







在有向图中寻找社区
1、介绍
现有的社区检索工作可以分为社区检测(CD)和社区搜索(CS)
社区检测主要集中在无向图,简单地忽略边缘的方向,基于链路分析检测社区。
对于社区检测,目前有很多方法,但是存在缺陷。所有这些工作通常会检测整个图中的所有社区,这通常非常耗时,尤其是在大型图上。此外,目前还不清楚它们如何应用于在线社区搜索。为了解决这些问题,最近提出了CS方法,但没有一种是为有向图定制的。
如果我们忽略方向,我们可能会识别出成员相似度低的无意义社区或僵尸用户。
CSD问题:给定有向图G的查询顶点q,以及两个正整数k和l,我们的目标是找到一个包含q的稠密连通子图,其中每个顶点的入度和出度分别至少为k和l。
还引入了CSD问题的一个变体,它对社区用户施加了更强的连接。具体来说,它要求每个社区都是一个强连接组件(SCC)[26]。我们把这个变量叫做SCSD问题。
首先从全局[7]的启发中开发了一个基本算法。然而,它是低效的,特别是在大型图上。为了提高效率,我们引入了Dcore的概念,描述了满足一定入度和出度约束的最大子图[29],提出了一种有效的d -核分解算法。
基于d -core,我们建议将所有d -core组织在一个二维表中。然而,它的空间成本高达
Oðn3Þ,其中n是顶点的总数。为了缓解这一问题,我们进一步提出了三个指标,即NestIdx,
PathIdx和UnionIdx,通过使用一些压缩技术。
基于索引,查询性能可以得到显著提高。
2、相关工作
经典解采用基于链接的分析来获得这些群体。然而,他们没有考虑边缘方向。
关于有向图的CD方法的最新调查可以在[1]中找到。然而,这些CD方法通常很慢,因为它们经常检测整个网络中的所有社区。此外,目前还不清楚它们如何适应在线社区搜索。
在线”地从mg中提取出最有可能包含q的社区。为了度量一个社区的“善度”,人们通常使用最小度度量,返回的子图通常需要满足以下性质:(1)它包含q;(2)连接;(3)每个顶点至少有k个邻居。
良度”指标,如k-clique k-truss 和连通性
3、初期
3.1 问题定义
(u, v) :存在u至v的边,u就做v的内邻居,v叫做u的外邻居。内度: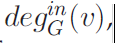 是他的内邻居数。
是他的内邻居数。
外度: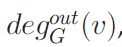 ,表示外邻居数。
,表示外邻居数。
最小内度和最小外度: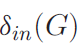
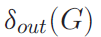
为了度量有向图中群落的内聚性,我们同时考虑了内聚度和外聚度,采用最小度。我们要求图的返回团体中的每个顶点至少有k个内邻居和l个外邻居,其中k和l是两个正整数。
问题1:

返回的是连接图
问题2:
与问题1不同的是返回的一定是强连通图
3.2 d-core
定义2:D-core
属性1:Property 1 (Minimum Size). A (k, l)-core contains at least max{k, l} + 1 vertices, Vkj >=max{l,k} + 1.
属性2: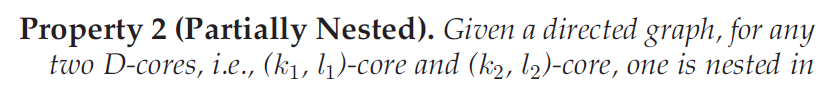
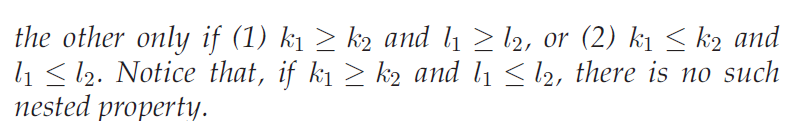
属性3:A D-core may not be connected,it may consist of multiple connected components.
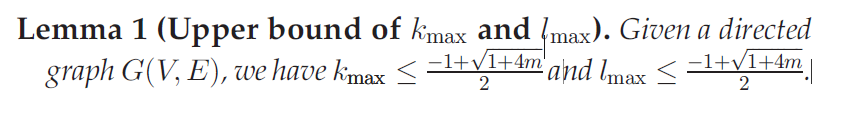
证明:
4、基础算法
DGlobal,因为它在整个有向图上全局工作。
迭代删除度不满足的顶点,得到一个包括查询顶点的联通组件。
SDGlobal,从DGlobal结果中查找强连通组件。
5、d-core分解
D-core decomposition, then organize them into some indexes offline,
提出一种更快的d-core计算方法。我们的算法不是一个一个地计算d核,而是把所有的d核集合起来计算,效率很高。我们以一种集合的方式计算所有具有相同k值的(k, l)核,并引入一些新颖的剪枝技术。而且,如第6节所示,所有的d -core都可以压缩并存储在索引结构中,节省了大量的空间成本
定义三:k-list

表中每一行的所有d核构成一个k表,以线性的时间和空间代价以k列表的方式计算所有的d核。

5.1 计算k-list
表中每一行的所有d -核构成一个k-列表,这个没弄懂

anchor value: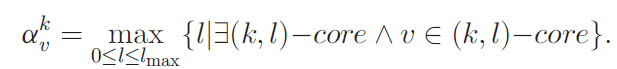
计算k-list
5.2 剪枝算法
这些k的k-列表是完全相同的,这意味着如果它与(k-1)-列表相同,我们不需要计算k-列表。
pruning range:
















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









