasticsearch home directory
#ES_HOME=/usr/share/elasticsearch
ES_HOME={{ ELFK_DIR }}/elasticsearch
# Elasticsearch Java path
#JAVA_HOME=
JAVA_HOME={{ JAVA_DIR }}
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib
# Elasticsearch configuration directory
#ES_PATH_CONF=/etc/elasticsearch
ES_PATH_CONF={{ ELFK_DIR }}/elasticsearch/config
# Elasticsearch PID directory
#PID_DIR=/var/run/elasticsearch
PID_DIR={{ ELFK_DIR }}/elasticsearch/run
# Additional Java OPTS
#ES_JAVA_OPTS=
# Configure restart on package upgrade (true, every other setting will lead to not restarting)
#RESTART_ON_UPGRADE=true
################################
# Elasticsearch service
################################
# SysV init.d
#
# The number of seconds to wait before checking if Elasticsearch started successfully as a daemon process
ES_STARTUP_SLEEP_TIME=5
################################
# System properties
################################
# Specifies the maximum file descriptor number that can be opened by this process
# When using Systemd, this setting is ignored and the LimitNOFILE defined in
# /usr/lib/systemd/system/elasticsearch.service takes precedence
#MAX_OPEN_FILES=65535
# The maximum number of bytes of memory that may be locked into RAM
# Set to "unlimited" if you use the 'bootstrap.memory_lock: true' option
# in elasticsearch.yml.
# When using systemd, LimitMEMLOCK must be set in a unit file such as
# /etc/systemd/system/elasticsearch.service.d/override.conf.
#MAX_LOCKED_MEMORY=unlimited
# Maximum number of VMA (Virtual Memory Areas) a process can own
# When using Systemd, this setting is ignored and the 'vm.max_map_count'
# property is set at boot time in /usr/lib/sysctl.d/elasticsearch.conf
#MAX_MAP_COUNT=262144
服务文件elasticsearch.service
# vim roles/elasticsearch_install/templates/elasticsearch.service
[Unit]
Description=Elasticsearch
Documentation=http://www.elastic.co
Wants=network-online.target
After=network-online.target
[Service]
RuntimeDirectory=elasticsearch
PrivateTmp=true
Environment=ES_HOME={{ ELFK_DIR }}/elasticsearch
Environment=ES_PATH_CONF={{ ELFK_DIR }}/elasticsearch/config
Environment=PID_DIR={{ ELFK_DIR }}/elasticsearch/run
EnvironmentFile=-/etc/sysconfig/elasticsearch
WorkingDirectory={{ ELFK_DIR }}/elasticsearch
User={{ ELFK_USER }}
Group={{ ELFK_USER }}
ExecStart={{ ELFK_DIR }}/elasticsearch/bin/elasticsearch -p ${PID_DIR}/elasticsearch.pid --quiet
# StandardOutput is configured to redirect to journalctl since
# some error messages may be logged in standard output before
# elasticsearch logging system is initialized. Elasticsearch
# stores its logs in /var/log/elasticsearch and does not use
# journalctl by default. If you also want to enable journalctl
# logging, you can simply remove the "quiet" option from ExecStart.
StandardOutput=journal
StandardError=inherit
# Specifies the maximum file descriptor number that can be opened by this process
LimitNOFILE=65535
# Specifies the maximum number of processes
LimitNPROC=4096
# Specifies the maximum size of virtual memory
LimitAS=infinity
# Specifies the maximum file size
LimitFSIZE=infinity
# Disable timeout logic and wait until process is stopped
TimeoutStopSec=0
# SIGTERM signal is used to stop the Java process
KillSignal=SIGTERM
# Send the signal only to the JVM rather than its control group
KillMode=process
# Java process is never killed
SendSIGKILL=no
# When a JVM receives a SIGTERM signal it exits with code 143
SuccessExitStatus=143
[Install]
WantedBy=multi-user.target
# Built for packages-6.7.1 (packages)
- 文件拷贝copy.yml:
# vim roles/elasticsearch_install/tasks/copy.yml
- name: 创建elk用户组
group: name={{ ELFK_USER }} state=present
- name: 创建elk用户
user: name={{ ELFK_USER }} group={{ ELFK_USER }} state=present create_home=False shell=/sbin/nologin
- name: 创建software目录
file: name={{ SOURCE_DIR }} state=directory recurse=yes
- name: 创建elfk目录
file: name={{ ELFK_DIR }} state=directory recurse=yes
ignore_errors: yes
#当前主机files目录下没有elasticsearch包
#- name: 下载elasticsearch包
# get_url: url={{ DOWNLOAD_URL }} dest={{ SOURCE_DIR }}
#当前主机files目录下已有elasticsearch包
- name: 拷贝现有elasticsearch包到目标主机
copy: src=elasticsearch-{{ ES_VER }}.tar.gz dest={{ SOURCE_DIR }}
- name: 解压elasticsearch包
shell: "tar zxf elasticsearch-{{ ES_VER }}.tar.gz"
args:
chdir: "{{ SOURCE_DIR }}"
warn: False
- name: 目录重命名
shell: "if [ ! -d {{ ELFK_DIR }}/elasticsearch ]; then mv {{ SOURCE_DIR }}/elasticsearch-{{ ES_VER }}/ {{ ELFK_DIR }}/elasticsearch; fi"
- name: 创建数据、pid目录
file: name={{ item }} state=directory recurse=yes
with_items:
- "{{ ELFK_DIR }}/elasticsearch/data"
- "{{ ELFK_DIR }}/elasticsearch/run"
- name: 创建pid文件
file: name={{ item }} state=touch
with_items:
- "{{ ELFK_DIR }}/elasticsearch/run/elasticsearch.pid"
- name: 拷贝配置文件
template: src=elasticsearch.conf dest={{ SOURCE_DIR }} owner=root group=root
- name: 配置elasticsearch
shell: "if [ `grep 'http.port' elasticsearch.yml |wc -l` -eq 1 ]; then cat {{ SOURCE_DIR }}/elasticsearch.conf >> elasticsearch.yml; fi"
args:
chdir: "{{ ELFK_DIR }}/elasticsearch/config"
- name: 拷贝服务配置文件
template: src=elasticsearch dest=/etc/sysconfig/elasticsearch owner=root group=root
- name: 拷贝服务文件
template: src=elasticsearch.service dest=/usr/lib/systemd/system/elasticsearch.service mode=0755 owner=root group=root
- name: 修改属主属组
file: name={{ ELFK_DIR }}/elasticsearch/ state=directory owner={{ ELFK_USER }} group={{ ELFK_USER }} recurse=yes
- name: 启动elasticsearch并开机启动
service:
name: elasticsearch
state: started
enabled: yes
- 引用文件main.yml:
# vim roles/elasticsearch_install/tasks/main.yml
#引用copy模块
- include: copy.yml
logstash部分
- 创建logstash入口文件,用来调用logstash_install:
# vim logstash.yml
#用于批量安装Logstash
- hosts: logstash
remote_user: root
gather_facts: True
roles:
- logstash_install
- 创建变量:
# vim roles/logstash_install/vars/main.yml
#定义logstash安装中的变量
LOGSTASH_VER: 6.7.1
DOWNLOAD_URL: https://artifacts.elastic.co/downloads/logstash/logstash-{{ LOGSTASH_VER }}.tar.gz
SOURCE_DIR: /software
ELFK_USER: elk
ELFK_DIR: /home/elfk
JAVA_DIR: /usr/local/jdk
LOGSTASH_PORT: 5050
ES1_IP: 192.168.30.128
ES2_IP: 192.168.30.129
ES3_IP: 192.168.30.130
ES_PORT: 9200
- 创建模板文件:
配置文件logstash.conf
# vim roles/logstash_install/templates/logstash.conf
input {
beats {
port => {{ LOGSTASH_PORT }}
}
}
output {
elasticsearch {
hosts => ["{{ ES1_IP }}:{{ ES_PORT }}", "{{ ES2_IP }}:{{ ES_PORT }}", "{{ ES3_IP }}:{{ ES_PORT }}"]
index => "sys_log"
}
}
服务配置文件logstash
# vim roles/logstash_install/templates/logstash
JAVA_HOME="{{ JAVA_DIR }}"
LS_HOME="{{ ELFK_DIR }}/logstash"
LS_SETTINGS_DIR="{{ ELFK_DIR }}/logstash"
LS_PIDFILE="{{ ELFK_DIR }}/logstash/run/logstash.pid"
LS_USER="{{ ELFK_USER }}"
LS_GROUP="{{ ELFK_USER }}"
LS_GC_LOG_FILE="{{ ELFK_DIR }}/logstash/logs/gc.log"
LS_OPEN_FILES="16384"
LS_NICE="19"
SERVICE_NAME="logstash"
SERVICE_DESCRIPTION="logstash"
服务文件logstash.service
# vim roles/logstash_install/templates/logstash.service
[Unit]
Description=logstash
[Service]
Type=simple
User={{ ELFK_USER }}
Group={{ ELFK_USER }}
# Load env vars from /etc/default/ and /etc/sysconfig/ if they exist.
# Prefixing the path with '-' makes it try to load, but if the file doesn't
# exist, it continues onward.
EnvironmentFile=-/etc/default/logstash
EnvironmentFile=-/etc/sysconfig/logstash
ExecStart={{ ELFK_DIR }}/logstash/bin/logstash "--path.settings" "{{ ELFK_DIR }}/logstash/config" "--path.config" "{{ ELFK_DIR }}/logstash/conf.d"
Restart=always
WorkingDirectory=/
Nice=19
LimitNOFILE=16384
[Install]
WantedBy=multi-user.target
- 文件拷贝copy.yml:
# vim roles/logstash_install/tasks/copy.yml
- name: 创建elk用户组
group: name={{ ELFK_USER }} state=present
- name: 创建elk用户
user: name={{ ELFK_USER }} group={{ ELFK_USER }} state=present create_home=False shell=/sbin/nologin
- name: 创建software目录
file: name={{ SOURCE_DIR }} state=directory recurse=yes
- name: 创建elfk目录
file: name={{ ELFK_DIR }} state=directory recurse=yes
ignore_errors: yes
#当前主机files目录下没有logstash包
#- name: 下载logstash包
# get_url: url={{ DOWNLOAD_URL }} dest={{ SOURCE_DIR }}
#当前主机files目录下已有logstash包
- name: 拷贝现有logstash包到目标主机
copy: src=logstash-{{ LOGSTASH_VER }}.tar.gz dest={{ SOURCE_DIR }}
- name: 解压logstash包
shell: "tar zxf logstash-{{ LOGSTASH_VER }}.tar.gz"
args:
chdir: "{{ SOURCE_DIR }}"
warn: False
- name: 目录重命名
shell: "if [ ! -d {{ ELFK_DIR }}/logstash ]; then mv {{ SOURCE_DIR }}/logstash-{{ LOGSTASH_VER }}/ {{ ELFK_DIR }}/logstash; fi"
- name: 创建配置、日志目录
file: name={{ item }} state=directory recurse=yes
with_items:
- "{{ ELFK_DIR }}/logstash/conf.d"
- "{{ ELFK_DIR }}/logstash/run"
- "{{ ELFK_DIR }}/logstash/logs"
- name: 创建pid、日志文件
file: name={{ item }} state=touch
with_items:
- "{{ ELFK_DIR }}/logstash/run/logstash.pid"
- "{{ ELFK_DIR }}/logstash/logs/gc.log"
- name: 配置logstash
template: src=logstash.conf dest={{ ELFK_DIR }}/logstash/conf.d/logstash.conf
- name: 拷贝服务配置文件
template: src=logstash dest=/etc/default/logstash owner=root group=root
- name: 拷贝服务文件
template: src=logstash.service dest=/etc/systemd/system/logstash.service owner=root group=root
- name: 修改属主属组
file: name={{ ELFK_DIR }}/logstash/ state=directory owner={{ ELFK_USER }} group={{ ELFK_USER }} recurse=yes
- name: 启动logstash并开机启动
service:
name: logstash
state: started
enabled: yes
- 引用文件main.yml:
# vim roles/logstash_install/tasks/main.yml
#引用copy模块
- include: copy.yml
filebeat部分
- 创建filebeat入口文件,用来调用filebeat_install:
# vim filebeat.yml
#用于批量安装Filebeat
- hosts: filebeat
remote_user: root
gather_facts: True
roles:
- filebeat_install
- 创建变量:
# vim roles/filebeat_install/vars/main.yml
#定义filebeat安装中的变量
FILEBEAT_VER: 6.7.1
DOWNLOAD_URL: https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-{{ FILEBEAT_VER }}-linux-x86_64.tar.gz
SOURCE_DIR: /software
ELFK_DIR: /home/elfk
LOGSTASH_PORT: 5050
LOG1_IP: 192.168.30.131
LOG2_IP: 192.168.30.132
LOG3_IP: 192.168.30.133
- 创建模板文件:
服务文件filebeat.service
# vim roles/filebeat_install/templates/filebeat.service
[Unit]
Description=Filebeat sends log files to Logstash or directly to Elasticsearch.
Documentation=https://www.elastic.co/products/beats/filebeat
Wants=network-online.target
After=network-online.target
[Service]
ExecStart={{ ELFK_DIR }}/filebeat/filebeat -c {{ ELFK_DIR }}/filebeat/filebeat.yml -path.home {{ ELFK_DIR }}/filebeat -path.config {{ ELFK_DIR }}/filebeat -path.data {{ ELFK_DIR }}/filebeat/data -path.logs {{ ELFK_DIR }}/filebeat/logs
Restart=always
[Install]
WantedBy=multi-user.target
- 环境准备prepare.yml:
# vim roles/filebeat_install/tasks/prepare.yml
- name: 关闭firewalld
service: name=firewalld state=stopped enabled=no
- name: 临时关闭 selinux
shell: "setenforce 0"
failed_when: false
- name: 永久关闭 selinux
lineinfile:
dest: /etc/selinux/config
regexp: "^SELINUX="
line: "SELINUX=disabled"
- name: 添加EPEL仓库
yum: name=epel-release state=latest
- name: 安装常用软件包
yum:
name:
- vim
- lrzsz
- net-tools
- wget
- curl
- bash-completion
- rsync
- gcc
- unzip
- git
state: latest
- name: 更新系统
shell: "yum update -y"
ignore_errors: yes
args:
warn: False
- 文件拷贝copy.yml:
# vim roles/filebeat_install/tasks/copy.yml
- name: 创建software目录
file: name={{ SOURCE_DIR }} state=directory recurse=yes
- name: 创建elfk目录
file: name={{ ELFK_DIR }} state=directory recurse=yes
ignore_errors: yes
#当前主机files目录下没有filebeat包
#- name: 下载filebeat包
# get_url: url={{ DOWNLOAD_URL }} dest={{ SOURCE_DIR }}
#当前主机files目录下已有filebeat包
- name: 拷贝现有filebeat包到目标主机
copy: src=filebeat-{{ FILEBEAT_VER }}-linux-x86_64.tar.gz dest={{ SOURCE_DIR }}
- name: 解压filebeat包
shell: "tar zxf filebeat-{{ FILEBEAT_VER }}-linux-x86_64.tar.gz"
args:
chdir: "{{ SOURCE_DIR }}"
warn: False
- name: 目录重命名
shell: "if [ ! -d {{ ELFK_DIR }}/filebeat ]; then mv {{ SOURCE_DIR }}/filebeat-{{ FILEBEAT_VER }}-linux-x86_64/ {{ ELFK_DIR }}/filebeat; fi"
- name: 创建数据、日志目录
file: name={{ item }} state=directory
with_items:
- "{{ ELFK_DIR }}/filebeat/data"
- "{{ ELFK_DIR }}/filebeat/logs"
- name: 配置filebeat1
lineinfile:
dest: "{{ ELFK_DIR }}/filebeat/filebeat.yml"
regexp: " enabled: false"
insertbefore: "# Paths that should be crawled and fetched. Glob based paths."
line: " enabled: true"
- name: 配置filebeat2
lineinfile:
dest: "{{ ELFK_DIR }}/filebeat/filebeat.yml"
regexp: "output.elasticsearch:"
insertbefore: "# Array of hosts to connect to."
line: "#output.elasticsearch:"
- name: 配置filebeat3
lineinfile:
dest: "{{ ELFK_DIR }}/filebeat/filebeat.yml"
regexp: 'hosts: \["localhost:9200"\]'
insertbefore: "# Enabled ilm (beta) to use index lifecycle management instead daily indices."
line: '#hosts: ["localhost:9200"]'
- name: 配置filebeat4
lineinfile:
dest: "{{ ELFK_DIR }}/filebeat/filebeat.yml"
regexp: "#output.logstash:"
insertbefore: "# The Logstash hosts"
line: "output.logstash:"
- name: 配置filebeat5
lineinfile:
dest: "{{ ELFK_DIR }}/filebeat/filebeat.yml"
insertafter: "# The Logstash hosts"
line: ' hosts: ["{{ LOG1_IP }}:{{ LOGSTASH_PORT }}", "{{ LOG2_IP }}:{{ LOGSTASH_PORT }}", "{{ LOG2_IP }}:{{ LOGSTASH_PORT }}"]'
- name: 拷贝服务文件
template: src=filebeat.service dest=/usr/lib/systemd/system/filebeat.service owner=root group=root
- name: 启动filebeat并开机启动
service:
name: filebeat
state: started
enabled: yes
- 引用文件main.yml:
# vim roles/filebeat_install/tasks/main.yml
#引用prepare、copy模块
- include: prepare.yml
- include: copy.yml
kibana部分
- 创建kibana入口文件,用来调用kibana_install:
# vim kibana.yml
#用于批量安装Kibana
- hosts: kibana
remote_user: root
gather_facts: True
roles:
- kibana_install
- 创建变量:
# vim roles/kibana_install/vars/main.yml
#定义kibana安装中的变量
KIBANA_VER: 6.7.1
KIBANA_PORT: 5601
DOWNLOAD_URL: https://artifacts.elastic.co/downloads/kibana/kibana-{{ KIBANA_VER }}-linux-x86_64.tar.gz
CH_URL: https://github.com/anbai-inc/Kibana_Hanization/archive/master.zip
SOURCE_DIR: /software
ELFK_USER: elk
ELFK_DIR: /home/elfk
ES_PORT: 9200
ES1_IP: 192.168.30.128
ES2_IP: 192.168.30.129
ES3_IP: 192.168.30.130
- 创建模板文件:
配置文件kibana.conf
# vim roles/kibana_install/templates/kibana.conf
server.port: {{ KIBANA_PORT }}
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://{{ ES1_IP }}:{{ ES_PORT }}", "http://{{ ES2_IP }}:{{ ES_PORT }}", "http://{{ ES3_IP }}:{{ ES_PORT }}"]
logging.dest: {{ ELFK_DIR }}/kibana/logs/kibana.log
kibana.index: ".kibana"
服务配置文件kibana
# vim roles/kibana_install/templates/kibana
user="{{ ELFK_USER }}"
group="{{ ELFK_USER }}"
chroot="/"
chdir="/"
nice=""
# If this is set to 1, then when `stop` is called, if the process has
# not exited within a reasonable time, SIGKILL will be sent next.
# The default behavior is to simply log a message "program stop failed; still running"
KILL_ON_STOP_TIMEOUT=0
服务文件kibana.service
# vim roles/kibana_install/templates/kibana.service
[Unit]
Description=Kibana
StartLimitIntervalSec=30
StartLimitBurst=3
[Service]
Type=simple
User={{ ELFK_USER }}
Group={{ ELFK_USER }}
# Load env vars from /etc/default/ and /etc/sysconfig/ if they exist.
# Prefixing the path with '-' makes it try to load, but if the file doesn't
# exist, it continues onward.
EnvironmentFile=-/etc/default/kibana
EnvironmentFile=-/etc/sysconfig/kibana
ExecStart={{ ELFK_DIR }}/kibana/bin/kibana "-c {{ ELFK_DIR }}/kibana/config/kibana.yml"
Restart=always
WorkingDirectory=/
[Install]
WantedBy=multi-user.target
- 环境准备prepare.yml:
# vim roles/kibana_install/tasks/prepare.yml
- name: 关闭firewalld
service: name=firewalld state=stopped enabled=no
- name: 临时关闭 selinux
shell: "setenforce 0"
failed_when: false
- name: 永久关闭 selinux
lineinfile:
dest: /etc/selinux/config
regexp: "^SELINUX="
line: "SELINUX=disabled"
- name: 添加EPEL仓库
yum: name=epel-release state=latest
- name: 安装常用软件包
yum:
name:
- vim
- lrzsz
- net-tools
- wget
- curl
- bash-completion
- rsync
- gcc
- unzip
- git
state: latest
- name: 更新系统
shell: "yum update -y"
ignore_errors: yes
args:
warn: False
- 文件拷贝copy.yml:
# vim roles/kibana_install/tasks/copy.yml
- name: 创建elk用户组
group: name={{ ELFK_USER }} state=present
- name: 创建elk用户
user: name={{ ELFK_USER }} group={{ ELFK_USER }} state=present create_home=False shell=/sbin/nologin
- name: 创建software目录
file: name={{ SOURCE_DIR }} state=directory recurse=yes
- name: 创建elfk目录
file: name={{ ELFK_DIR }} state=directory recurse=yes
ignore_errors: yes
#当前主机files目录下没有kibana包
#- name: 下载kibana包
# get_url: url={{ DOWNLOAD_URL }} dest={{ SOURCE_DIR }}
#当前主机files目录下已有kibana包
- name: 拷贝现有kibana包到目标主机
copy: src=kibana-{{ KIBANA_VER }}-linux-x86_64.tar.gz dest={{ SOURCE_DIR }}
- name: 解压kibana包
shell: "tar zxf kibana-{{ KIBANA_VER }}-linux-x86_64.tar.gz"
args:
chdir: "{{ SOURCE_DIR }}"
warn: False
- name: 目录重命名
shell: "if [ ! -d {{ ELFK_DIR }}/kibana ]; then mv {{ SOURCE_DIR }}/kibana-{{ KIBANA_VER }}-linux-x86_64/ {{ ELFK_DIR }}/kibana; fi"
- name: 创建日志目录
file: name={{ item }} state=directory recurse=yes
with_items:
- "{{ ELFK_DIR }}/kibana/logs"
- name: 拷贝配置文件
template: src=kibana.conf dest={{ SOURCE_DIR }} owner=root group=root
- name: 配置kibana
shell: "if [ `grep 'server.port' kibana.yml |wc -l` -eq 1 ]; then cat {{ SOURCE_DIR }}/kibana.conf >> kibana.yml; fi"
args:
chdir: "{{ ELFK_DIR }}/kibana/config"
- name: 创建日志文件
file: name={{ item }} state=touch
with_items:
- "{{ ELFK_DIR }}/kibana/logs/kibana.log"
- name: 拷贝服务配置文件
template: src=kibana dest=/etc/default/kibana owner=root group=root
- name: 拷贝服务文件
template: src=kibana.service dest=/etc/systemd/system/kibana.service owner=root group=root
- name: 修改属主属组
file: name={{ ELFK_DIR }}/kibana/ state=directory owner={{ ELFK_USER }} group={{ ELFK_USER }} recurse=yes
- name: 启动kibana并开机启动
service:
name: kibana
state: started
enabled: yes
- kibana汉化chinesization.yml:
# vim roles/kibana_install/tasks/chinesization.yml
#当前主机files目录下没有汉化包
#- name: 下载kibana汉化包
# get_url: url={{ CH_URL }} dest={{ SOURCE_DIR }}
#当前主机files目录下已有汉化包
- name: 拷贝现有node包到所有主机
copy: src=Kibana_Hanization-master.zip dest={{ SOURCE_DIR }}
- name: 解压汉化包
shell: "if [ ! -d Kibana_Hanization-master ]; then unzip Kibana_Hanization-master.zip; fi"
args:
chdir: "{{ SOURCE_DIR }}"
warn: False
- name: 拷贝汉化包
shell: "if [ ! -d {{ ELFK_DIR }}/kibana/src/legacy/core_plugins/kibana/translations ]; then cp -r {{ SOURCE_DIR }}/Kibana_Hanization-master/translations/ {{ ELFK_DIR }}/kibana/src/legacy/core_plugins/kibana/; fi"
- name: 修改kibana配置
lineinfile:
dest: "{{ ELFK_DIR }}/kibana/config/kibana.yml"
insertbefore: "server.port: {{ KIBANA_PORT }}"
line: 'i18n.locale: "zh_CN"'
- name: 修改属主属组
file: name={{ ELFK_DIR }}/kibana/ state=directory owner={{ ELFK_USER }} group={{ ELFK_USER }} recurse=yes
- name: 重启kibana
service:
name: kibana
state: restarted
- 引用文件main.yml:
# vim roles/kibana_install/tasks/main.yml
#引用prepare、copy、chinesization模块
- include: prepare.yml
- include: copy.yml
- include: chinesization.yml
head部分
- 创建head入口文件,用来调用head_install:
# vim head.yml
#用于批量安装Head
- hosts: kibana
remote_user: root
gather_facts: True
roles:
- head_install
- 创建变量:
# vim roles/head_install/vars/main.yml
#定义head安装中的变量
NODE_VER: 10.16.3
NODE_URL: https://nodejs.org/dist/v{{ NODE_VER }}/node-v{{ NODE_VER }}-linux-x64.tar.xz
HEAD_URL: https://github.com/mobz/elasticsearch-head/archive/master.zip
SOURCE_DIR: /software
ELFK_DIR: /home/elfk
- 创建模板文件:
环境变量node_PATH
# vim roles/head_install/templates/node_PATH
export NODE_HOME={{ ELFK_DIR }}/node
export PATH=$NODE_HOME/bin:$PATH
export NODE_PATH=$NODE_HOME/lib/node_modules:$PATH
启动脚本elasticsearch-head
# vim roles/head_install/templates/elasticsearch-head
#!/bin/bash
#chkconfig: 2345 55 24
#description: elasticsearch-head service manager
data="cd {{ ELFK_DIR }}/head/; nohup npm run start &>/dev/null &"
START() {
eval $data
}
STOP() {
ps -ef | grep grunt | grep -v "grep" | awk '{print $2}' | xargs kill -s 9 &>/dev/null
}
case "$1" in
start)
START
;;
stop)
STOP
;;
restart)
STOP
sleep 2
START
;;
*)
echo "Usage: elasticsearch-head (|start|stop|restart)"
;;
esac
- 文件拷贝copy.yml:
# vim roles/head_install/tasks/copy.yml
- name: 创建software目录
file: name={{ SOURCE_DIR }} state=directory recurse=yes
- name: 创建elfk目录
file: name={{ ELFK_DIR }} state=directory recurse=yes
ignore_errors: yes
#当前主机files目录下没有node包
- name: 下载node包
get_url: url={{ NODE_URL }} dest={{ SOURCE_DIR }} owner=root group=root
#当前主机files目录下已有node包
#- name: 拷贝现有node包到所有主机
# copy: src=node-v{{ NODE_VER }}-linux-x64.tar.xz dest={{ SOURCE_DIR }} owner=root group=root
- name: 解压node包
shell: "tar Jxf node-v{{ NODE_VER }}-linux-x64.tar.xz"
args:
chdir: "{{ SOURCE_DIR }}"
warn: False
- name: 目录重命名
shell: "if [ ! -d {{ ELFK_DIR }}/node ]; then mv {{ SOURCE_DIR }}/node-v{{ NODE_VER }}-linux-x64/ {{ ELFK_DIR }}/node; fi"
- name: 拷贝环境变量node_PATH
template: src=node_PATH dest={{ SOURCE_DIR }} owner=root group=root
- name: 加入node_PATH到~/.bashrc
shell: "if [ `grep {{ ELFK_DIR }}/node ~/.bashrc |wc -l` -eq 0 ]; then cat {{ SOURCE_DIR }}/node_PATH >> ~/.bashrc && source ~/.bashrc; fi"
- name: 加入node_PATH到/etc/profile
shell: "if [ `grep {{ ELFK_DIR }}/node /etc/profile |wc -l` -eq 0 ]; then cat {{ SOURCE_DIR }}/node_PATH >> /etc/profile && source /etc/profile; fi"
- 安装install.yml:
# vim roles/head_install/tasks/install.yml
#当前主机files目录下没有head包
- name: 下载head包
get_url: url={{ HEAD_URL }} dest={{ SOURCE_DIR }} owner=root group=root
#当前主机files目录下已有head包
#- name: 拷贝现有head包到所有主机
# copy: src=elasticsearch-head-master.zip dest={{ SOURCE_DIR }} owner=root group=root
- name: 拷贝脚本到所有主机
template: src=elasticsearch-head dest={{ SOURCE_DIR }} mode=0755 owner=root group=root
- name: 解压node包
shell: "if [ ! -d elasticsearch-head-master/ ]; then unzip elasticsearch-head-master.zip; fi"
args:
chdir: "{{ SOURCE_DIR }}"
warn: False
- name: 目录重命名
shell: "if [ ! -d {{ ELFK_DIR }}/head ]; then mv {{ SOURCE_DIR }}/elasticsearch-head-master/ {{ ELFK_DIR }}/head; fi"
- name: 安装grunt 1
shell: npm install -g cnpm --registry=https://registry.npm.taobao.org
args:
chdir: "{{ ELFK_DIR }}/head"
- name: 安装grunt 2
shell: cnpm install -g grunt-cli
args:
chdir: "{{ ELFK_DIR }}/head"
- name: 安装grunt 3
shell: cnpm install -g grunt
args:
chdir: "{{ ELFK_DIR }}/head"
- name: 安装grunt 4
shell: cnpm install grunt-contrib-clean
args:
chdir: "{{ ELFK_DIR }}/head"
- name: 安装grunt 5
shell: cnpm install grunt-contrib-concat
args:
chdir: "{{ ELFK_DIR }}/head"
- name: 安装grunt 6
shell: cnpm install grunt-contrib-watch
args:
chdir: "{{ ELFK_DIR }}/head"
- name: 安装grunt 7
shell: cnpm install grunt-contrib-connect
args:
chdir: "{{ ELFK_DIR }}/head"
- name: 安装grunt 8
shell: cnpm install grunt-contrib-copy
args:
chdir: "{{ ELFK_DIR }}/head"
- name: 安装grunt 9
shell: cnpm install grunt-contrib-jasmine
args:
chdir: "{{ ELFK_DIR }}/head"
ignore_errors: yes
#上一步一般会报错,重复上一步安装
- name: 安装grunt 10
shell: cnpm install grunt-contrib-jasmine
args:
chdir: "{{ ELFK_DIR }}/head"
- name: 添加脚本elasticsearch-head
shell: "if [ ! -f /usr/bin/elasticsearch-head ]; then mv {{ SOURCE_DIR }}/elasticsearch-head /usr/bin/elasticsearch-head; fi"
- name: 配置head
lineinfile:
dest: "{{ ELFK_DIR }}/head/Gruntfile.js"
insertbefore: "port: 9100,"
line: " hostname: '0.0.0.0',"
- name: 启动elasticsearch-head
shell: "if [ `netstat -lntp |grep 9100 | wc -l` -eq 0 ]; then source ~/.bashrc && /usr/bin/elasticsearch-head start; fi"
- 引用文件main.yml:
# vim roles/head_install/tasks/main.yml
#引用copy、install模块
- include: copy.yml
- include: install.yml
nginx部分
- 创建nginx入口文件,用来调用nginx_install:
# vim nginx.yml
#用于批量安装Nginx
- hosts: kibana
remote_user: root
gather_facts: True
roles:
- nginx_install
- 创建变量:
# vim roles/nginx_install/vars/main.yml
#定义nginx安装中的变量
NGINX_VER: 1.17.2
DOWNLOAD_URL: http://nginx.org/download/nginx-{{ NGINX_VER }}.tar.gz
NGINX_USER: nginx
NGINX_PORT: 80
KIBANA_PORT: 5601
SOURCE_DIR: /software
NGINX_DIR: /usr/local/nginx
DOMAIN: kibana.lzxlinux.com
- 创建模板文件:
nginx主配置文件nginx.conf
# vim roles/nginx_install/templates/nginx.conf
user nobody nobody;
worker_processes 1;
error_log logs/error.log notice;
pid logs/nginx.pid;
worker_rlimit_nofile 65535;
events {
use epoll;
worker_connections 1024;
multi_accept on;
}
http {
include mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log logs/access.log main;
server_tokens off;
sendfile on;
send_timeout 3m;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
client_header_timeout 3m;
client_body_timeout 3m;
connection_pool_size 256;
client_header_buffer_size 4k;
large_client_header_buffers 8 4k;
request_pool_size 4k;
output_buffers 4 32k;
postpone_output 1460;
client_max_body_size 10m;
client_body_buffer_size 256k;
client_body_temp_path {{ NGINX_DIR }}/client_body_temp;
proxy_temp_path {{ NGINX_DIR }}/proxy_temp;
fastcgi_temp_path {{ NGINX_DIR }}/fastcgi_temp;
fastcgi_intercept_errors on;
gzip on;
gzip_min_length 2k;
gzip_buffers 4 32k;
gzip_comp_level 6;
gzip_http_version 1.1;
gzip_types text/plain application/x-javascript text/css text/htm
application/xml;
include {{ NGINX_DIR }}/conf/vhost/*.conf;
}
nginx vhost配置文件kibana.conf
# vim roles/nginx_install/templates/kibana.conf
server {
listen 80;
server_name {{ DOMAIN }};
location / {
proxy_pass http://{{ hostvars[inventory_hostname]['ansible_default_ipv4']['address'] }}:{{ KIBANA_PORT }};
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
access_log logs/kibana.log main;
}
nginx额外配置文件fastcgi_params
# vim roles/nginx_install/templates/fastcgi_params
fastcgi_param GATEWAY_INTERFACE CGI/1.1;
fastcgi_param SERVER_SOFTWARE nginx;
fastcgi_param QUERY_STRING $query_string;
fastcgi_param REQUEST_METHOD $request_method;
fastcgi_param CONTENT_TYPE $content_type;
fastcgi_param CONTENT_LENGTH $content_length;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param SCRIPT_NAME $fastcgi_script_name;
fastcgi_param REQUEST_URI $request_uri;
fastcgi_param DOCUMENT_URI $document_uri;
fastcgi_param DOCUMENT_ROOT $document_root;
fastcgi_param SERVER_PROTOCOL $server_protocol;
fastcgi_param REMOTE_ADDR $remote_addr;
fastcgi_param REMOTE_PORT $remote_port;
fastcgi_param SERVER_ADDR $server_addr;
fastcgi_param SERVER_PORT $server_port;
fastcgi_param SERVER_NAME $server_name;
nginx服务文件nginx.service
# vim roles/nginx_install/templates/nginx.service
[Unit]
Description=The nginx HTTP and reverse proxy server
After=network.target remote-fs.target nss-lookup.target
[Service]
Type=forking
PIDFile={{ NGINX_DIR }}/logs/nginx.pid
# Nginx will fail to start if /run/nginx.pid already exists but has the wrong
# SELinux context. This might happen when running `nginx -t` from the cmdline.
# https://bugzilla.redhat.com/show_bug.cgi?id=1268621
ExecStartPre=/usr/bin/rm -f {{ NGINX_DIR }}/logs/nginx.pid
ExecStartPre={{ NGINX_DIR }}/sbin/nginx -t
ExecStart={{ NGINX_DIR }}/sbin/nginx
ExecReload=/bin/kill -s HUP $MAINPID
KillSignal=SIGQUIT
TimeoutStopSec=5
KillMode=process
PrivateTmp=true
[Install]
WantedBy=multi-user.target
- 环境准备prepare.yml:
# vim roles/nginx_install/tasks/prepare.yml
- name: 安装常用软件包
yum:
name:
- openssl
- openssl-devel
- pcre
- pcre-devel
- zlib-devel
- gd-devel
- libxml2-devel
state: latest
- 文件拷贝copy.yml:
# vim roles/nginx_install/tasks/copy.yml
- name: 创建nginx用户组
group: name={{ NGINX_USER }} state=present
- name: 创建nginx用户
user: name={{ NGINX_USER }} group={{ NGINX_USER }} state=present create_home=False shell=/sbin/nologin
- name: 创建software目录
file: name={{ SOURCE_DIR }} state=directory recurse=yes
- name: 创建日志目录
file: name={{ item }} state=directory recurse=yes
with_items:
- "{{ NGINX_DIR }}"
- "{{ NGINX_DIR }}/logs"
- name: 创建日志文件
file: name={{ item }} state=touch
with_items:
- "{{ NGINX_DIR }}/logs/access.log"
- "{{ NGINX_DIR }}/logs/error.log"
#当前主机files目录下没有nginx包
- name: 下载nginx包
get_url: url={{ DOWNLOAD_URL }} dest={{ SOURCE_DIR }}
#当前主机files目录下已有nginx包
#- name: 拷贝现有nginx包到所有主机
# copy: src=nginx-{{ NGINX_VER }}.tar.gz dest={{ SOURCE_DIR }}
- name: 解压nginx包
shell: "tar zxf nginx-{{ NGINX_VER }}.tar.gz"
args:
chdir: "{{ SOURCE_DIR }}"
warn: False
- name: 修改属主属组
file: name={{ NGINX_DIR }} state=directory owner={{ NGINX_USER }} group={{ NGINX_USER }} recurse=yes
- name: 拷贝nginx服务文件
template: src=nginx.service dest=/usr/lib/systemd/system/nginx.service owner=root group=root
- 编译安装install.yml:
# vim roles/nginx_install/tasks/install.yml
- name: 编译nginx
shell: "cd {{ SOURCE_DIR }}/nginx-{{ NGINX_VER }} && ./configure --prefix={{ NGINX_DIR }} --user={{ NGINX_USER }} --group={{ NGINX_USER }} --http-log-path={{ NGINX_DIR }}/logs/access.log --error-log-path={{ NGINX_DIR }}/logs/error.log --with-http_ssl_module --with-http_v2_module --with-http_stub_status_module --with-pcre --with-http_realip_module --with-http_flv_module --with-http_mp4_module --with-http_gunzip_module --with-http_gzip_static_module --with-http_image_filter_module"
- name: 安装nginx
shell: "cd {{ SOURCE_DIR }}/nginx-{{ NGINX_VER }} && make && make install"
- name: 拷贝nginx主配置文件
template: src=nginx.conf dest={{ NGINX_DIR }}/conf/nginx.conf
- name: 创建vhost配置文件目录
file: name={{ NGINX_DIR }}/conf/vhost state=directory recurse=yes
- name: 拷贝nginx vhost配置文件
template: src=kibana.conf dest={{ NGINX_DIR }}/conf/vhost/kibana.conf
- name: 拷贝nginx额外配置文件
template: src=fastcgi_params dest={{ NGINX_DIR }}/conf/fastcgi_params
- name: 配置环境变量
shell: " if [ `grep {{ NGINX_DIR }}/sbin /etc/profile |wc -l` -eq 0 ]; then echo export PATH=$PATH:{{ NGINX_DIR }}/sbin >> /etc/profile && source /etc/profile; else source /etc/profile; fi"
- name: 修改属主属组
file: name={{ NGINX_DIR }} state=directory owner={{ NGINX_USER }} group={{ NGINX_USER }} recurse=yes
- name: 启动nginx并开机启动
service:
name: nginx
state: started
enabled: yes
- 引用文件main.yml:
# vim roles/nginx_install/tasks/main.yml
#引用prepare、copy、install模块
- include: prepare.yml
- include: copy.yml
- include: install.yml
安装测试
- 执行安装:
# ansible-playbook elfk.yml
在Windows电脑hosts文件中添加一行:192.168.30.133 kibana.lzxlinux.com,打开网页访问。
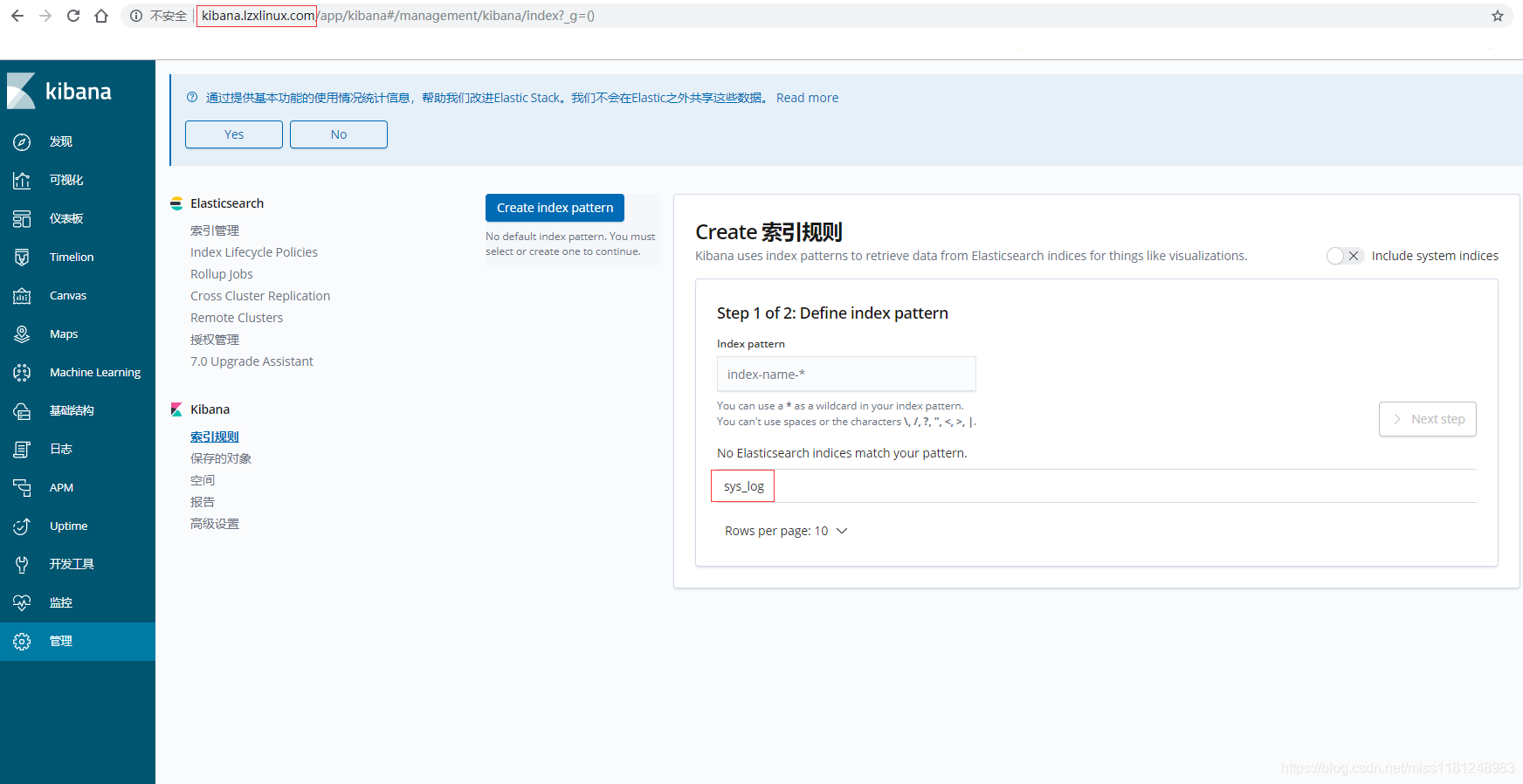
测试安装没有问题,建议安装前在本地准备好各类安装包(尤其是ELFK的安装包),ELFK版本尽量一致。已存放至个人gitgub:ansible-playbook

















 1620
1620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









