







 本文探讨了使用两层和三层神经网络解决线性及非线性分类问题。通过实例展示了BP神经网络如何处理XOR问题,并解释了为什么两层网络无法解决某些非线性问题。解决方案是增加网络层数,如三层神经网络,以更好地拟合复杂函数。
本文探讨了使用两层和三层神经网络解决线性及非线性分类问题。通过实例展示了BP神经网络如何处理XOR问题,并解释了为什么两层网络无法解决某些非线性问题。解决方案是增加网络层数,如三层神经网络,以更好地拟合复杂函数。
一、前言
本文参考了以下几篇文章
1.BP神经网络算法 python实现 BP神经网络算法 python实现 - 人工智能 - 电子发烧友网
2.一个简单神经网络的代码实现一个简单神经网络的代码实现_神童i的博客-CSDN博客
3.深度学习基础之-5.1非线性分类-二分类深度学习基础之-5.1非线性分类-二分类(神经元解决异或问题)_Susan Wong-CSDN博客
本文主要描述解决XoR问题 以及简单的表格内容预测问题
二、两层神经网络实现线性分类问题
1. 采用算法预测下表结果(线性)
| Inputs | Output | ||
| 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 0 |
| 1 | 0 | 1 | 1 |
| 0 | 1 | 1 | 1 |
给定已知表格,尝试输入前三列数据去预测第四列数值,其中行为样本。
Input为输入样本,Output为实际结果值
先叠加两层神经网络,采用sigmod函数对数据进行激活
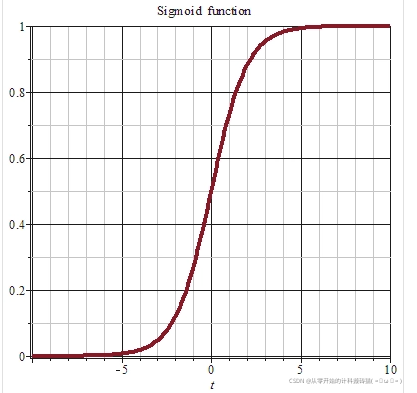
(sigmod函数如图所示)
sigmoid函数可以将任何值都映射到位于0到1范围内的值 ,通过它可以将任何值映射到位于0-1的范围内,可以令我们的实数值转化为概率值。同时sigmod函数的求导值也是很好求得,导数值为 out * (1 - out )得到,十分高效的。
# 两层神经元
import numpy as np
# 激活函数 sigmod 将任何值变为0 - 1概率值
def sigmod(x, deriv = False): # 求导True
if True == deriv:
return x * (1 - x) # sigmod的导数形式
return 1/(1+np.exp(-x))
# 训练数据 初始化为numpy矩阵 每行对应实例 每列代表输入节点
train_data = np.array([
[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]])
y = np.array([[0,0,1,1]]).T # 设计输出
np.random.seed(1) # 权重初始集分布都是完全一致的
weights = np.random.random((3,1)) #权重矩阵w1
#print(weights)
weights = 2 * weights -1 # 随机数进行处理(类似正态分布)
#print(weights)
for iter in range(10000): # 变化数据只有weight l1
l0 = train_data # 训练数据
l1 = sigmod(np.dot(l0,weights)) # 训练数据与三个随机权重相乘 激活 预测值
loss = y - l1 # 错误率
print("loss=",loss)
# l1_delta 是一个变化率选项
l1_delta = loss * sigmod(l1, True) # 求导 - a *(dw/dl1# )
weights += np.dot(l0.T, l1_delta) # 权重进行更新
print("weights=",weights)
print("\n")
print("times=",iter)
print("pre_l1=\n",l1)
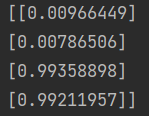
运行10000次后结果如图所示,发现两层神经元可以逼近线性结果。
2. 修改表格为非线性后无法预测
| Inputs | Output | ||
| 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 |
| 0 | 1 | 1 | 0 |
我们对output数值进行修改后发现,预测的数据竟然是0.5(无法判断),原因是此类数据已经属于非线性无法用两层网络进行拟合。
# 两层神经元
import numpy as np
# 激活函数 sigmod 将任何值变为0 - 1概率值
def sigmod(x, deriv = False): # 求导True
if True == deriv:
return x * (1 - x) # sigmod的导数形式
return 1/(1+np.exp(-x))
# 训练数据 初始化为numpy矩阵 每行对应实例 每列代表输入节点
train_data = np.array([
[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]])
y = np.array([[0,1,1,0]]).T # 设计输出
np.random.seed(1) # 权重初始集分布都是完全一致的
weights = np.random.random((3,1)) #权重矩阵w1
#print(weights)
weights = 2 * weights -1 # 随机数进行处理(类似正态分布)
#print(weights)
for iter in range(10000): # 变化数据只有weight l1
l0 = train_data # 训练数据
l1 = sigmod(np.dot(l0,weights)) # 训练数据与三个随机权重相乘 激活 预测值
loss = y - l1 # 错误率
print("loss=",loss)
# l1_delta 是一个变化率选项
l1_delta = loss * sigmod(l1, True) # 求导 - a *(dw/dl1# )
weights += np.dot(l0.T, l1_delta) # 权重进行更新
print("weights=",weights)
print("\n")
print("times=",iter)
print("pre_l1=\n",l1)
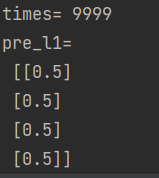
解决方法也很简单,再加一层神经元,可以更近一步拟合出具体函数。
三、三层神经网络实现非线性分类问题
1. 采用算法预测下表结果(非线性)
| Inputs | Output | ||
| 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 |
| 0 | 1 | 1 | 0 |
第二组数据无法预测是因为非线性,关系复杂一些,但多添加一层线性网络就能处理。
import numpy as np
# 第一步设定激活函数sigmod
def sigmod(x, deriv = False): # 求导True
if True == deriv:
return x * (1 - x) # sigmod的导数形式
return 1/(1+np.exp(-x))
train_data = np.array([
[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]])
y= np.array([[0], [1], [1], [0]])
np.random.seed(1)
weights1 = 2 * np.random.random((3, 4)) - 1
weights2 = 2 * np.random.random((4, 1)) - 1
for cnt in range(1000000):
l0 = train_data # [4, 3] 第一层 输入层 l0为我们的训练数据
l1 = sigmod(np.dot(l0, weights1)) # [4, 4]
l2 = sigmod(np.dot(l1, weights2)) # [4, 1]
l2_loss = y - l2 # [4, 1]
l2_delta = l2_loss * sigmod(l2, True)
l1_loss = l2_delta.dot(weights2.T)
l1_delta = l1_loss * sigmod(l1, True)
weights1 += l0.T.dot(l1_delta)
weights2 += l1.T.dot(l2_delta)
acc = ((l2[0] +l2[3]) + ((1-l2[1])+(1-l2[2])))/4
print("cnt=",cnt)
print("acc=",acc)
print(l2)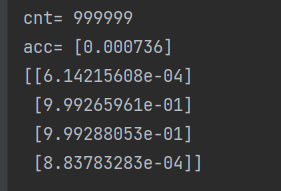
具体结果如上图所示
2. XoR问题的分类讨论
| Inputs | Inputs | Output |
| 0 | 0 | 0 |
| 1 | 1 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
异或,英文为exclusive OR,缩写成eor
异或(eor)是一个数学运算符。它应用于逻辑运算。异或的数学符号为“⊕”,计算机符号为“eor”。其运算法则为:a⊕b = (¬a ∧ b) ∨ (a ∧¬b)
如果a、b两个值不相同,则异或结果为1。如果a、b两个值相同,异或结果为0。
分类的曲线可以理解为下图所示的非线性函数。
编写代码时要注意矩阵对齐,因为XoR分类与之前的表格分类列数上变化一小部分。
import numpy as np
# 第一步设定激活函数sigmod
def sigmod(x, deriv = False): # 求导True
if True == deriv:
return x * (1 - x) # sigmod的导数形式
return 1/(1+np.exp(-x))
train_data = np.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]]) # 与之前相比 输入数据少了一列 预测起来更简单
y = np.array([[0], [1], [1], [0]]) # y为预测值
np.random.seed(1) # 固定随机种子
weights1 = 2 * np.random.random((2, 4)) - 1 # 随机分布w权重
weights2 = 2 * np.random.random((4, 1)) - 1
for cnt in range(1000000):
l0 = train_data # [4, 2] 第一层 输入层 l0为我们的训练数据
l1 = sigmod(np.dot(l0, weights1)) # [4, 4]
l2 = sigmod(np.dot(l1, weights2)) # [4, 1]
l2_loss = y - l2 # [4, 1]
l2_delta = l2_loss * sigmod(l2, True) # 每次权重要变化的大小
l1_loss = l2_delta.dot(weights2.T)
l1_delta = l1_loss * sigmod(l1, True)
weights1 += l0.T.dot(l1_delta) # 权重进行更新
weights2 += l1.T.dot(l2_delta)
acc = ((l2[0] +l2[3]) + ((1-l2[1])+(1-l2[2])))/4 # 预测精准度评定
print("cnt=",cnt) # 计数
print("acc=",acc) # 精度
print(l2)3. 拓展讨论
下一步选择完成4层的神经网络


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









